行動者と批評家:Actor-Critic手法

AIの初心者
先生、「行為者-批評家」って難しくてよくわからないです。行為者と批評家がどう連携するんですか?

AI専門家
そうだね、少し複雑だね。「行為者」はまず、自分が持っている知識に基づいて行動を選びます。そして「批評家」がその行動の結果を見て、良かったか悪かったかを評価するんだ。
AIの初心者
なるほど。じゃあ、批評家の評価を受けて、行為者は次にどうするんですか?
AI専門家
批評家の評価を参考に、行為者は自分の知識を更新するんだよ。例えば、批評家に良い評価をもらったら、同じような行動をもっと取るように学習する。逆に悪い評価だったら、その行動を避けるように学習するんだ。これを繰り返すことで、行為者はどんどん賢くなっていくんだよ。
Actor-Criticとは。
「人工知能」に関わる言葉である「行為者-批評者」について説明します。「行為者-批評者」とは、価値を基にした方法と、方策の傾きを基にした方法を組み合わせた手法です。この手法は、行動を決める「行為者」と、行動を評価する「批評者」の2つでできています。まず、「行為者」が方針に基づいて行動を選び、実行します。次に、その行動の結果として得られた状態や報酬を「批評者」が環境から観察します。そして、「批評者」が観察した状態と報酬に基づいて評価を行い、その評価に基づいて「行為者」が方針を更新します。この一連の作業を繰り返し行います。
行動主体と評価主体

「行動主体」と「評価主体」は、難しい問題を解くための協力する二人組のようなものです。これは、試行錯誤を通じて学習する「強化学習」という方法で使われています。この方法では、「行動主体」は現在の状況に応じてどのような行動をとるかを決定する役割を担います。例えば、迷路にいるロボットの場合、「行動主体」は、右に曲がるか、左に曲がるか、まっすぐ進むかなどを決めます。「評価主体」は、「行動主体」が選択した行動の良し悪しを評価する役割を担います。ロボットが右に曲がって袋小路に入ってしまった場合、「評価主体」は低い点数をつけます。反対に、ロボットが左に曲がって出口に近づいた場合、「評価主体」は高い点数をつけます。「行動主体」は、「評価主体」から受け取った点数に基づいて、自分の行動を改善していきます。最初はランダムに動くロボットも、「評価主体」からの点数が高い行動を繰り返すことで、徐々に正しい道を選べるようになります。
「評価主体」は、環境からの報酬を基に評価基準を洗練させていきます。例えば、ロボットが迷路の出口に到達すると、大きな報酬が与えられます。この報酬を基に、「評価主体」は出口に近い行動ほど高い点数をつけるように評価基準を調整します。このように、「行動主体」と「評価主体」は互いに影響を与えながら学習を進めます。「行動主体」は「評価主体」の評価を参考にしながら行動を改善し、「評価主体」は環境からの報酬を参考にしながら評価基準を洗練させます。この二人組が協力することで、迷路を解くような複雑な問題に対する最適な行動を見つけ出すことが可能になります。まるで、先生と生徒のように、互いに教え合い、学び合う関係と言えるでしょう。「評価主体」はまるで先生のように、「行動主体」である生徒に適切な助言を与え、生徒は先生の助言を参考にしながら、より良い行動を学習していくのです。
| 主体 | 役割 | 例(迷路ロボット) | 学習方法 |
|---|---|---|---|
| 行動主体 | 現在の状況に応じて行動を決定 | 右に曲がる、左に曲がる、まっすぐ進む | 評価主体からの点数に基づいて行動を改善 |
| 評価主体 | 行動主体の行動の良し悪しを評価 | 袋小路:低点数、出口に近い:高点数 | 環境からの報酬に基づいて評価基準を洗練 |
価値関数と方策勾配

