クイックソート:高速な並び替え

AIの初心者
先生、「クイックソート」ってどういう意味ですか?なんか速そうな名前ですが。

AI専門家
そうだね、名前の通り速い並び替え方法だよ。例えば、たくさんの数字がバラバラに並んでいたら、まず基準となる数字を決める。そして、その基準より小さい数字と大きい数字の二つのグループに分けるんだ。
AIの初心者
基準を決めて、大きいものと小さいもので分けるんですね。それで全部が順番通りになるんですか?
AI専門家
いいところに気がついたね。分けたグループの中で、また同じように基準を決めて、大小で分けていくんだ。これを繰り返すと、最終的に全部の数字が順番通りに並ぶんだよ。
クイックソートとは。
ある値を基準にして、それより大きいか小さいかでデータをグループ分けしていく、という作業を繰り返すことで、最終的にデータを順番に並べ替える方法。この方法は『クイックソート』と呼ばれ、人工知能の分野でよく使われています。
クイックソートとは

クイックソートは、様々な並び替え方法の中でも特に速さで知られる、優れた方法です。この方法では、まず、整理したいデータ群から一つ、「基準」となる値を選びます。この基準値を用いて、残りのデータを「基準より小さい値の集まり」と「基準より大きい値の集まり」の二つに分けます。
この分ける操作を、分けられたそれぞれの集まりに対しても繰り返し行うことが大切です。小さな集まりに対しても、また基準となる値を選び、それより小さい値と大きい値に分けていきます。これを繰り返すことで、最終的にはデータ全体が小さい順、もしくは大きい順に綺麗に並び変わります。
クイックソートの最も注目すべき点は、その処理速度です。名前の通り、非常に素早くデータを並び替えることができます。データの数を「ん」とすると、平均して「ん」かける「んを底とする対数のん」回の計算で並び替えが完了します。これは、他の一般的な並び替え方法と比べても、非常に少ない計算回数です。
そのため、扱うデータの量が多い場合や、処理の速さが求められる状況では、クイックソートはまさにうってつけの方法と言えるでしょう。例えば、膨大な数の商品データを価格順に並べ替えたり、検索エンジンの結果を素早く表示したりする際に、このクイックソートは大きな力を発揮します。沢山のデータを扱う現代社会において、クイックソートはなくてはならない重要な技術の一つと言えるでしょう。
基準値の選び方

整列されていないデータの集まりを、小さい順に並べ替える手順をクイックソートと言います。このクイックソートは、ある値を基準として、それより小さい値と大きい値にデータを分けることを繰り返すことで、最終的に整列を実現します。この基準となる値を基準値と呼びます。
この基準値の選び方が、クイックソートの速さに大きく影響します。もし、基準値がデータ全体のちょうど真ん中の値、つまり中央値に近い値であれば、データはほぼ均等に分割されます。例えば、1から100までの数字がバラバラに並んでいて、50に近い数字を基準値に選ぶと、50より小さい数字と大きい数字がほぼ同数になり、効率的に整列作業を進められます。これを繰り返すことで、少ない手順で整列が完了します。
しかし、中央値を正確に求めるには、すべてのデータを一度調べる必要があるため、手間がかかります。これは、整列されていないデータの中から中央値を見つける作業自体が、それなりに計算を必要とするからです。
そこで、実際には、データの先頭、末尾、または真ん中の値を基準値として使うことがよくあります。これらの値は、データ全体を調べることなく簡単に取得できるため、計算の手間を省けます。もちろん、これらの値が必ずしも中央値に近いとは限りません。しかし、多くの場合、ある程度の分割効率を確保でき、計算の手間と分割効率のバランスが取れた良い選択と言えます。
基準値の選び方は、クイックソートの速さに直結する重要な要素です。状況に応じて適切な基準値を選ぶことで、より効率的な整列処理を実現できます。
| 基準値の選び方 | 説明 | メリット | デメリット |
|---|---|---|---|
| 中央値 | データ全体のちょうど真ん中の値 | データがほぼ均等に分割され、整列作業が効率的 | 中央値を正確に求めるには、すべてのデータを一度調べる必要があるため、手間がかかる |
| 先頭、末尾、中央の値 | データの先頭、末尾、または真ん中の値 | データ全体を調べることなく簡単に取得できるため、計算の手間を省ける | これらの値が必ずしも中央値に近いとは限らないため、分割効率は中央値に劣る場合がある |
分割の方法

