半教師あり学習:機械学習の新潮流

AIの初心者
「半教師あり学習」って、教師あり学習と教師なし学習の両方のいいとこ取りって感じで、なんとなくすごいのはわかるんですけど、具体的にどんな風に学習するんですか?

AI専門家
いい質問だね。たとえば、猫の画像を分類する機械学習モデルを作るとしよう。教師あり学習では、たくさんの猫の画像に「猫」というラベルを付けて学習させる必要があるよね。でも、半教師あり学習では、少しの猫の画像にラベルを付け、残りの大量の猫の画像はラベル無しで学習させるんだ。
AIの初心者
ラベルがない画像も使うんですか?どうやって学習するのでしょうか?
AI専門家
ラベル付きの画像で学習した特徴を基に、ラベルなし画像の分類を試みるんだ。ラベルなしの大量のデータから、データの構造や特徴を掴み、より正確な分類ができるようにモデルを調整していくんだよ。
Semi-supervised learningとは。
『半教師あり学習』という人工知能の用語について説明します。これは、少しだけ答え付きのデータと、たくさんの答えなしのデータの両方を使って学習する機械学習の方法です。教師あり学習と教師なし学習の中間的な位置づけと言えます。
半教師あり学習は、教師あり学習と教師なし学習、それぞれの良い点を併せ持ち、それぞれの悪い点を克服した方法です。教師あり学習は学習の効率と精度が良いのですが、答えをつける作業に手間がかかります。半教師あり学習では、この手間を減らすことができます。一方、教師なし学習はたくさんのデータを扱うのに費用がかかりにくいのですが、学習の効率と精度はあまり良くありません。半教師あり学習では、この点を改善し、効率と精度を上げることができます。
半教師あり学習は、様々な分野で使われています。例えば、音声の分析、インターネットの情報の分類、タンパク質の遺伝情報の分類などです。
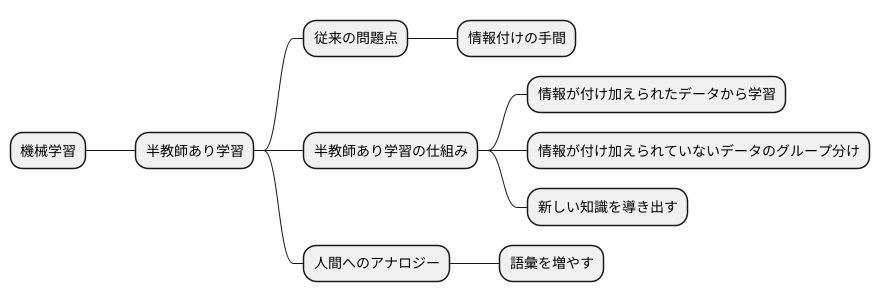
半教師あり学習とは

機械学習という分野の中で、半教師あり学習という方法があります。これは、少しの情報が付け加えられたデータと、何も情報が付け加えられていない大量のデータの両方を使って、機械に学習させる方法です。
たとえば、たくさんの写真があるとします。その中のいくつかには、「ねこ」や「いぬ」といった情報が付け加えられています。これが、情報が付け加えられたデータです。一方で、残りの多くの写真には、何の情報も付け加えられていません。これが、情報が付け加えられていないデータです。
従来の学習方法では、たくさんの情報が付け加えられたデータが必要でした。しかし、写真に一つ一つ「ねこ」や「いぬ」といった情報を付け加えるのは、とても大変な作業です。時間もお金もかかります。そこで考えられたのが、半教師あり学習です。情報が付け加えられていないデータも活用することで、情報付けの手間を減らしながら、機械に学習させようという試みです。
半教師あり学習の仕組みは、次のようなものです。まず、情報が付け加えられたデータから、ねこはこういう特徴、いぬはこういう特徴といった知識を機械に教えます。次に、情報が付け加えられていないたくさんの写真の中から、似た特徴を持つ写真をグループ分けしていきます。既に「ねこ」と情報が付け加えられた写真に似た特徴を持つ写真は、おそらくねこでしょう。このようにして、情報が付け加えられていないデータからも、新しい知識を導き出すのです。
これは、私たち人間が言葉を覚える過程と似ています。少しの単語の意味を知っていれば、たくさんの文章を読むことで、知らない単語の意味を推測し、語彙を増やしていくことができます。半教師あり学習も同様に、限られた情報から、未知の情報を解釈し、より多くのことを学んでいくのです。
教師あり学習と教師なし学習との違い

