ホールドアウト検証と交差検証とは?意味・仕組み・活用例をわかりやすく解説

AIの初心者
交差検証が少し難しく感じます。ホールドアウト検証とは何が違うんですか?

AI専門家
ホールドアウト検証は、データを訓練用とテスト用に一度だけ分けて評価する方法だよ。たとえば、全体の8割で練習し、残りの2割で実力を測るような考え方だね。
AIの初心者
では、k分割交差検証は何を繰り返しているんですか?
AI専門家
データをk個に分け、1つをテスト用、残りを訓練用にする組み合わせを順番に変えるんだ。評価をk回行って平均するので、1回だけ分ける方法より結果が安定しやすいよ。
ホールドアウト検証とは。
「人工知能」や「機械学習」で使われるホールドアウト検証は、データを学習用とテスト用に分け、学習済みモデルが未知のデータにどれくらい対応できるかを確認する方法です。分割を複数回変えて評価する代表的な方法が、k分割交差検証です。
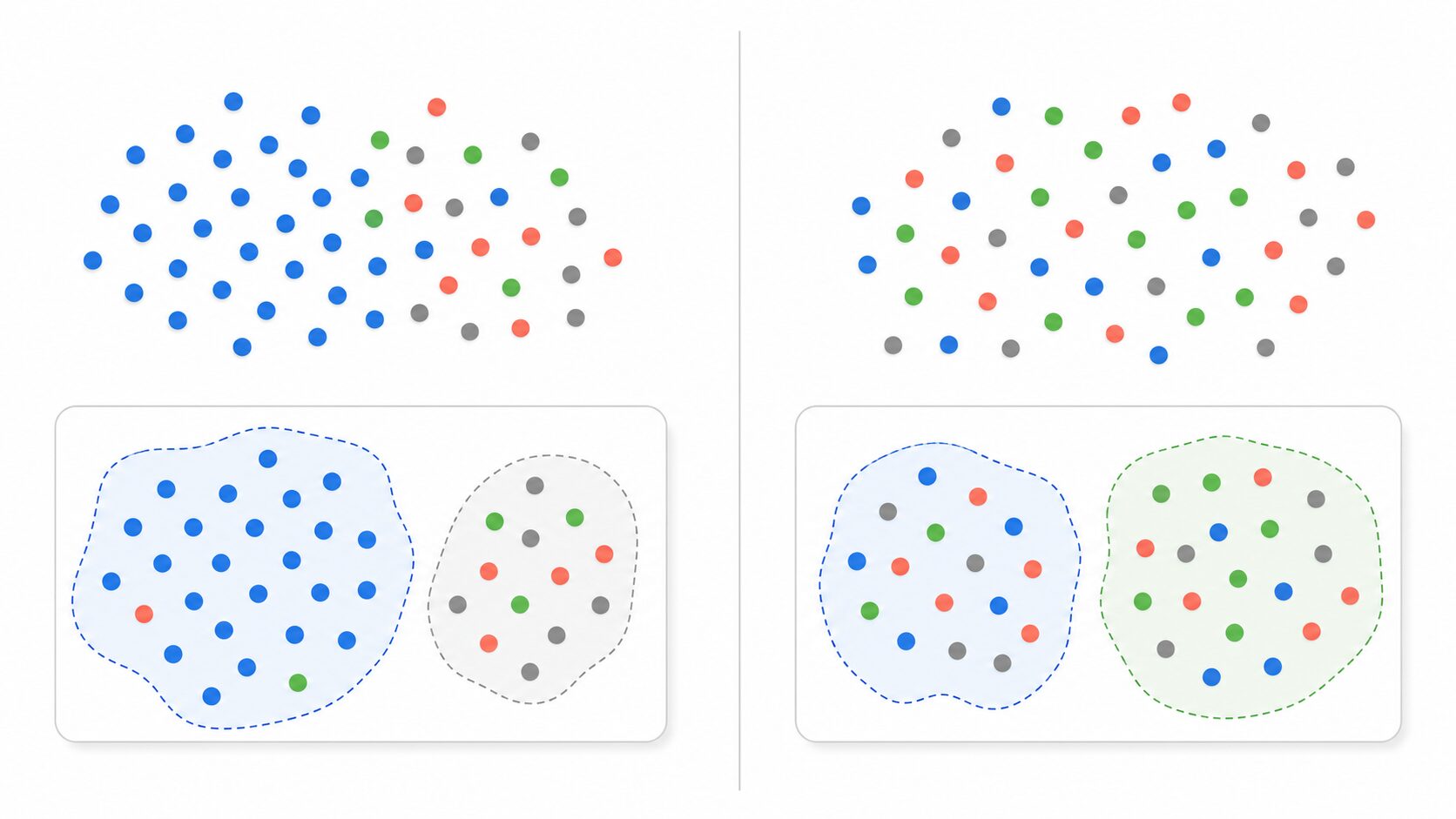
ホールドアウト検証と交差検証とは
機械学習では、モデルを作るだけでなく、まだ見たことのないデータに対してどのくらい正しく予測できるかを確かめる必要があります。この未知のデータへの対応力を、一般に汎化性能と呼びます。
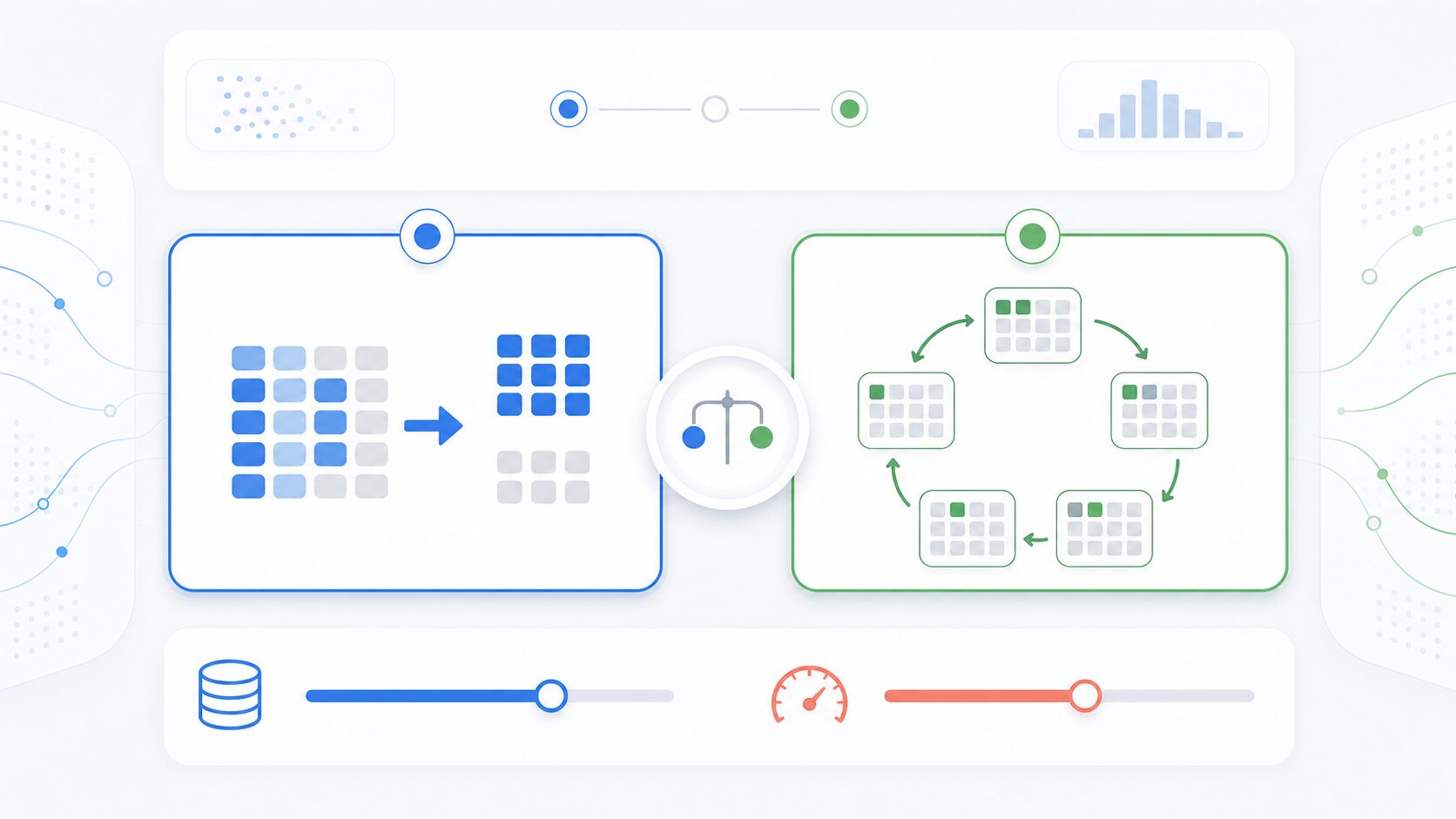
ホールドアウト検証と交差検証は、どちらも汎化性能を評価するためのデータ分割の方法です。ホールドアウト検証は、データを訓練用とテスト用に一度だけ分けます。交差検証は、分け方を変えながら複数回評価し、その結果をまとめます。
初心者がまず押さえるべき違いは、ホールドアウト検証は速くて単純、交差検証は手間が増える代わりに評価が安定しやすいという点です。どちらが常に正しいというより、データ量、計算時間、評価に求める厳密さによって使い分けます。
ホールドアウト検証の仕組み
ホールドアウト検証では、手元のデータを訓練データとテストデータに分けます。訓練データでモデルを学習させ、学習に使っていないテストデータで性能を測ります。よく使われる分け方は、訓練データを7割または8割、テストデータを3割または2割にする方法です。
