
PReLUとは?パラメトリックReLUの仕組みとReLUとの違いを解説

AIの初心者
「PReLU」ってどういう意味ですか?ReLUと似ている活性化関数なんですか?

AI専門家
かなり近い関係にあるよ。ReLUは入力が0より大きいときはそのまま出力し、0以下では0を返す関数だね。PReLUは正の入力ではReLUと同じだけれど、負の入力では0にせず、小さな係数を掛けた値を出力するんだ。
AIの初心者
負の値を少しだけ残すんですね。どうしてそのほうが学習に役立つんですか?
AI専門家
ReLUでは負の入力がすべて0になるため、学習中に一部のニューロンが更新されにくくなることがある。PReLUは負の入力にも傾きを残し、その傾き自体を学習で調整できるので、データに合わせた柔軟な表現がしやすくなるんだ。
PReLUとは。
PReLUは「Parametric Rectified Linear Unit」の略で、日本語ではパラメトリックReLU、またはパラメータ付き修正線形ユニットと呼ばれます。ニューラルネットワークで使われる活性化関数の一種で、ReLUの単純さを保ちながら、負の入力に対する挙動を学習できるようにした関数です。

PReLUとは何か
PReLUは、入力が正の値ならそのまま出力し、入力が負の値なら入力に係数を掛けて出力する活性化関数です。通常のReLUでは負の入力がすべて0になりますが、PReLUでは負の領域にも小さな傾きを残します。
この「負の領域の傾き」は、あらかじめ固定するのではなく、モデルの学習中に調整されます。そのためPReLUは、データに合わせて形を変えられる学習可能な活性化関数と考えると理解しやすいでしょう。
たとえば画像認識では、特徴量の中に正の値だけでなく負の値として表れる情報も含まれることがあります。ReLUで負の情報を完全に切り捨てるより、PReLUで少し残したほうが有利に働く場合があります。
活性化関数の役割
ニューラルネットワークは、複数の層で入力データを変換しながら予測や分類を行います。このとき各層の出力に非線形な変換を加えるのが活性化関数です。
活性化関数がない場合、層を何段重ねても全体としては線形変換の組み合わせになり、複雑な境界やパターンを表現しにくくなります。画像の輪郭、音声の変化、文章中の文脈のような複雑な特徴を扱うには、非線形性が欠かせません。
