デュエリングネットワーク:強化学習の進化

AIの初心者
先生、「デュエリングネットワーク」って、普通の強化学習と何が違うんですか?

AI専門家
良い質問だね。普通の強化学習、例えばDQNだと、ある状態である行動をとった時の価値、つまり「状態行動価値Q」を学習するよね。でも、デュエリングネットワークは「状態価値V」と「アドバンテージA」を別々に学習するんだ。ここで「状態価値V」はある状態の価値、「アドバンテージA」はある状態である行動をとった時の価値と状態価値Vの差を表しているんだよ。
AIの初心者
うーん、状態価値とアドバンテージを別々に学習するメリットってあるんですか?
AI専門家
もちろん。例えば、ある状態においてどの行動をとっても価値があまり変わらない場合を考えてみよう。DQNだとそれぞれの行動ごとにQ値を学習する必要があるけど、デュエリングネットワークでは状態価値Vを一度学習すれば、あとはアドバンテージAを少し調整するだけで済む。だから、学習効率が良くなるんだ。
デュエリングネットワークとは。
人工知能の分野で使われる「決闘ネットワーク」という用語について説明します。決闘ネットワークは、強化学習におけるネットワークの仕組みをより良くしたモデルです。従来のDQNと呼ばれる手法では、ある状態である行動をとったときの価値(状態行動価値Q)だけを学習していました。一方、決闘ネットワークでは状態の価値(状態価値V)と、状態行動価値Qから状態価値Vを引いた値である有利さ(アドバンテージA)を学習します。
はじめに

試行錯誤を通して物事を学ぶ学習方法を強化学習と言います。これは、機械学習という分野の一つです。この学習方法では、学習する主体であるエージェントが環境と関わり合いながら、報酬を最大にする行動を選び出す最適な方法を見つけ出します。この分野では、深層強化学習(DQN)という手法がよく使われています。DQNは、深層学習という技術を使って、将来得られる報酬の予測に基づいて行動を決定します。
しかし、DQNには課題もあります。状態と行動の価値を推定する際に、値が不安定になりやすいのです。つまり、学習の過程で予測値が大きく変動し、安定した学習が難しいという問題があります。この問題を解決するために、デュエリングネットワークという新しい手法が開発されました。
デュエリングネットワークは、DQNのネットワーク構造を改良したものです。従来のDQNでは、状態と行動の価値を直接予測していましたが、デュエリングネットワークでは、状態の価値と、その状態における各行動の有利さを別々に予測します。そして、これらを組み合わせることで、最終的な状態行動価値を算出します。このように、状態の価値と行動の有利さを分けて学習することで、より正確で安定した価値の推定が可能になります。
この改良により、学習の効率と安定性が向上し、より良い結果が得られるようになりました。デュエリングネットワークは、強化学習における重要な進歩であり、様々な分野への応用が期待されています。具体的には、ロボット制御やゲームプレイなど、複雑な環境での意思決定が必要な場面で活用が期待されています。
従来手法の課題