たとえば、顧客の購買予測モデルを作る場合、全データの8割を使ってモデルに購買パターンを学習させます。その後、残りの2割で予測精度を確認します。このときテストデータは、モデルにとって初めて見るデータでなければなりません。
この方法の利点は、手順が理解しやすく、計算も速いことです。大規模なデータがあり、まず短時間でモデル候補を比較したいときには扱いやすい方法です。一方で、一度だけの分割に評価結果が左右されるため、データが少ない場合や偏りが大きい場合には注意が必要です。
データ分割で注意したい偏り
ホールドアウト検証で特に重要なのは、訓練データとテストデータが全体の特徴をなるべく反映していることです。分割に偏りがあると、モデルの学習や評価が実際の利用場面からずれてしまいます。
たとえば、ある地域の顧客データばかりが訓練データに入り、別の地域の顧客データばかりがテストデータに入ると、モデルは特定地域の特徴に強く影響されます。この状態では、評価結果が低すぎたり、逆に一部の条件にだけ合って高く見えたりすることがあります。
分類問題では、正例と負例の比率にも注意します。たとえば不正検知のように不正データが少ない問題では、単純にランダム分割するとテストデータに不正例がほとんど入らないことがあります。このような場合は、クラス比率を保ちながら分ける層化分割が有効です。
また、時系列データでは、未来の情報を使って過去を予測する形にならないようにします。売上予測や需要予測のような問題では、単純なランダム分割ではなく、時間の順序を保った検証方法を選ぶ必要があります。
交差検証が必要になる理由
ホールドアウト検証は便利ですが、たまたま選ばれたテストデータが簡単だったり難しかったりすると、評価結果がぶれます。データ数が少ないほど、この影響は大きくなります。そこで、分割を変えながら複数回評価する交差検証が使われます。
交差検証では、データの一部をテスト用、残りを訓練用として評価する手順を、分割の組み合わせを変えながら繰り返します。そして、それぞれの評価結果を平均して、最終的な性能の目安にします。
この方法を使うと、1回の分割だけに依存しにくくなります。すべてのデータがどこかの回でテストデータとして使われるため、限られたデータを評価にも学習にも活用しやすいのが特徴です。
ただし、交差検証ではモデルを複数回学習させるため、計算時間は増えます。複雑なモデルや大きなデータセットでは、評価の安定性と計算コストのバランスを考える必要があります。
