過学習とは?機械学習で起きる「覚えすぎ」の問題をわかりやすく解説

AIの初心者
『過学習』ってどういう意味ですか?機械学習でよく聞くのですが、イメージがつかみにくいです。

AI専門家
過学習とは、練習問題を覚え込みすぎて、新しい問題に対応できなくなるような状態だよ。機械学習では、訓練データにはよく当たるのに、未知のデータでは予測精度が下がることを指すんだ。
AIの初心者
学習すればするほど良いわけではないんですね。どうして過学習は起きるのですか?
AI専門家
主な原因は、モデルが複雑すぎること、学習データが少ないこと、データに偏りやノイズがあることだね。大切なのは、訓練データを丸暗記させるのではなく、未知のデータにも通用する規則を学ばせることだよ。
過学習とは。
過学習とは、機械学習モデルが訓練データに過度に適応し、未知のデータに対する予測性能が下がる現象です。訓練データの特徴だけでなく、偶然含まれたノイズや例外まで覚えてしまうため、実際に使う場面で精度が落ちやすくなります。
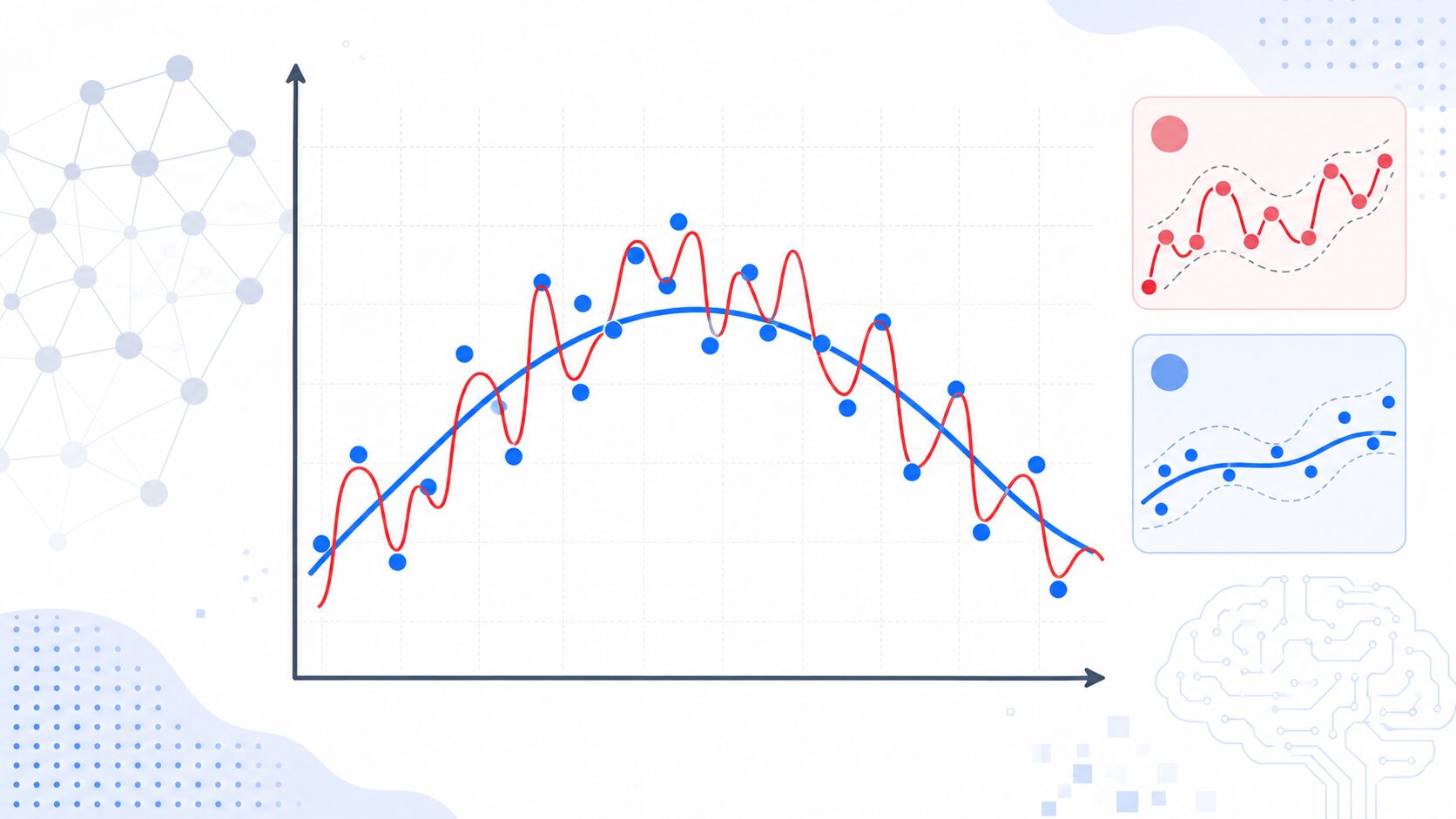
過学習とは何か
過学習とは、機械学習モデルが訓練データに合わせすぎて、まだ見たことのないデータにうまく対応できなくなる状態です。英語では overfitting と呼ばれます。機械学習の目的は、手元のデータを当てることだけではなく、将来入力される未知のデータに対しても妥当な予測をすることです。この未知データへの対応力を、一般に汎化性能といいます。
たとえば、試験対策で過去問の答えを丸暗記した生徒を考えると分かりやすいでしょう。同じ問題が出れば満点を取れますが、少し表現が変わった応用問題では解けなくなります。これは問題の本質を理解したのではなく、過去問そのものを覚えてしまった状態です。