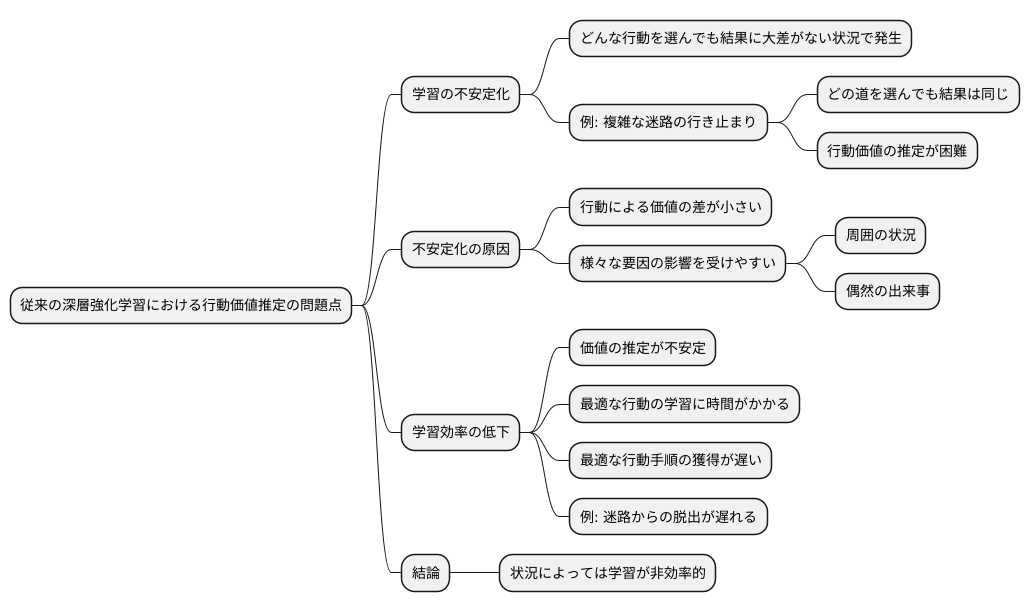
これまでの手法、つまり従来の深層強化学習における行動価値推定の方法には、学習の不安定化という大きな問題がありました。この手法は、ある状況における特定の行動がもたらす将来の報酬の総和、すなわち状態行動価値を直接学習します。しかし、ある状況において、どのような行動を選んでも結果にさほど違いがない場合、この状態行動価値の推定は不安定になりやすいのです。
なぜこのような不安定化が起こるのでしょうか。それは、行動によって得られる価値の差が小さいため、様々な要因による影響を受けやすくなるからです。周囲の状況や偶然の出来事など、わずかな変化が学習に大きく影響してしまい、正確な価値の推定を難しくします。例えば、複雑に入り組んだ迷路の行き止まりに到達したとしましょう。この状況では、どの道を選んでも結果は同じであり、どの行動にも価値の差はありません。そのため、それぞれの行動の価値を正確に推定することは困難になります。
このような状態行動価値の不安定化は、学習効率の低下に直結します。価値の推定が不安定だと、どの行動が最適なのかを学習するのに時間がかかってしまい、結果として最適な行動手順の獲得が遅れてしまうのです。行き止まりにいる例で言えば、どの行動も同じ価値と判断されてしまい、迷路からの脱出方法を学ぶのが遅くなってしまう、といったことが起こりえます。つまり、従来の手法は、状況によっては学習が非効率的になるという課題を抱えていたのです。
デュエリングネットワークの仕組み

勝負を決める網の仕組みを紐解いていきましょう。この仕組みは、ある状況での行動の良し悪しを判断する際に、二つの要素を分けて考える点が画期的です。
まず、「状況の価値」です。これは、ある状況そのものが持つ価値で、どんな行動をとるかは関係ありません。例えば、宝箱がたくさんある部屋にいる状況は、それ自体が良い状況と言えるでしょう。この宝箱の価値は、宝箱を開けるかどうかに関わらず存在します。
次に、「行動による追加の価値」です。これは、特定の状況で、ある行動をとることによって得られる追加の価値です。例えば、宝箱がたくさんある部屋で、宝箱を開けるという行動は、開けないという行動に比べて、より大きな価値を生み出します。これが行動による追加の価値です。
勝負を決める網は、この二つの価値を別々に計算し、後で足し合わせることで、最終的な行動の良し悪しを判断します。具体的には、まず状況の価値を計算する部分と、行動による追加の価値を計算する部分がそれぞれ用意されています。それぞれの部分は、様々な状況や行動から学習し、より正確な価値を算出できるよう調整されていきます。そして最後に、二つの価値を足し合わせることで、ある状況で特定の行動をとることの総合的な価値、つまり状況と行動を組み合わせた価値が算出されます。
このように、二つの価値を分けて学習することで、より正確で安定した判断が可能になります。例えば、似たような状況でも、取るべき行動が大きく異なる場合があります。従来の方法では、このような状況の違いを捉えるのが難しく、学習が不安定になりがちでした。しかし、勝負を決める網では、状況の価値と行動による追加の価値を分けて考えるため、状況の違いをより正確に捉え、より適切な行動を選択できるようになります。つまり、状況に左右されにくい安定した学習が可能になるのです。
二つの流れを持つ構造

