REINFORCE:方策勾配法入門

AIの初心者
先生、「REINFORCE」ってなんですか?難しそうでよくわからないです。

AI専門家
REINFORCEは、機械学習の中でも特に「強化学習」という分野で使われる大切な考え方だよ。簡単に言うと、試行錯誤を通して、一番いい行動を見つける方法なんだ。 例えば、迷路でゴールを目指すロボットを想像してみて。REINFORCEを使うと、ロボットは何度も迷路に挑戦しながら、ゴールまでの最短ルートを自分で学習していくんだよ。
AIの初心者
なるほど。でも、他の強化学習の方法とは何が違うんですか?
AI専門家
多くの強化学習は、まずそれぞれの行動の「価値」を評価して、一番価値の高い行動を選ぶんだ。でもREINFORCEは違う。行動の「価値」を評価する代わりに、直接的に一番いい行動を見つけ出そうとするんだよ。 例えば、迷路のロボットで考えると、REINFORCEは、過去の成功体験に基づいて、どの道を選ぶかの確率を調整していくんだ。価値を計算するよりも、もっと直感的に学習していくイメージだね。
REINFORCEとは。
人工知能の分野で用いられる「レインフォース」という用語について説明します。レインフォースは、強化学習の一種です。強化学習には、一般的に「価値関数」と呼ばれるものの精度を高めることで学習を進める方法が広く使われていますが、レインフォースはそれとは異なり、直接的に最適な行動方針を見つけ出す手法です。この手法は「方策勾配法」と呼ばれ、レインフォースはこの方策勾配法の中でも最も基本的な方法です。
はじめに

機械学習の世界では、様々な方法で学習を行います。その中で、試行錯誤を通じて学習する手法を強化学習と言います。人間の子供がおもちゃで遊ぶうちに、どのようにすればうまく操作できるかを覚えていく過程に似ています。目的は、長い目で見て最も良い結果が得られる行動の仕方を見つけることです。
この行動の仕方を指針、つまり手順書のようにまとめて「方策」と呼びます。方策には、ある状況でどのような行動をとるべきかが記されています。例えば、迷路で行き止まりに突き当たったら、引き返すという指示が方策に含まれているかもしれません。強化学習では、この方策をより良いものへと改良していくことが重要です。
強化学習を実現するための手順は様々ありますが、その中でも「REINFORCE」は基本的な手法の一つです。REINFORCEは、方策勾配法という種類の学習方法に属します。方策勾配法の特徴は、行動の価値を評価するのではなく、方策そのものを直接的に調整していく点にあります。価値とは、ある行動をとった時にどのくらい良い結果が期待できるかを数値で表したものです。REINFORCEは、価値を介さずに、試行錯誤を通じて得られた結果をもとに、方策を少しずつ修正していくことで、最適な行動を見つけることを目指します。これは、まるで職人が経験を通して技術を磨いていくように、試行錯誤と改善を繰り返すことでより良い方策を学習していくのです。
価値関数と方策勾配法

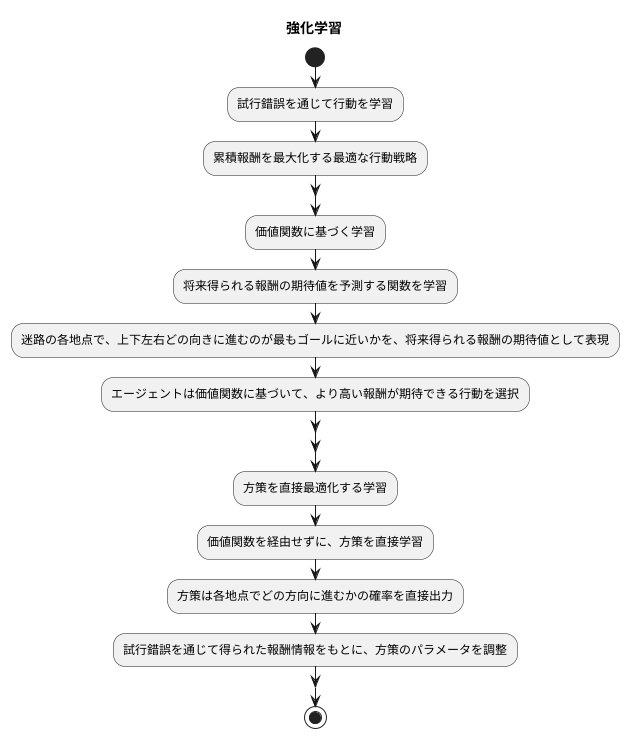
強化学習とは、試行錯誤を通じて行動を学習する枠組みです。目標は、環境と相互作用しながら累積報酬を最大化する最適な行動戦略を見つけることです。この学習には、大きく分けて二つの手法があります。一つは価値関数に基づく学習、もう一つは方策を直接最適化する学習です。
価値関数に基づく学習では、まず将来得られる報酬の期待値を予測する関数、すなわち価値関数を学習します。価値関数は、ある状態において特定の行動をとった場合に、将来どれだけの報酬を得られるかを推定します。この推定値が高い行動ほど、良い行動だと判断できます。例えば、迷路を解く問題を考えてみましょう。価値関数は、迷路の各地点で、上下左右どの向きに進むのが最もゴールに近いかを、将来得られる報酬の期待値として表現します。学習を進める中で、この価値関数はより正確な推定値を出力するように更新されます。そして、エージェントはこの価値関数に基づいて、より高い報酬が期待できる行動を選択し、迷路のゴールを目指します。
一方、方策勾配法は、価値関数を経由せずに、方策を直接学習します。方策とは、ある状態でどのような行動をとるかを決定するルールです。方策勾配法では、この方策をパラメータを持つ関数で表現します。そして、試行錯誤を通じて得られた報酬情報をもとに、方策のパラメータを調整することで最適な行動戦略を学習します。迷路の例で言えば、方策は各地点でどの方向に進むかの確率を直接出力します。報酬が高い行動をとった場合は、その行動をとる確率を高めるようにパラメータを更新し、逆に報酬が低い行動をとった場合は、その行動をとる確率を低くするように更新します。このように、価値関数を推定する過程を省略し、試行錯誤を通じて直接方策を改善していくのが方策勾配法の特徴です。REINFORCEは、このような方策勾配法の代表的なアルゴリズムの一つです。
REINFORCEの仕組み