強化学習における価値関数と方策勾配は、エージェントが最適な行動を学習するための重要な要素です。価値関数ベースの手法と方策勾配法ベースの手法は、それぞれ異なるアプローチでこの問題に取り組みます。
価値関数ベースの手法は、各状態の価値を推定することに焦点を当てます。状態の価値とは、その状態から開始して将来得られる報酬の期待値を表します。価値関数が正確に推定できれば、エージェントは常に価値の高い状態へと遷移するように行動を選択することで、最適な行動を実現できます。例えば、迷路を解く問題では、ゴールに近い状態ほど価値が高くなります。価値関数ベースの手法は、この価値に基づいて、迷路の出口へと効率的に進む経路を見つけ出します。
一方、方策勾配法ベースの手法は、行動を選択する方策を直接学習します。方策とは、各状態でどの行動をとるかの確率分布を表します。方策勾配法は、試行錯誤を通じて方策を調整し、より高い報酬が得られる行動の選択確率を高めていきます。迷路の例では、方策勾配法は、壁にぶつかる行動の確率を下げ、ゴールへ近づく行動の確率を上げるように方策を調整します。
これらの二つの手法を組み合わせたのが、Actor-Criticと呼ばれる手法です。Actor-Criticでは、Actorが方策を調整し、Criticが価値関数を用いてActorの行動を評価します。Criticは、Actorが選択した行動によって得られた報酬と、価値関数の推定値を比較することで、Actorの行動の良し悪しを判断します。Actorはこの評価を基に、より高い評価を得られるように方策を更新していきます。このように、ActorとCriticが互いに協力することで、より効率的に最適な行動を学習できます。Actor-Criticは、価値関数ベースの手法の安定性と、方策勾配法の柔軟性を兼ね備えた、強力な学習手法と言えるでしょう。
| 手法 | 説明 | 例(迷路) |
|---|---|---|
| 価値関数ベースの手法 | 各状態の価値(将来得られる報酬の期待値)を推定。価値の高い状態へと遷移するように行動を選択。 | ゴールに近い状態ほど価値が高く、その価値に基づいて出口への経路を見つける。 |
| 方策勾配法ベースの手法 | 行動を選択する方策(各状態でどの行動をとるかの確率分布)を直接学習。試行錯誤を通じて、より高い報酬が得られる行動の選択確率を高める。 | 壁にぶつかる行動の確率を下げ、ゴールへ近づく行動の確率を上げる。 |
| Actor-Critic | Actorが方策を調整し、Criticが価値関数を用いてActorの行動を評価。ActorとCriticが協力して最適な行動を学習。 | CriticはActorの行動の良し悪しを判断し、Actorはその評価に基づき方策を更新。 |
学習の進め方