「二つの流れを持つ構造」、これはまさにデュエリングネットワークの心臓部と言えるでしょう。この仕組みを理解する鍵は、人間の思考回路との類似性にあります。私たちが何かを決断するとき、例えば夕飯の献立を考えるときを想像してみてください。まず、「今夜は家でご飯を食べる」という状況全体の価値を何となく考えますよね。そして、様々な選択肢、カレーライス、パスタ、それとも焼き魚…それぞれの良さ悪さを比較検討し、最終的に「今日はカレーライスにしよう!」と決断します。
デュエリングネットワークもこれと同じように、二つの流れで情報を処理します。一つ目の流れは、夕飯を家で食べるという状況全体の価値、つまり「状態価値」を評価します。この流れは、与えられた状態が全体的に見てどれくらい良い状態なのかを数値化します。もう一つの流れは、それぞれの選択肢の相対的な価値、つまり「アドバンテージ」を評価します。カレーライスは手軽で満足度が高い、パスタは少し手間がかかる、焼き魚は健康的だけど準備が面倒…といった具合に、各行動のメリット・デメリットを比較します。
そして最後に、この二つの流れが出会い、合流します。状態全体の価値と、各行動の相対的な価値を組み合わせることで、それぞれの行動をとった場合の最終的な価値、すなわち「状態行動価値」を算出します。「家でご飯を食べる」という状況において、「カレーライスを作る」という行動の価値、「パスタを作る」という行動の価値…といったように、それぞれの行動の価値が明確になります。
従来のネットワークでは、状態行動価値を直接計算していましたが、デュエリングネットワークは状態価値とアドバンテージを別々に学習することで、より正確な状態行動価値の推定を可能にします。これは、全体像と細部を別々に捉え、最終的に統合することで、より精緻な判断ができるという、人間の思考様式とよく似ています。この二つの流れを持つ構造こそが、デュエリングネットワークの優れた性能の秘密なのです。
学習の安定化

学習を安定させることは、人工知能の性能向上において重要な課題です。そのための手法の一つとして、デュエリングネットワークという仕組みがあります。デュエリングネットワークは、状態の価値と、それぞれの行動をとることによる価値の差(アドバンテージ)を分けて学習することで、学習の安定化を図っています。
たとえば、囲碁を考えてみましょう。ある盤面の状態の価値は、その盤面がどの程度有利かを表します。そして、その盤面でそれぞれの場所に石を置くという行動をとった場合、その行動による価値の差がアドバンテージです。
デュエリングネットワークでは、状態の価値とアドバンテージを別々に学習することで、それぞれの行動による価値の差が小さい場合でも、状態の価値を正確に学習することができます。たとえば、どの場所に石を置いても結果に大きな違いがない場合、状態の価値が支配的になり、アドバンテージの影響は小さくなります。これは、まるで静かな湖面に小石を投げた時のように、小さな波紋はすぐに消えてしまうようなものです。
このような仕組みによって、学習過程における小さな変動(ノイズ)の影響を受けにくくなり、安定した学習が可能になります。また、状態の価値を共有することで、それぞれの行動の価値を相対的に学習することができ、学習の効率も向上します。これは、複数の商品を比較検討する際に、それぞれの商品の絶対的な価値ではなく、他の商品との相対的な価値を比べることで、より良い選択ができることと似ています。
従来の学習手法であるDQNと比べて、デュエリングネットワークはより安定して最適な行動方針を学習でき、高い性能を達成することが期待できます。これは、複雑な迷路で、より確実に最短経路を見つけることができるようなものです。このように、デュエリングネットワークは、人工知能の学習をより安定させ、より高度な課題を解決する上で、重要な役割を果たしています。
今後の展望

この技術の将来には、大きな期待が寄せられています。これまで、複雑な判断を必要とする作業を機械に学習させることは困難でした。例えば、ロボットの動きを制御したり、ゲームの戦略を考えたり、限られた資源を適切に配分したりといった作業です。このような作業では、様々な状況に応じて最適な行動を選択する必要があるため、従来の学習方法では、効率が悪く、安定した結果を得ることが難しかったのです。しかし、この技術は、より効率的かつ安定した学習を可能にするため、これらの課題を解決する可能性を秘めています。
今後の研究では、この技術の改良や、他の学習方法との組み合わせなどが進むと考えられます。これにより、より高度な人工知能を実現できる可能性があります。特に、現実世界での複雑な状況に対応できる人工知能の開発が期待されています。例えば、自動運転技術では、周囲の状況を判断し、安全な運転を行う必要があります。また、医療診断では、患者の症状や検査結果から、適切な診断を下す必要があります。このような複雑な状況に対応するためには、高度な人工知能技術が不可欠です。
この技術は、様々な分野への応用が期待されています。例えば、工場の生産ラインの自動化や、災害時の救助活動など、人間の生活に役立つ様々な分野で活用される可能性があります。この技術の進化によって、私たちの社会はより便利で安全なものになるでしょう。今後、この技術は、人工知能の進化を加速させる重要な技術として、更なる発展と応用が期待されています。