ReLUやPReLUは、この非線形性をシンプルな計算で導入するための代表的な関数です。特に深いニューラルネットワークでは、計算の軽さと勾配の扱いやすさが重要になるため、ReLU系の活性化関数がよく使われます。
| 用語 | 意味 |
|---|---|
| ニューラルネットワーク | 層とニューロンを組み合わせ、データから特徴を学習するモデル |
| 活性化関数 | 各層の出力を変換し、モデルに非線形性を与える関数 |
| 非線形性 | 直線的な関係だけでは表せない複雑なパターンを扱う性質 |
PReLUの数式と計算の流れ
\(f(x)=
\begin{cases}
x & (x>0)\\
a x & (x\leq 0)
\end{cases}
\)
PReLUは、入力を \(x\)、負の領域に掛ける係数を \(a\) とすると、上のように表せます。入力が0より大きい場合は \(x\) をそのまま返し、0以下の場合は \(a x\) を返します。
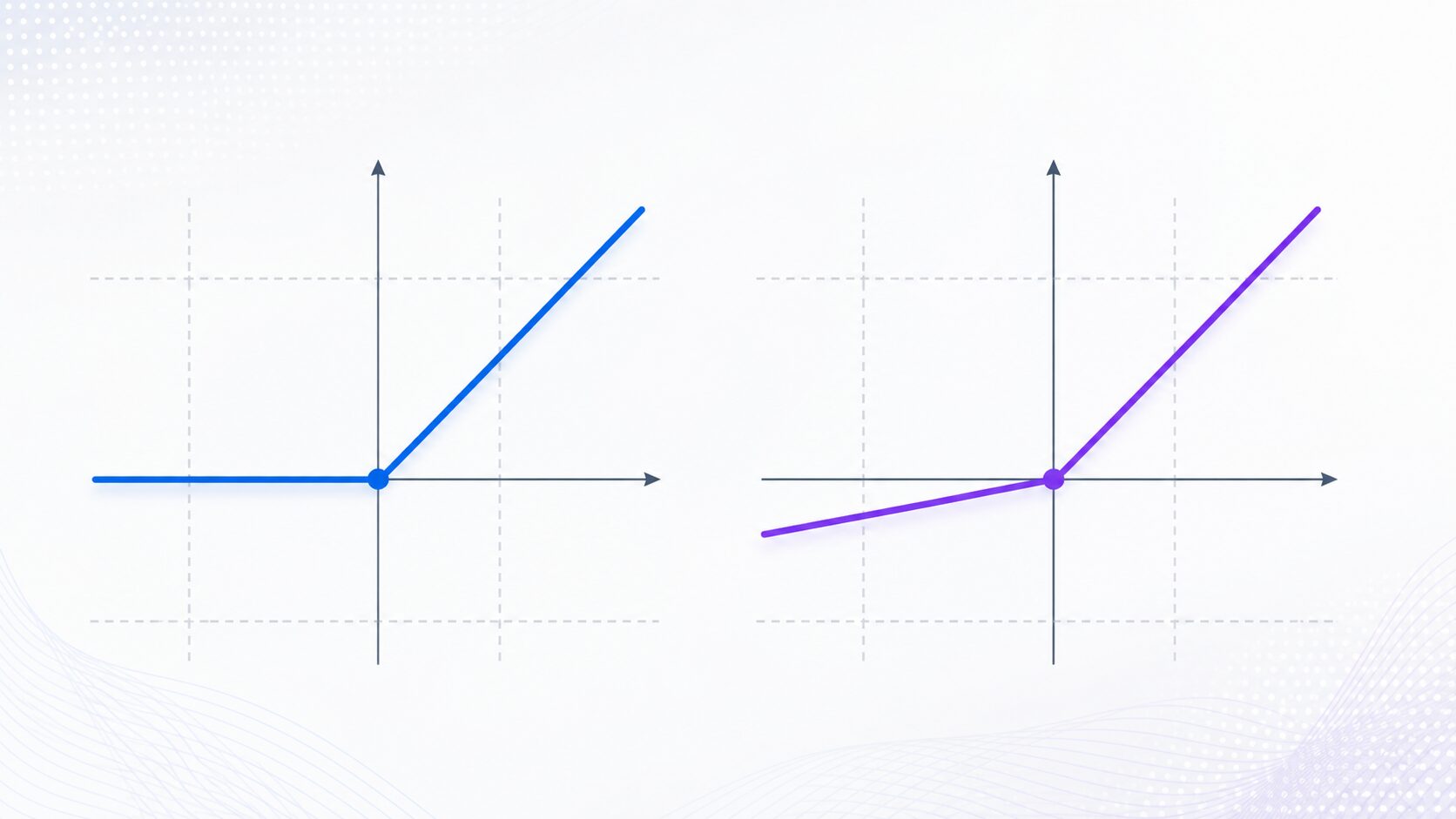
重要なのは、係数 \(a\) が学習対象になる点です。固定値を使うLeaky ReLUとは異なり、PReLUでは重みやバイアスと同じように、誤差を小さくする方向へ \(a\) が更新されます。
もし \(a\) が0に近ければ、PReLUはReLUに近い動きをします。反対に \(a\) が少し大きくなれば、負の入力もより強く出力へ反映されます。この調整により、データの性質に応じた表現が可能になります。
ReLUの課題であるdying ReLU
ReLUは「入力が正ならそのまま、負なら0」という単純な関数です。計算が速く、深層学習で広く使われてきました。しかし、負の入力に対して出力も勾配も0になるため、学習中に一部のニューロンがほとんど更新されなくなることがあります。
この状態はdying ReLU問題と呼ばれます。学習率が大きすぎる場合や、データの分布によって特定のニューロンに負の入力が続く場合に起こりやすくなります。ニューロンが常に0を出力するようになると、そのニューロンは特徴抽出に貢献しにくくなります。