強化学習における方策勾配法の一つであるREINFORCEは、試行錯誤を通じて学習を進める手法です。まるで迷路を探索するネズミのように、様々な行動を試しながら、より良い結果に繋がる行動を強化していきます。この学習方法は、モンテカルロ法という考え方に基づいています。モンテカルロ法とは、何度も試行を繰り返すことで、全体像を把握していく手法です。REINFORCEでは、まず行動の指針となる方策に従って、開始から終了までの一連の行動を選択します。これをエピソードと呼びます。迷路の例で言えば、入り口から出口までの一連の経路がエピソードに当たります。エピソードの終了後、得られた報酬に基づいて、方策を更新します。報酬とは、目標達成度合いを示す数値です。迷路の例では、出口に到達した場合は高い報酬、出口から遠ざかった場合は低い報酬が与えられます。具体的には、報酬が高いほど、そのエピソードで選択した行動の確率が高くなるように調整します。つまり、出口に辿り着く経路であれば、その経路上の選択が強化されるのです。逆に、出口から遠ざかる経路であれば、その経路上の選択は抑制されます。このように、成功体験を強化し、失敗体験を抑制することで学習を進めます。この更新は、勾配上昇法という手法を用いて行われます。勾配上昇法とは、山の頂上を目指す登山のように、最も急な斜面を登ることで、最大値を効率的に見つける手法です。REINFORCEでは、方策の期待報酬を最大化する方向にパラメータを調整することで、最適な行動戦略を学習します。そのため、この手法は方策勾配法とも呼ばれます。REINFORCEは、試行錯誤を通して学習を進めるため、環境の完全な情報がなくても学習を進めることができます。これは、現実世界の問題を解く上で大きな利点となります。
REINFORCEの利点

強化学習の手法の一つであるREINFORCEは、いくつかの長所を持っています。まず、その仕組みが簡素であるため、プログラムに落とし込むのが容易です。強化学習では、将来の報酬を見積もるために価値関数というものを用いる手法がよく使われますが、REINFORCEはこの価値関数を必要としません。そのため、複雑な計算を省くことができ、学習にかかる時間や計算資源を節約できるのです。
また、REINFORCEは、行動の選択に確率的な要素を取り入れることができます。例えば、ある状況で複数の選択肢がある場合、それぞれの選択肢を選ぶ確率を学習します。常に同じ行動を選ぶのではなく、状況に応じて確率的に行動を選択することで、より高度な行動戦略を学ぶことができます。例えば、ゲームで相手を出し抜くような、予測不能な行動を学習できます。また、未知の状況を探求する行動と、既に知っている良い結果を生む行動をバランスよく組み合わせることも可能です。常に最良とされる行動だけをとるのではなく、時にはリスクをとって新しい行動を試すことで、より良い結果に繋がる可能性を広げることができます。
さらに、REINFORCEは方策勾配法と呼ばれる学習方法に属しています。方策勾配法は、行動を選択する確率を少しずつ調整していくことで、より多くの報酬を得られるように学習を進める方法です。REINFORCEは、この方策勾配法の中でも基本的な手法であり、他のより複雑な手法の基礎となっています。つまり、REINFORCEを理解することは、強化学習の様々な手法を学ぶ上での重要な一歩となるのです。
| 長所 | 説明 |
|---|---|
| 簡素な実装 | 価値関数を必要とせず、仕組みが簡素でプログラムに落とし込みやすい。計算の複雑さを軽減し、学習時間と計算資源を節約できる。 |
| 確率的行動選択 | 状況に応じて確率的に行動を選択。ゲームで相手を出し抜く、予測不能な行動や、未知の状況の探求と既知の行動のバランスなど、高度な行動戦略を学習可能。 |
| 方策勾配法の基礎 | 行動選択確率を調整し、報酬最大化を目指す方策勾配法の基本手法。他の複雑な手法の基礎となるため、強化学習の理解に重要。 |
REINFORCEの欠点