機械学習モデルでも同じことが起こります。訓練データに対する正解率は高いのに、検証データやテストデータでは精度が低い場合、モデルはデータ全体に共通する規則ではなく、訓練データにだけ現れる細かな癖を学んでいる可能性があります。つまり、表面的にはよく学習できているように見えても、実用上は使いにくいモデルになっているのです。
過学習が起きる主な原因
過学習は一つの原因だけで起きるとは限りません。多くの場合、モデルの複雑さ、データ量、データ品質が組み合わさって発生します。
まず大きな原因は、モデルが複雑すぎることです。パラメータ数が多いモデルや表現力が高すぎるモデルは、訓練データの小さな揺れまで細かく再現できます。これは一見便利ですが、紙の汚れや偶然の偏りまで規則として覚えてしまうようなものです。本来捉えるべき大きな傾向よりも、訓練データ固有の細部に引っ張られてしまいます。
次に、学習データが少ないことも重要です。少ないサンプルだけを見て全体の傾向を判断すると、偏った結論になりやすくなります。赤いりんごを数個だけ見て「りんごはすべて赤い」と考えてしまうのと同じです。データが少ないほど、モデルは偶然見えた特徴を過大評価しやすくなります。
さらに、データの偏りやノイズも過学習の原因になります。特定の地域、期間、ユーザー層だけから集めたデータで学習すると、その条件にだけ強いモデルになりがちです。また、入力ミスや測定誤差が多いデータをそのまま使うと、モデルが本質ではない情報まで学習してしまいます。
| 原因 | 何が起きるか | 例 |