決められた基準となる値を基に、データを適切な大きさの集団に分けていく手順を説明します。この分割作業は様々なやり方がありますが、ここではよく使われる方法を紹介します。
まず、基準値と比較するために、データの並びの左端から探し始めます。この時探しているのは、基準値よりも大きな値です。同時に、今度は右端から基準値より小さな値を探します。
もし、左端から探した基準値より大きな値と、右端から探した基準値より小さな値が見つかった場合、その二つの値を入れ替えます。この入れ替え作業を、左端から探し始める位置と右端から探し始める位置がぶつかるまで繰り返します。
左右の位置がぶつかった時点で、基準値よりも小さな値は全て基準値の左側、基準値よりも大きな値は全て基準値の右側に並んでいる状態になります。この状態を達成するために、左右から探し、入れ替えるという一連の動作は欠かせません。
最後に、基準値を適切な場所に移動させます。具体的には、基準値より小さい値が並んでいる部分の右端、もしくは基準値より大きな値が並んでいる部分の左端が、基準値の適切な位置です。基準値をそこに移動することで、分割作業は完了です。
この分割作業は、「クイックソート」と呼ばれる、データを昇順もしくは降順に並べ替える処理方法の核心部分にあたります。この分割作業の速さが、クイックソート全体の処理速度に直結するため、作業を効率よく行う方法を工夫することがとても大切です。
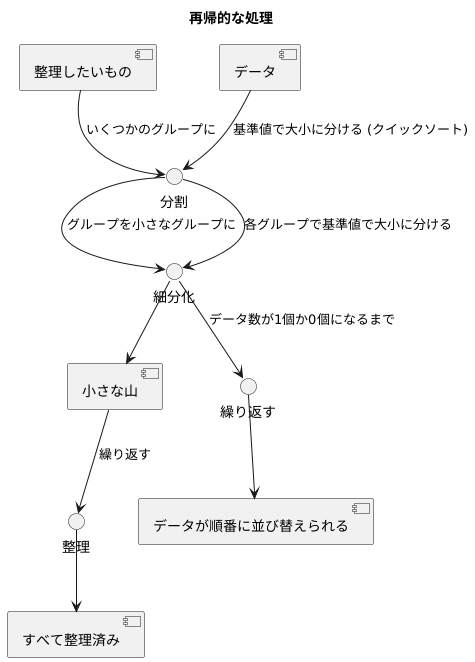
再帰的な処理

ものを整理するとき、たくさんのものを一度に片付けるのは大変です。しかし、整理したいものをいくつかのグループに分け、さらにグループを小さなグループに分けていくと、最終的には簡単に整理できる小さな山になります。これを繰り返すと、すべてが整理されます。
コンピュータの世界でも同じような方法でデータを整理できます。これを「再帰的な処理」と言います。「再帰」とは、自分自身を繰り返すという意味です。
例えば、「クイックソート」という方法でデータの並び替えをするとき、この「再帰的な処理」が使われます。クイックソートでは、まず基準となる値を決めて、それより小さい値のグループと大きい値のグループにデータを分けます。次に、分けたそれぞれのグループに対して、再び同じ基準値を決めて、小さい値のグループと大きい値のグループに分けます。これを、各グループのデータ数が1個か0個になるまで繰り返すのです。
データ数が1個になれば、それ以上分ける必要はありませんし、0個であれば、そもそもデータが存在しないので、何もする必要はありません。このようにして、最終的にすべてのデータが順番に並び替えられるのです。
この繰り返しの処理は、一見複雑そうですが、プログラムを簡潔に書くことができます。なぜなら、同じ処理を何度も書く代わりに、「自分自身を呼び出す」という指示を一度書くだけで済むからです。まるで、整理整頓が得意な人が、同じ手順を繰り返し用いて、大きな山を小さな山に分け、最終的にすべてを整理するように、コンピュータも効率よくデータを処理できるのです。
計算量と安定性