k分割交差検証の手順
代表的な交差検証が、k分割交差検証です。データをk個のグループに分け、そのうち1つをテストデータ、残りのk-1個を訓練データとして使います。この処理をk回繰り返し、各グループが一度ずつテストデータになるようにします。

たとえば5分割交差検証では、データを5つのグループに分けます。1回目はグループ1をテスト用、グループ2から5を訓練用にします。2回目はグループ2をテスト用にし、残りを訓練用にします。これを5回繰り返し、5つの評価結果を平均します。
10分割交差検証では、同じ考え方を10個のグループで行います。一般的には、k=5やk=10がよく使われます。kを大きくすると訓練に使えるデータの割合は増えますが、学習回数も増えるため計算時間が長くなります。
kがデータ数と同じになる特殊な方法は、leave-one-out cross validationと呼ばれます。1件だけをテストデータにして、それ以外を訓練データにする処理をデータ数分だけ繰り返すため、データを無駄にしにくい反面、計算量が非常に大きくなることがあります。
ホールドアウト検証と交差検証の違い
両者の違いは、分割回数、評価の安定性、計算時間に表れます。ホールドアウト検証は一度だけ分けるため速く、交差検証は複数回分けるため安定した評価を得やすくなります。
| 検証方法 | 仕組み | 利点 | 注意点 | 向いている場面 |
|---|---|---|---|---|
| ホールドアウト検証 | データを訓練用とテスト用に一度だけ分ける | 手順が簡単で計算が速い | 分け方によって評価がぶれやすい | データが十分に多い場合、短時間で比較したい場合 |
| 交差検証 | 分割を変えながら複数回学習と評価を行う | 評価が安定しやすく、データを有効に使える | 学習回数が増え、計算に時間がかかる | データが少ない場合、評価の信頼性を高めたい場合 |
実務では、最初にホールドアウト検証で大まかにモデル候補を絞り、その後に交差検証で評価を確認する流れもあります。検証方法は単独で考えるのではなく、モデル開発の目的や制約と合わせて選ぶことが大切です。
どちらの検証方法を選ぶべきか