|---|---|---|
| モデルが複雑すぎる | 訓練データの細かなノイズまで覚える | 過去問の答えだけを丸暗記する |
| データが少ない | 限られた例から偏った規則を作る | 数個の例だけで全体を判断する |
| データに偏りがある | 特定条件にだけ強いモデルになる | 一部地域のデータだけで全国を予測する |
| ノイズが多い | 偶然の誤差まで意味のある特徴として扱う | 汚れや誤記を重要情報だと見なす |
過学習の見分け方
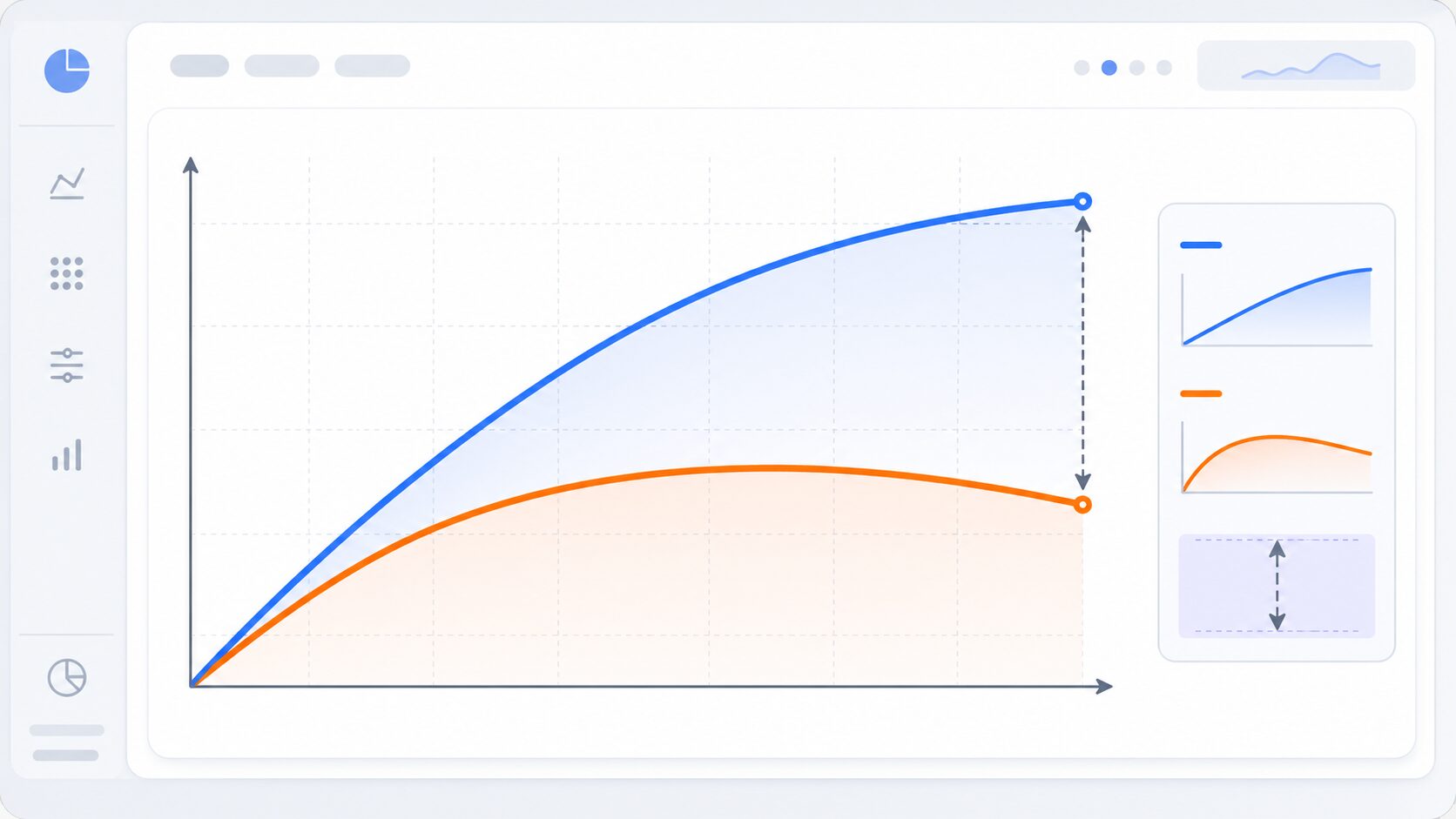
過学習を見分ける基本は、訓練データでの性能と、検証データでの性能を比較することです。訓練データとはモデルを学習させるためのデータで、検証データとは学習中のモデルを評価するために分けておくデータです。最終確認には、さらに別のテストデータを使うこともあります。
典型的な過学習では、訓練データの正解率や損失は改善し続けます。一方で、検証データの正解率は途中で頭打ちになったり、逆に悪化したりします。この差が広がっていくほど、モデルは訓練データにだけ適応している可能性が高くなります。
実務では、学習曲線を確認すると兆候を見つけやすくなります。学習曲線とは、学習回数に応じて訓練性能と検証性能がどう変わるかを記録したグラフです。訓練性能だけを見ると順調に見えても、検証性能が伸びていなければ、モデルをそのまま採用するのは危険です。
また、精度だけで判断しないことも大切です。分類問題なら適合率、再現率、F値、AUCなど、回帰問題なら平均絶対誤差や二乗平均平方根誤差など、目的に合った評価指標を見ます。たとえば不正検知のように少数の重要なケースを見逃したくない問題では、単純な正解率だけではモデルの良し悪しを判断できません。