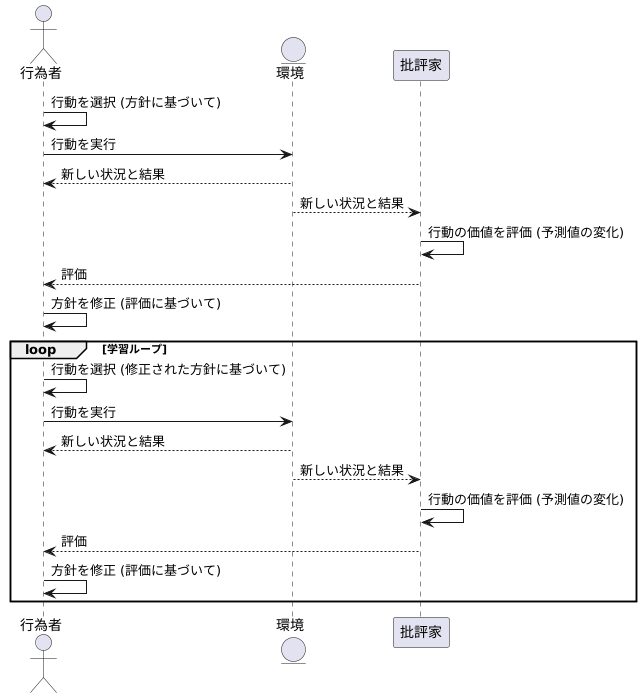
学習は、まず行為者が現在の状況に基づいて行動を決めることから始まります。この行動は、まるで役者が台本に書かれた通りに演技をするように、行為者が持つ方針に従って選ばれます。そして、選んだ行動を環境の中で実際に試します。
行動を実行すると、環境は変化し、新しい状況と結果が生まれます。これは、役者が演技をした結果、観客の反応や物語の展開が変わるようなものです。この新しい状況と結果は、批評家によって観察・評価されます。
批評家は、行為者が取った行動の価値を、将来得られるであろう成果の予測値の変化という形で評価します。例えば、行為者の行動によって将来得られる成果の予測値が上がった場合、その行動は良い行動だったと評価されます。逆に、予測値が下がった場合、その行動は悪い行動だったと評価されます。この評価は、行為者にとって次の行動を決めるための重要な指針となります。
行為者は、批評家からの評価を基に、自分の行動方針をより良いものへと修正していきます。これは、役者が批評家の意見を参考に、演技を改善していくようなものです。より良い評価を得られる行動の選択確率を高め、悪い評価を得られる行動の選択確率を低くすることで、行為者はより良い行動を選択できるようになります。
この一連の流れ、すなわち行為者が行動を選び、環境で試し、批評家が評価し、行為者が方針を修正する、という過程を何度も繰り返すことで、学習が進みます。行為者は最適な行動方針を学び、批評家はより正確な評価基準を身につけていきます。このように、行為者と批評家は互いに助け合いながら学習を進め、最終的には環境の中で最も良い結果を得られる行動戦略を習得します。
手法の利点

この手法には、他の学び方のやり方と比べた時に、いくつかの良い点があります。まず一つ目に、学び方が安定しているという点です。方策勾配法という別の学び方では、行動の選び方を直接変えていくため、学び方が不安定になりがちです。まるで、でこぼこ道を自転車で進むようなもので、すぐにバランスを崩してしまうイメージです。一方、この手法では、批評家のような役割を持つ部分が、価値関数という尺度を使って行動を評価します。この評価をもとに行動の選び方を調整するので、自転車に補助輪が付いているかのように、安定した学び方ができます。二つ目の良い点として、連続的な行動に対応できるという点があります。行動には、サイコロを振るように、いくつかの選択肢から一つを選ぶ離散的な行動と、ハンドルを回す角度のように、連続的な値をとる行動があります。方策勾配法は、前者の離散的な行動しか扱えませんが、この手法は後者の連続的な行動にも対応できます。これは、行動の選び方を確率の分布として表すことで可能になります。例えば、ハンドルの角度を調整するときに、どの角度がどれくらいの確率で選ばれるかを表すことで、滑らかな動きを実現できます。このように、批評家による評価と確率分布による行動の表現により、この手法は安定した学び方と連続的な行動への対応を実現しています。これにより、より複雑な課題を解くための、強力な道具となります。
| メリット | 説明 | 具体例 |
|---|---|---|
| 安定した学習 | 価値関数による評価に基づいて行動を調整するため、学習が安定する。 | 自転車に補助輪が付いているようなイメージ |
| 連続的な行動への対応 | 行動の選び方を確率分布として表現することで、連続的な行動を扱える。 | ハンドルの角度調整のように、滑らかな動きを実現 |
様々な応用例