PReLUは、負の入力でも完全に0にせず小さな出力を返します。そのため、負の領域にも勾配が残り、ニューロンが完全に学習から外れてしまうリスクを抑えられます。
ReLU・Leaky ReLU・PReLUの違い
PReLUを理解するには、ReLUとLeaky ReLUとの違いを押さえるのが近道です。3つはいずれもReLU系の活性化関数ですが、負の入力をどう扱うかが異なります。
| 活性化関数 | 負の入力への出力 | 係数の扱い | 特徴 |
|---|---|---|---|
| ReLU | 0 | なし | 計算が単純だがdying ReLUが起きることがある |
| Leaky ReLU | 小さな係数を掛けた値 | 固定値 | 負の領域にも一定の傾きを残す |
| PReLU | 学習された係数を掛けた値 | 学習で更新 | データに合わせて負の傾きを調整できる |
Leaky ReLUでは、負の入力に掛ける係数を0.01などの固定値として設定します。PReLUでは、この係数をモデルが学習します。つまり、Leaky ReLUは「負側にも少し通す」と決め打ちする方法で、PReLUは「どのくらい通すべきかをデータから決める」方法です。
係数を学習する柔軟性
PReLUの強みは、負の入力に対する反応をデータに合わせて調整できることです。あるタスクでは負の値が重要な特徴を含むかもしれませんし、別のタスクではノイズに近いかもしれません。PReLUは係数を学習することで、その違いに対応しやすくなります。
たとえば画像認識では、畳み込み層の出力に負の値が現れることがあります。その値がエッジや質感のような特徴を示しているなら、完全に0へ切り捨てるより、適度に残したほうが表現力を保てる可能性があります。
一方で、負の値が不要なノイズに近い場合は、係数が小さくなることでReLUに近い挙動になります。このようにPReLUは、ReLUの単純さと、データ適応の柔軟性を両立しようとする関数です。
PReLUが使われる場面
PReLUは、主に深層ニューラルネットワークで活性化関数の選択肢として使われます。特に、画像認識のように多層の特徴抽出を行うモデルでは、ReLU系の関数を少し変えるだけで学習の安定性や精度に影響することがあります。

元記事でも触れられているように、画像認識、自然言語処理、音声認識など、AIが関わる幅広い分野で活用が期待されます。ただし、PReLUを使えば必ず性能が上がるわけではありません。データ量、モデル構造、正則化、学習率などの条件によって結果は変わります。
実務や学習で試す場合は、まずReLUを基準にし、dying ReLUが疑われるときや精度改善を検討したいときに、Leaky ReLUやPReLUを比較するのが現実的です。
使うときの注意点
PReLUは係数を学習できるぶん、ReLUよりもパラメータが増えます。増加量は大きくないことが多いものの、モデルや層の設定によっては過学習やチューニングの複雑化につながる可能性があります。
また、負の傾きをどの単位で持たせるかにも注意が必要です。層ごとに1つの係数を共有する設計もあれば、チャネルごとに係数を持たせる設計もあります。細かく係数を持たせるほど表現力は増えますが、そのぶん管理するパラメータも増えます。
初心者が押さえるべきポイントは、PReLUはReLUの完全な上位互換ではなく、比較検証すべき選択肢の一つだということです。まずはReLU、Leaky ReLU、PReLUの違いを理解し、同じ条件で性能や学習の安定性を比べると判断しやすくなります。
まとめ
PReLUは、ReLUの負の入力側に学習可能な係数を加えた活性化関数です。正の入力ではReLUと同じようにそのまま出力し、負の入力では係数を掛けた値を出力します。
この仕組みにより、dying ReLU問題を抑えながら、データに合わせて負の領域の扱いを調整できます。ReLUやLeaky ReLUとの違いは、負の入力を0にするのか、固定係数で通すのか、学習可能な係数で通すのかにあります。
PReLUは画像認識などで有効に働くことがありますが、常に最適とは限りません。活性化関数を選ぶときは、タスク、データ、モデル規模、過学習の有無を見ながら、ReLU系の候補を比較して選ぶことが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月12日 | ReLUとの差分、式の読み方、係数学習の注意点を追記 |