機械学習には、大きく分けて「教師あり学習」と「教師なし学習」という二つの方法があります。この二つは、まるで先生がいるかいないかの違いのように、学習の進め方が大きく異なります。
まず、先生がいる「教師あり学習」について説明します。これは、例えるなら、たくさんの練習問題と解答がセットになった参考書を使って勉強するようなものです。問題にあたるのが「データ」、解答にあたるのが「正解ラベル」です。学習機は、データと正解ラベルの組み合わせを何度も学習することで、データの特徴と正解ラベルの関係性を理解していきます。この学習を通して、新しいデータに対しても正しい正解ラベルを予測できるようになるのです。例えば、大量の猫と犬の画像と、それぞれの画像に「猫」「犬」というラベルを付けて学習させれば、学習機は新しい画像を見て、それが猫か犬かを判断できるようになります。このように、教師あり学習は高い精度で予測できるという利点があります。しかし、大量のデータに正解ラベルを付ける作業には、多くの時間と手間がかかります。
一方、「教師なし学習」は、先生なしで、大量のデータの中からデータ自身に潜む共通点や規則性を見つける学習方法です。これは、ジグソーパズルを組み立てるようなものです。ピース一つ一つには説明書きはありませんが、形や色を見ながら、どのピースが隣り合うのか、全体像はどうなるのかを推測していく作業に似ています。例えば、顧客の購買履歴データから、顧客をいくつかのグループに分けたり、商品の関連性を見つけたりすることができます。教師なし学習は、正解ラベルを付ける必要がないため、データ収集の手間が大幅に省けます。しかし、学習結果の解釈が難しく、教師あり学習に比べて精度は低いという側面もあります。
このように、教師あり学習と教師なし学習はそれぞれ異なる特徴を持っています。どちらの方法が適しているかは、目的や利用できるデータの種類によって異なります。適切な学習方法を選ぶことで、より効果的に機械学習を活用できます。
| 学習方法 | 説明 | 利点 | 欠点 | 例 |
|---|---|---|---|---|
| 教師あり学習 | データと正解ラベルの組み合わせを学習し、新しいデータに対して正しい正解ラベルを予測する。 | 高い精度で予測できる。 | 正解ラベルを付ける作業に時間と手間がかかる。 | 猫と犬の画像にラベルを付けて学習させ、新しい画像が猫か犬かを判断する。 |
| 教師なし学習 | 大量のデータの中からデータ自身に潜む共通点や規則性を見つける。 | データ収集の手間が大幅に省ける。 | 学習結果の解釈が難しく、教師あり学習に比べて精度は低い。 | 顧客の購買履歴データから顧客をグループ分けする。 |
半教師あり学習の利点

機械学習には、大きく分けて三つの学び方があります。一つは、たくさんの正解付きデータを使って学ぶ教師あり学習、もう一つは正解データを使わずに学ぶ教師なし学習、そして三つ目が、少量の正解付きデータと大量の正解なしデータを使って学ぶ半教師あり学習です。この中で、半教師あり学習は、教師あり学習と教師なし学習の利点を組み合わせた方法と言えます。
半教師あり学習の大きな利点は、データへの正解ラベル付け作業の負担を軽くできることです。一般的に、機械学習のモデルを作るには、大量のデータに正解ラベルを付ける必要があります。例えば、画像に「猫」や「犬」といったラベルを付ける作業です。このラベル付け作業は、多くの場合、人手で行う必要があり、時間も費用もかかる大変な作業です。特に、医学画像の診断や法律文書の分類といった専門知識が必要な分野では、専門家によるラベル付けが必要となるため、その負担はさらに大きくなります。
半教師あり学習では、少量の正解付きデータを使って最初の学習を行い、その後、大量の正解なしデータを使って学習を進めていきます。そのため、必要な正解付きデータの量を大幅に減らすことができます。これは、限られた数の地図と、広範囲にわたる現地調査によって、未知の土地の全体像を把握していくようなものです。
さらに、半教師あり学習は、正解なしデータからデータ全体の構造や隠れたパターンを学ぶことができます。これは、教師あり学習だけでは得られない情報です。例えば、大量の現地調査を行うことで、地図には載っていない地形や隠れた資源を発見できるようなものです。このように、正解なしデータから得られた情報は、モデルの精度向上に大きく貢献します。つまり、限られた情報から全体像を推測し、より正確な理解を築き上げていくことができるのです。
| 学習方法 | 概要 | 利点 |
|---|---|---|
| 教師あり学習 | たくさんの正解付きデータを使って学ぶ | – |
| 教師なし学習 | 正解データを使わずに学ぶ | – |
| 半教師あり学習 | 少量の正解付きデータと大量の正解なしデータを使って学ぶ 教師あり学習と教師なし学習の利点を組み合わせた方法 |
|
半教師あり学習の応用例