高速な並び替え手法として知られるクイックソートは、平均的には要素数nに対してnかけるlog nの計算量で処理を終えることができます。これは、大量のデータを扱う場合でも比較的速やかに結果を得られることを意味します。しかし、この手法には落とし穴が存在します。最悪の場合、既に整列済みのデータのように、基準となる値の選択が不適切だと、計算量がnの2乗にまで膨れ上がってしまうのです。nの2乗の計算量は、データ量が増えるほど処理時間が急激に増加することを意味し、膨大なデータの場合は現実的な時間内に処理を終えられない可能性も出てきます。
クイックソートの高速性は、基準となる値を適切に選ぶことで実現されます。この値をピボットと呼びますが、ピボットの選択によって、データ群を適切に分割し、効率的に並び替えることができます。理想的には、ピボットによってデータ群がほぼ均等に分割されることが望ましいです。しかし、常に最適なピボットを選ぶことは難しく、最悪の場合は、分割が極端に不均等になり、結果としてnの2乗の計算量になってしまうのです。
さらに、クイックソートは安定な並び替え手法ではありません。安定な並び替えとは、同じ値を持つ要素が、並び替え前と同じ順序で並ぶことを保証するものです。例えば、名前と成績のデータがあり、成績で並び替える際に、同じ成績の生徒は名前の順序が変わらないようにしたい場合、安定な並び替えが必要となります。クイックソートでは、ピボットを基準とした要素の交換が頻繁に行われるため、同じ値を持つ要素の相対的な順序が保たれない可能性があります。つまり、クイックソートは安定性を保証しない並び替え方法なのです。そのため、安定性が求められる場合は、クイックソート以外の方法を検討する必要があります。
| 項目 | 説明 |
|---|---|
| 平均計算量 | n log n |
| 最悪計算量 | n2 (既に整列済みのような、ピボット選択が不適切な場合) |
| ピボット | 基準となる値。データ群を分割するために使用される。理想的にはデータ群を均等に分割する値が望ましい。 |
| 安定性 | 不安定。同じ値を持つ要素の並び替え前の順序が保持されない可能性がある。 |
まとめ

高速な並び替え方法として知られるクイックソートは、その名前の通り、多くの場面で素早くデータを整理するために使われています。膨大なデータを取り扱う現代社会において、この処理速度の速さは非常に重要です。インターネット検索の結果表示や、大量の顧客データの管理など、様々な場面でクイックソートが活躍しています。
クイックソートは、まずデータの中から一つの値を基準値として選びます。そして、この基準値より小さい値を左側、大きい値を右側に配置するようにデータを並び替えます。この操作を分割と呼びます。分割が終わると、基準値は正しい位置に配置されます。次に、基準値の左側と右側のデータそれぞれに対して、同じ操作を繰り返します。これを再帰的に行うことで、最終的に全てのデータが順番通りに並び替えられます。
クイックソートの処理速度は、平均的にはデータの個数とデータ個数の対数の積に比例します。これは、他の多くの並び替え方法と比べて非常に効率的です。しかし、基準値の選び方やデータの初期状態によっては、最悪の場合、処理速度がデータの個数の二乗に比例してしまうこともあります。例えば、既に整列済みのデータに対して、最小値または最大値を基準値として選び続けると、処理速度が低下します。そのため、基準値を適切に選ぶことが、クイックソートの性能を最大限に引き出す鍵となります。よく用いられる方法として、データの中央値や、ランダムに選んだ値を基準値とする方法などがあります。
また、クイックソートは、同じ値を持つデータの並び順が、並び替え後に入れ替わってしまう可能性があります。つまり、安定な並び替え方法ではありません。同じ値を持つデータの順番を保持する必要がある場合は、別の並び替え方法を検討する必要があります。
このように、クイックソートは高速である一方、いくつかの注意点も存在します。これらの長所と短所を理解した上で、適切な場面でクイックソートを活用することで、効率的なデータ処理を実現できます。
| 項目 | 内容 |
|---|---|
| アルゴリズム名 | クイックソート |
| 処理速度(平均) | データの個数 × log(データの個数) に比例 |
| 処理速度(最悪) | データの個数の二乗に比例 |
| 安定性 | 不安定(同じ値のデータの順序が保持されない可能性あり) |
| 基準値の選択 | 処理速度に大きな影響を与える。中央値やランダムな値などが用いられる。 |
| 長所 | 高速な並び替えアルゴリズム |
| 短所 | 基準値の選び方によっては処理速度が低下する。安定な並び替えではない。 |
| 用途 | インターネット検索の結果表示、顧客データの管理など |
| アルゴリズム概要 | 基準値を元にデータを分割し、再帰的に処理を行う。 |