強化学習の手法の一つであるREINFORCEは、残念ながら幾つかの難点を抱えています。その中でも特に顕著なのが、学習の不安定さです。REINFORCEは、試行錯誤を通じて最終的な結果から学習を進めるモンテカルロ法を基盤としています。そのため、行動の結果得られる報酬のばらつきが大きいと、学習の方向性が定まらず、最適な行動を見つけ出すのが難しくなります。報酬のばらつきが大きい状況では、まるで迷路の中で右往左往するかのごとく、学習がなかなか収束しないのです。
また、REINFORCEは、一連の行動のまとまりであるエピソードが完了するごとに学習内容を更新します。そのため、更新の頻度が少なく、学習のスピードが遅くなることがあります。特に、目的を達成するまでに多くの段階を踏む必要がある複雑な課題では、報酬が得られるまでに長い時間がかかります。そのため、学習に非常に時間がかかり、実用的な時間内で成果を得ることが難しい場合もあります。これは、長い道のりを歩いた後に初めて正しい道かどうかが分かるようなもので、効率的な学習とは言えません。
さらに、REINFORCEでは方策勾配の推定値の分散が大きくなる問題も存在します。これは、学習の不安定さをさらに増幅させる要因となります。これらの欠点を克服するために、方策勾配の推定値の分散を小さくする方法や、時間差分学習といった様々な改良手法が研究者たちによって提案されています。これらの改良手法は、REINFORCEの弱点を補い、より効率的で安定した学習を実現するための重要な役割を担っています。
| 難点 | 説明 |
|---|---|
| 学習の不安定さ | モンテカルロ法に基づくため、報酬のばらつきが大きいと学習の方向性が定まらず、最適な行動を見つけるのが難しい。 |
| 学習スピードの遅さ | エピソード完了ごとに学習内容を更新するため、更新頻度が低く、学習に時間がかかる。特に複雑な課題では、報酬を得るまでに時間がかかり、実用的な時間内で成果を得るのが難しい。 |
| 方策勾配の推定値の分散が大きい | 学習の不安定さを増幅させる要因となる。 |
まとめ

強化学習とは、試行錯誤を通じて学習を行う枠組みのことです。目的とする行動を達成するために、報酬を最大化するように学習していく手法です。その中で、方策勾配法という行動を決める規則を直接学習する方法があります。この方策勾配法の中でも、最も基本的な手法の一つがREINFORCEです。
REINFORCEは、価値関数という、状態や行動の価値を推定する関数を用いることなく、方策を直接最適化します。価値関数を用いないことで、計算が簡略化され、実装が比較的容易になります。また、行動の種類が非常に多い場合や、連続的な行動空間を持つ問題にも適用できるという利点があります。つまり、複雑で高度な行動戦略を学習できる可能性を秘めている手法です。たとえば、ロボットの歩行制御やゲームの攻略といった複雑なタスクを学習させる際に、REINFORCEは有効な手法となり得ます。
しかし、REINFORCEには学習の不安定さという課題も存在します。学習の過程で、報酬のばらつきが大きくなると、学習が安定せず、最適な方策に収束しない場合があります。また、学習の効率もあまり良くなく、多くの試行錯誤を必要とすることもあります。そのため、実際にはそのまま用いられることは少なく、様々な改良が加えられた手法が用いられることが一般的です。
REINFORCEの改良手法としては、ベースラインの導入、割引報酬和の利用、学習率の調整などが挙げられます。ベースラインとは、報酬の期待値を差し引くことで、報酬のばらつきを抑制する手法です。割引報酬和は、将来の報酬を割引することで、長期的な報酬を考慮した学習を可能にします。学習率の調整は、学習の安定性と効率を向上させるために重要な要素です。
REINFORCEは、強化学習の基礎を理解する上で重要な手法です。その後の多くの強化学習アルゴリズムは、REINFORCEを基に発展してきたものも多くあります。REINFORCEの仕組みや課題を理解することで、より高度な強化学習アルゴリズムの理解も深まります。
| 項目 | 内容 |
|---|---|
| 強化学習 | 試行錯誤を通じて、報酬を最大化することで目的とする行動を達成する学習手法 |
| 方策勾配法 | 行動を決める規則を直接学習する方法 |
| REINFORCE | 方策勾配法の中でも最も基本的な手法の一つであり、価値関数を用いずに方策を直接最適化する。計算が簡略化され実装が容易、行動の種類が多い場合や連続的な行動空間を持つ問題にも適用可能。 |
| REINFORCEの利点 | 計算の簡略化、実装の容易さ、複雑で高度な行動戦略を学習できる可能性(例:ロボットの歩行制御、ゲームの攻略) |
| REINFORCEの課題 | 学習の不安定さ、学習効率の悪さ |
| REINFORCEの改良手法 | ベースラインの導入、割引報酬和の利用、学習率の調整 |
| REINFORCEの重要性 | 強化学習の基礎を理解する上で重要な手法であり、多くの強化学習アルゴリズムの基礎となっている。 |