半教師あり学習は、限られたラベル付きデータと大量のラベルなしデータの両方を利用する学習手法であり、様々な分野でその有効性が実証されています。ラベル付きデータは学習の指針となり、ラベルなしデータはモデルの性能向上に貢献します。
音声認識の分野では、音声を文字に変換する際に、大量の音声データが必要となります。しかし、全ての音声データにラベル(文字起こし)を付けるのは多大な費用と時間がかかります。そこで、半教師あり学習を用いることで、少量の音声データにラベルを付け、残りの大量の音声データはラベルなしのまま学習に利用できます。これにより、ラベル付けのコストを抑えつつ、高精度な音声認識モデルを構築することが可能になります。例えば、方言の認識や特定の専門用語の音声認識など、ラベル付きデータの入手が困難な場合でも、半教師あり学習は効果を発揮します。
画像分類においても、半教師あり学習は力を発揮します。画像に写っている物体を自動で分類するためには、通常、大量の画像データとそれぞれの画像に付けられたラベル(例えば、「猫」「犬」「車」など)が必要です。しかし、全ての画像にラベルを付けるのは非常に手間がかかります。半教師あり学習を用いれば、一部の画像にだけラベルを付け、残りの画像はラベルなしのまま学習に利用できます。これにより、少ないラベル付き画像データでも、高精度な画像分類モデルを構築することが可能になります。例えば、医療画像診断や衛星画像解析など、ラベル付けに専門知識が必要な場合でも、半教師あり学習は有効な手法となります。
自然言語処理の分野でも、半教師あり学習は幅広く応用されています。例えば、文章の感情分析では、文章が肯定的な感情を表しているか、否定的な感情を表しているかを自動で判断する必要があります。このためには、大量の文章データとそれぞれの文章に付けられた感情ラベルが必要です。しかし、全ての文章に感情ラベルを付けるのは困難です。半教師あり学習を用いれば、少量の文章に感情ラベルを付け、残りの文章はラベルなしのまま学習に利用することで、高精度な感情分析モデルを構築できます。その他、機械翻訳や文章要約など、様々な自然言語処理タスクにおいても、半教師あり学習は有効な手法となります。
| 分野 | 課題 | 半教師あり学習の利点 | 例 |
|---|---|---|---|
| 音声認識 | 音声データの文字起こしに必要なラベル付けのコストが高い | 少量の音声データへのラベル付けで、残りの大量の音声データはラベルなしのまま学習に利用可能。高精度な音声認識モデルを構築。 | 方言の認識、特定の専門用語の音声認識 |
| 画像分類 | 全ての画像へのラベル付けが手間 | 一部の画像へのラベル付けで、残りの画像はラベルなしのまま学習に利用可能。少ないラベル付き画像データでも、高精度な画像分類モデルを構築。 | 医療画像診断、衛星画像解析 |
| 自然言語処理 | 感情分析など、大量の文章データへのラベル付けが困難 | 少量の文章へのラベル付けで、残りの文章はラベルなしのまま学習に利用可能。高精度な感情分析モデルを構築。 | 機械翻訳、文章要約 |
半教師あり学習の課題