行為者批評家法は、その応用範囲の広さから、様々な分野で活用されています。
まず、ロボットの制御分野では、ロボットアームの正確な動きを制御したり、移動ロボットが障害物を避けながら目的地まで移動するための経路計画を立てたりするために利用されています。従来の方法では、複雑な計算が必要でしたが、行為者批評家法を用いることで、より効率的にロボットを制御することが可能になります。例えば、工場の組み立てラインで、部品の取り付けや溶接作業を行うロボットアームの制御に役立ちます。また、倉庫内を自律走行するロボットや、災害現場で活動するレスキューロボットなどにも応用が期待されます。
次に、ゲームにおける人工知能の開発分野では、複雑なルールや戦略が必要なゲームにおいて、人間の競技者にも匹敵する、あるいは勝る性能を持つ人工知能の開発に貢献しています。従来の人工知能では、あらかじめ決められた手順に従って行動するだけでしたが、行為者批評家法を用いることで、試行錯誤を通じて学習し、より高度な戦略を立てることが可能になります。例えば、囲碁や将棋などの頭脳ゲームや、複雑な操作が求められるアクションゲームなどで、より人間に近い思考力を持つ人工知能の実現に役立ちます。
金融取引の分野においても、市場価格の変動を予測し、最も利益の上がる投資戦略を決定するために活用されています。過去の市場データに基づいて学習することで、将来の市場動向を予測し、リスクを最小限に抑えながら利益を最大化する投資判断を行うことが可能になります。
さらに、医療診断の分野でも、患者の症状や検査結果に基づいて、最適な治療方針を決定するシステムの開発に利用されています。様々な治療方法の効果やリスクを学習することで、個々の患者に最適な治療方法を提案することが可能になります。例えば、がん治療における放射線療法や化学療法の最適な組み合わせを決定する際に役立ちます。
このように、行為者批評家法は、幅広い分野でその有効性が確認されており、今後、様々な分野での更なる活用が期待されています。
| 分野 | 活用例 | 従来の方法との比較 |
|---|---|---|
| ロボット制御 | ロボットアームの制御、移動ロボットの経路計画 | 複雑な計算が必要だった制御をより効率的に |
| ゲームAI開発 | 複雑なルールや戦略を持つゲームAI | あらかじめ決められた手順ではなく、試行錯誤で学習 |
| 金融取引 | 市場価格変動予測と最適な投資戦略決定 | 過去のデータに基づいて将来の市場動向を予測 |
| 医療診断 | 患者に最適な治療方針決定システム | 様々な治療の効果やリスクを学習し最適な治療法を提案 |
今後の発展

「行為者批評家手法」と呼ばれる学習方法は、今も盛んに研究開発が続けられており、今後ますます性能が向上していくと期待されています。特に、「深い学び」と呼ばれる手法と組み合わせた「深い強化学習」は、近年大きな注目を集めています。
「深い学び」を使うことで、より複雑な環境での学習が可能になり、より高度な作業をこなせるようになります。例えば、「画像認識」と組み合わせることで、視覚情報をもとに行動を決める仕組みを作ることができます。カメラの映像から周りの状況を理解し、どのように動くべきかを判断するロボットなどを想像してみてください。
また、「ことばの処理」と組み合わせることで、人間との会話を通じて学習する仕組みを作ることも期待されています。人間と自然な言葉でやり取りしながら、様々な知識や技能を習得していくロボットの実現も夢ではありません。まるで人と人が教え合うように、ロボットが人間から新しいことを学ぶことができるようになるでしょう。
「行為者批評家手法」は、行動を選ぶ部分と、その行動を評価する部分を分けて学習させるという特徴があります。行動を選ぶ部分は、どのような行動をとるべきかを学び、評価する部分は、その行動がどれくらい良いかを判断します。この二つの部分を同時に学習させることで、より効率的に学習を進めることができます。
このように、「行為者批評家手法」は「深い学び」と組み合わせることで、さらに発展していく可能性を秘めています。そして、ロボット工学や自動運転、ゲームなど、様々な分野で活躍していくことが期待されています。近い将来、私たちの生活の様々な場面で、この技術が役立っている姿を目にすることになるでしょう。
| 手法 | 特徴 | 応用分野 |
|---|---|---|
| 行為者批評家手法 | 行動選択部分と行動評価部分を分けて学習 深い学びと組み合わせることで、複雑な環境での学習や高度な作業が可能 |
ロボット工学 自動運転 ゲーム など |
| 深い強化学習(行為者批評家手法 + 深い学び) | 画像認識と組み合わせ、視覚情報から行動決定 ことばの処理と組み合わせ、人間との会話を通じて学習 |
ロボット工学 自動運転 ゲーム など |