過学習を防ぐ方法
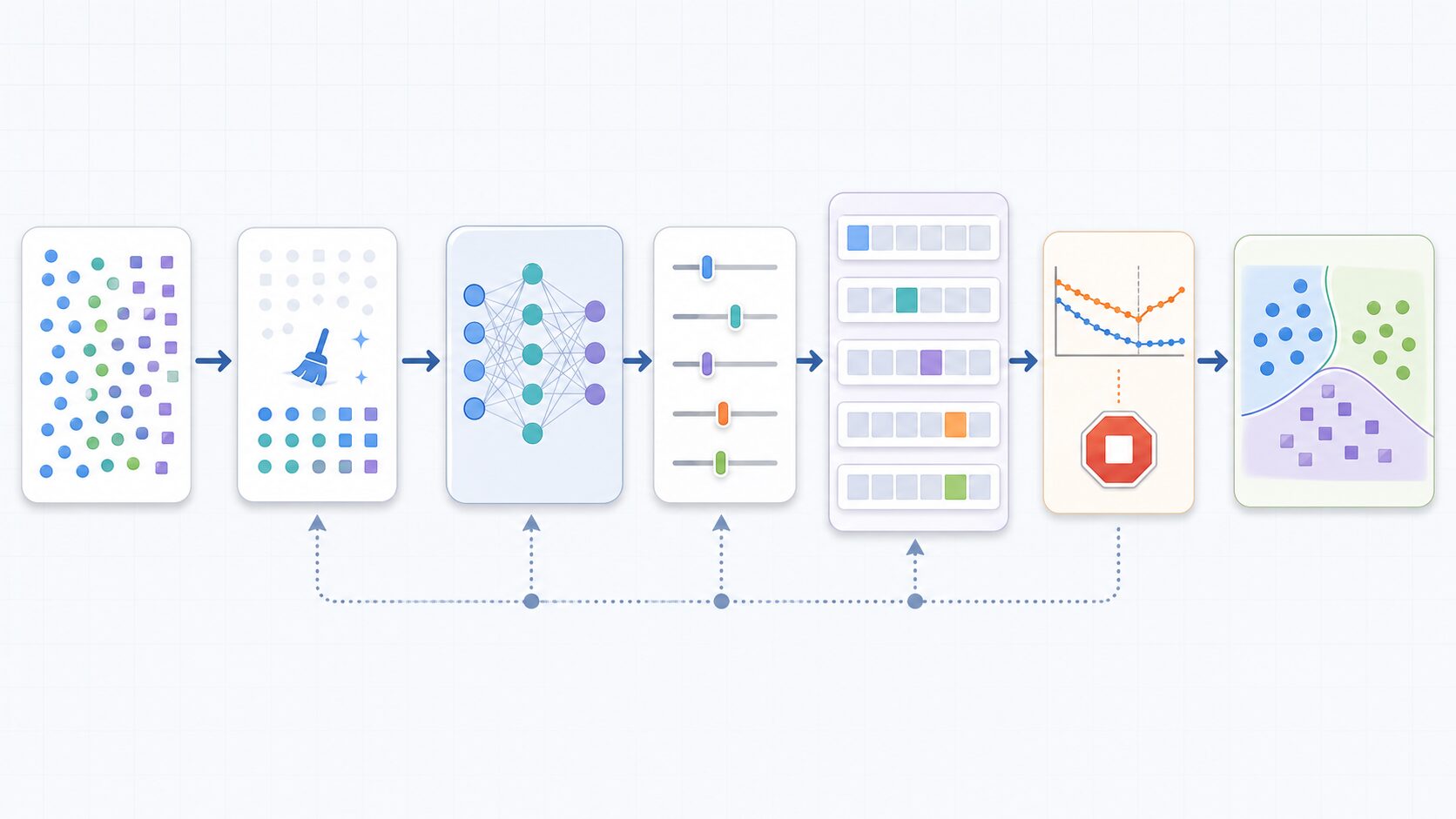
過学習への対策は、モデルだけでなくデータと評価方法も含めて考える必要があります。代表的な方法は、データを増やす、データの質を上げる、モデルを単純化する、正則化を使う、交差検証で安定性を確認する、といったものです。
まず、十分な量のデータを用意することは基本です。多様なデータで学習させるほど、モデルは個別の例ではなく共通する傾向を学びやすくなります。ただし、数を増やすだけでは不十分です。重複データ、誤ったラベル、極端に偏ったデータが多い場合は、むしろ悪い癖を強めることがあります。データの確認、前処理、外れ値への対応も重要です。
モデルの複雑さを抑えることも有効です。不要に大きなモデルを使うと、訓練データを細かく覚え込みやすくなります。問題の規模に合ったモデルを選び、特徴量を整理し、必要に応じてパラメータ数を減らすことで、汎化性能を高めやすくなります。
正則化は、モデルが複雑になりすぎないように制約を加える方法です。L1正則化やL2正則化は、重みが大きくなりすぎることを抑えます。ニューラルネットワークでは、学習中に一部のユニットをランダムに無効化するドロップアウトもよく使われます。特定の特徴だけに依存しすぎないようにするためです。
交差検証も過学習対策として役立ちます。データを複数のグループに分け、学習と評価の組み合わせを変えながら性能を確認する方法です。特定の分割にだけ強いモデルではないかを確認できるため、データが限られている場合にも有効です。