半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを活用することで、学習データの作成コストを削減できる有望な手法です。しかし、その実用化に向けては、いくつかの課題を乗り越える必要があります。まず、ラベルなしデータの質が低い場合、学習モデルの精度に悪影響を及ぼす可能性があります。ラベルなしデータにノイズや誤りが含まれていると、モデルが誤ったパターンを学習し、本来の目的から外れた予測をしてしまうかもしれません。ラベルなしデータの質を事前に評価し、必要に応じてクリーニングやフィルタリングを行うことが重要です。
次に、ラベル付きデータとラベルなしデータの分布に大きな違いがある場合、モデルの学習がうまくいかないことがあります。例えば、ラベル付きデータが特定のクラスに偏っている一方で、ラベルなしデータが他のクラスを多く含む場合、モデルはラベル付きデータに過剰に適合し、ラベルなしデータから適切な情報を学習できない可能性があります。ラベル付きデータとラベルなしデータの分布の類似性を確認し、必要に応じてデータの拡張や重み付けなどの工夫を行う必要があります。
さらに、適切な学習モデルの選択と、その学習における様々な設定値の調整も重要です。半教師あり学習には様々な手法があり、それぞれ得意とするデータの特性や課題が異なります。また、手法ごとに調整が必要な設定値も多数存在し、これらの設定が不適切であると、期待する性能が得られない可能性があります。データの特性を理解し、適切な手法を選択するだけでなく、設定値を丁寧に調整する必要があります。
これらの課題を解決するために、現在も活発に研究開発が進められています。例えば、ラベルなしデータからより効果的に学習するための新しい手法や、ラベル付きデータとラベルなしデータの分布の違いを考慮した学習の仕組みなどが提案されています。こうした研究の進展により、半教師あり学習が持つ潜在能力が最大限に発揮され、様々な分野での応用が進むことが期待されます。
| 課題 | 詳細 | 対策 |
|---|---|---|
| ラベルなしデータの質の低さ | ノイズや誤りが含まれるラベルなしデータは、モデルの精度に悪影響を与える。 | ラベルなしデータの質を事前に評価し、クリーニングやフィルタリングを行う。 |
| ラベル付きデータとラベルなしデータの分布の違い | 分布の大きな違いは、モデルの学習を阻害する。例えば、ラベル付きデータのクラス偏りが、ラベルなしデータから適切な情報を学習するのを妨げる。 | ラベル付きデータとラベルなしデータの分布の類似性を確認し、データの拡張や重み付けなどの工夫を行う。 |
| 適切な学習モデルの選択と設定値の調整 | 半教師あり学習には様々な手法と設定値があり、適切な選択と調整が不可欠。不適切な設定は期待する性能を阻害する。 | データの特性を理解し、適切な手法を選択する。設定値を丁寧に調整する。 |
今後の展望

近年、機械学習という分野で、一部のデータだけに答えとなる情報が付与された、いわば不完全な教師データを用いる学習方法が注目を集めています。この学習方法は、半教師あり学習と呼ばれ、今後の発展が大いに期待されています。特に、人間の脳の仕組みを模倣した学習方法である深層学習と組み合わせることで、従来の方法では達成できなかった高い精度が実現すると期待されています。
深層学習は、膨大なデータから複雑な規則性を学ぶことができる強力な学習方法です。しかし、この学習方法には、全ての学習データに答えとなる情報、つまりラベルが付与されている必要があるという課題がありました。ラベル付け作業には、多大な時間と費用がかかるため、深層学習の活用範囲が制限されていました。半教師あり学習を用いることで、ラベル付きデータが少ない状況でも、深層学習の能力を最大限に発揮させることができると考えられています。具体的には、ラベルの付いていないデータからも有効な情報を抽出し、学習に役立てることで、精度向上を目指します。
また、データの性質やばらつき具合の違いを考慮した、より高度な学習手順を作ることも重要な研究課題です。現実世界で集められるデータは、必ずしも質が良いとは限らず、データの特性も様々です。このような多様なデータにうまく対応できるような、新しい学習方法の開発が求められています。
これらの研究が進むことで、半教師あり学習は、医療、製造、金融など、より多くの分野で活用され、私たちの社会に大きな貢献をもたらすと期待されます。ラベル付きデータの不足という、機械学習の普及を妨げる大きな障害を取り除き、機械学習の可能性を大きく広げる、まさに未来を切り開く技術と言えるでしょう。
| 学習方法 | 説明 | 課題 | 期待される効果 |
|---|---|---|---|
| 半教師あり学習 | 不完全な教師データ(一部のデータにのみラベルが付与)を用いる学習方法 | – | 今後の発展が大いに期待されている。特に深層学習と組み合わせることで高い精度が実現すると期待されている。ラベル付きデータが少ない状況でも深層学習の能力を最大限に発揮させることができると考えられている。 |
| 深層学習 | 人間の脳の仕組みを模倣した学習方法。膨大なデータから複雑な規則性を学ぶことができる。 | 全ての学習データにラベルが付与されている必要がある。ラベル付け作業には、多大な時間と費用がかかるため、深層学習の活用範囲が制限されている。 | – |
| 高度な学習手順 | データの性質やばらつき具合の違いを考慮した学習手順。現実世界で集められるデータは、必ずしも質が良いとは限らず、データの特性も様々であるため、多様なデータにうまく対応できるような、新しい学習方法の開発が求められている。 | – | – |