素早く結果を見たい場合や、データが十分に多く代表性のあるテストデータを確保できる場合は、ホールドアウト検証が使いやすい選択肢です。モデルの試作段階では、計算時間を抑えられることが大きな利点になります。
一方、データ数が限られている場合や、1回の分割だけでは評価が不安定になりそうな場合は、交差検証が適しています。特に、モデルの性能差が小さい候補を比較するときは、分割の偶然に左右されにくい評価が重要です。
ただし、交差検証の結果が安定して見えても、それだけで本番性能が保証されるわけではありません。データの取得条件が本番環境と異なる場合、どの検証方法を使っても評価と実運用の結果がずれることがあります。
初心者が押さえたい実務上の注意点
まず、テストデータを何度も見ながらモデルや特徴量を調整しすぎないことが重要です。本来テストデータは、最後に性能を確認するために残しておくものです。テストデータに合わせて調整を繰り返すと、評価結果が実際より良く見えることがあります。
次に、データの前処理は検証方法と一緒に考えます。標準化や欠損値補完などを全データに対して先に行ってから分割すると、テストデータの情報が訓練側に漏れることがあります。交差検証では、各分割の訓練データ内で前処理を学習し、対応するテストデータへ適用する流れが基本です。
最後に、評価指標も目的に合わせて選びます。正解率だけでは不十分な問題もあります。不正検知や医療系の分類のように、見逃しと誤検知の重みが違う場合は、適合率、再現率、F1スコア、AUCなども確認します。
まとめ
ホールドアウト検証は、データを訓練用とテスト用に一度だけ分けて評価するシンプルな方法です。計算が速く、流れを理解しやすいため、機械学習の基本として最初に押さえたい検証方法です。
交差検証は、分割を変えながら複数回評価し、結果を平均する方法です。ホールドアウト検証より計算時間はかかりますが、データの分け方による偶然の影響を抑えやすくなります。
検証方法を選ぶときは、データ量、偏り、計算時間、評価に求める信頼性を見ます。特に初心者は、単に手法名を覚えるだけでなく、訓練に使っていないデータで性能を見るという基本を意識すると、モデル評価の考え方を理解しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月19日 | 分割手順、比較表、検証時の漏れや偏りの注意点を追記 |