さらに、早期終了も実務でよく使われます。これは、検証データの性能が改善しなくなった時点で学習を止める方法です。訓練データへの当てはまりだけを追い続けると過学習に向かうため、未知データへの性能を基準に学習を止める考え方です。
| 対策 | 目的 | 初心者向けの見方 |
|---|---|---|
| データを増やす | 多様なパターンを学習させる | 応用問題を多く解く |
| データ品質を改善する | 偏りやノイズの影響を減らす | 誤った問題や偏った教材を減らす |
| モデルを単純化する | 細部への過剰適応を抑える | 難しすぎる解法に頼りすぎない |
| 正則化を使う | 重みや表現の複雑さに制約をかける | 暗記ではなく本質を重視する |
| 交差検証を行う | 評価の安定性を確認する | 複数の模擬試験で実力を見る |
| 早期終了を使う | 学習しすぎる前に止める | 伸びなくなった時点で詰め込みをやめる |
過学習と未学習の違い
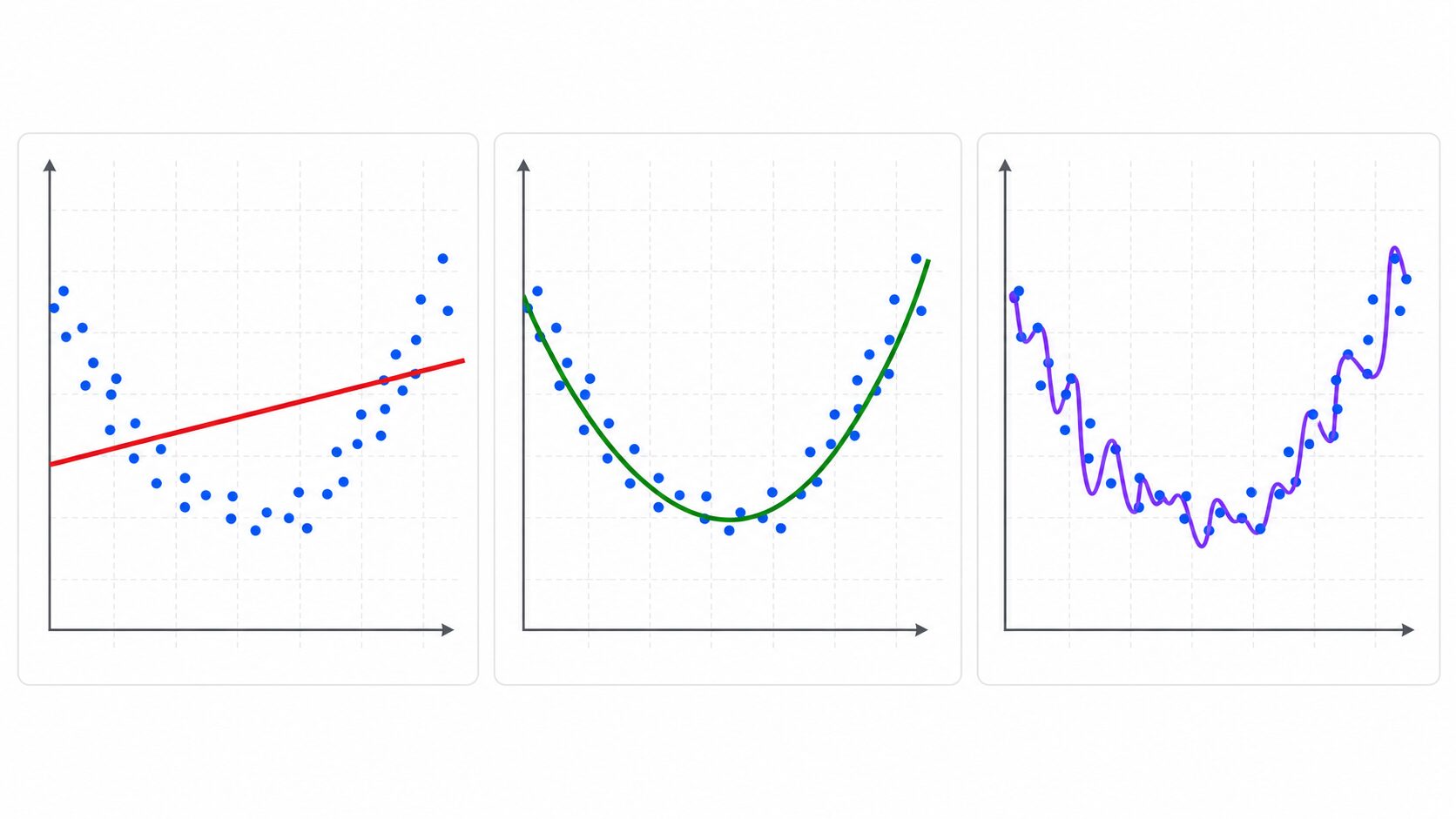
過学習と一緒に理解しておきたい言葉が未学習です。未学習とは、モデルが訓練データの傾向すら十分に捉えられていない状態です。過学習が「訓練データには強いが未知データに弱い」状態だとすると、未学習は「訓練データにも未知データにも弱い」状態です。
たとえば、過学習は過去問を丸暗記した状態です。一方、未学習は基本事項をまだ理解できていない状態です。どちらも実用的な予測には向きません。目指すべきは、訓練データの傾向を十分に学びつつ、未知データにも対応できるバランスの取れた状態です。
| 状態 | 訓練データでの性能 | 未知データでの性能 | 主な原因 |
|---|---|---|---|
| 未学習 | 低い | 低い | モデルが単純すぎる、学習不足、特徴量不足 |
| 適切な学習 | 高い | 高い | モデルの複雑さとデータ量のバランスが良い |
| 過学習 | 非常に高い | 低い | モデルが複雑すぎる、データ不足、ノイズや偏り |
実務で過学習を避けるための注意点
実務では、過学習を完全に避けるというより、早く見つけて影響を小さくする姿勢が重要です。まず、訓練データ、検証データ、テストデータを適切に分けます。このとき、同じユーザーや同じ時系列の情報が複数のデータセットに混ざると、実際より良い性能に見えることがあります。これをデータ漏洩と呼び、過学習の発見を難しくします。
また、モデルを改善するときは、検証データへの性能だけを何度も見て調整しすぎないようにします。検証データに合わせた調整を繰り返すと、検証データにも過度に適応してしまうためです。最終的な性能確認には、調整に使っていないテストデータを残しておくのが基本です。
過学習は、AIや機械学習の精度向上を考えるうえで避けて通れない問題です。しかし、原因と兆候を理解し、適切なデータ分割、評価指標、対策を組み合わせれば、未知のデータにも対応しやすいモデルに近づけられます。訓練データで高精度が出た時ほど、検証データや実運用に近いデータで同じように性能が出るかを確認することが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月1日 | 過学習の定義、原因、兆候、対策、未学習との違いを初心者向けに再構成 |