活性化関数とは?ニューラルネットワークで重要な理由

AIの初心者
「活性化関数」って、ニューラルネットワークのどこで使われるものですか?

AI専門家
活性化関数は、ニューラルネットワークの層から層へ渡す値を変換し、信号の強さを調整する関数です。単に数値を受け渡すのではなく、次の層へどのような形で情報を伝えるかを決める役割があります。
AIの初心者
信号を調整するだけなら、なぜそんなに重要なんですか?
AI専門家
活性化関数があることで、ニューラルネットワークは複雑な関係を学習しやすくなります。シグモイド関数、ReLU関数、ソフトマックス関数などを目的に応じて使い分けることで、分類や予測の性能に大きく関わります。
活性化関数とは。
活性化関数とは、ニューラルネットワークの各層で計算された値を変換し、次の層へ渡す信号を調整する関数です。入力をそのまま流すだけでなく、必要な情報を強めたり弱めたりすることで、AIが複雑なパターンを学習できるようにします。
活性化関数の役割
ニューラルネットワークでは、入力データに重みを掛け、バイアスを足した値が次の層へ送られます。このとき、その値をどのように次の層へ渡すかを決めるのが活性化関数です。人間の神経細胞が一定以上の刺激に反応するように、人工ニューラルネットワークでも、入力に応じて出力の形を変える仕組みが必要になります。
活性化関数の大きな役割は、ニューラルネットワークに非線形性を加えることです。非線形性とは、入力と出力が単純な比例関係だけでは表せない性質を指します。画像の中から顔を見つける、文章の意味を読み取る、音声の特徴を識別するといった処理は、単純な直線的な計算だけでは扱いにくい問題です。
もし活性化関数がなければ、何層も重ねたニューラルネットワークでも、結局は線形変換を何度も行っているだけに近くなります。層を深くした意味が薄れ、複雑な境界や特徴を表現しにくくなります。そのため活性化関数は、AIの表現力と学習能力を支える基本部品といえます。
| 観点 | 説明 |
|---|---|
| 信号の調整 | 層で計算された値を変換し、次の層へ渡す出力を決める。 |
| 非線形性の追加 | 直線的な関係だけでは表せない複雑なパターンを扱えるようにする。 |
| 学習への影響 | 学習速度、精度、勾配の伝わり方に影響するため、関数選びが重要になる。 |
なぜ活性化関数が必要なのか

機械学習で扱うデータは、きれいな直線だけで分けられるとは限りません。例えば、画像内の物体、音声の波形、自然言語の文脈は、多くの特徴が複雑に絡み合っています。このような問題を扱うには、入力に対して曲線的、段階的、または条件に応じた変化を与える仕組みが必要です。
活性化関数は、層ごとの計算結果に変化を加えることで、ニューラルネットワークが複雑な形の判断境界を作れるようにします。これにより、単純な「大きい・小さい」だけではなく、特徴の組み合わせや微妙な違いを学習しやすくなります。
初心者が押さえておきたい点は、活性化関数は飾りではなく、モデルの表現力そのものに関わるということです。どの関数をどこに使うかによって、学習が速くなることもあれば、逆に学習が進みにくくなることもあります。
代表的な活性化関数の種類
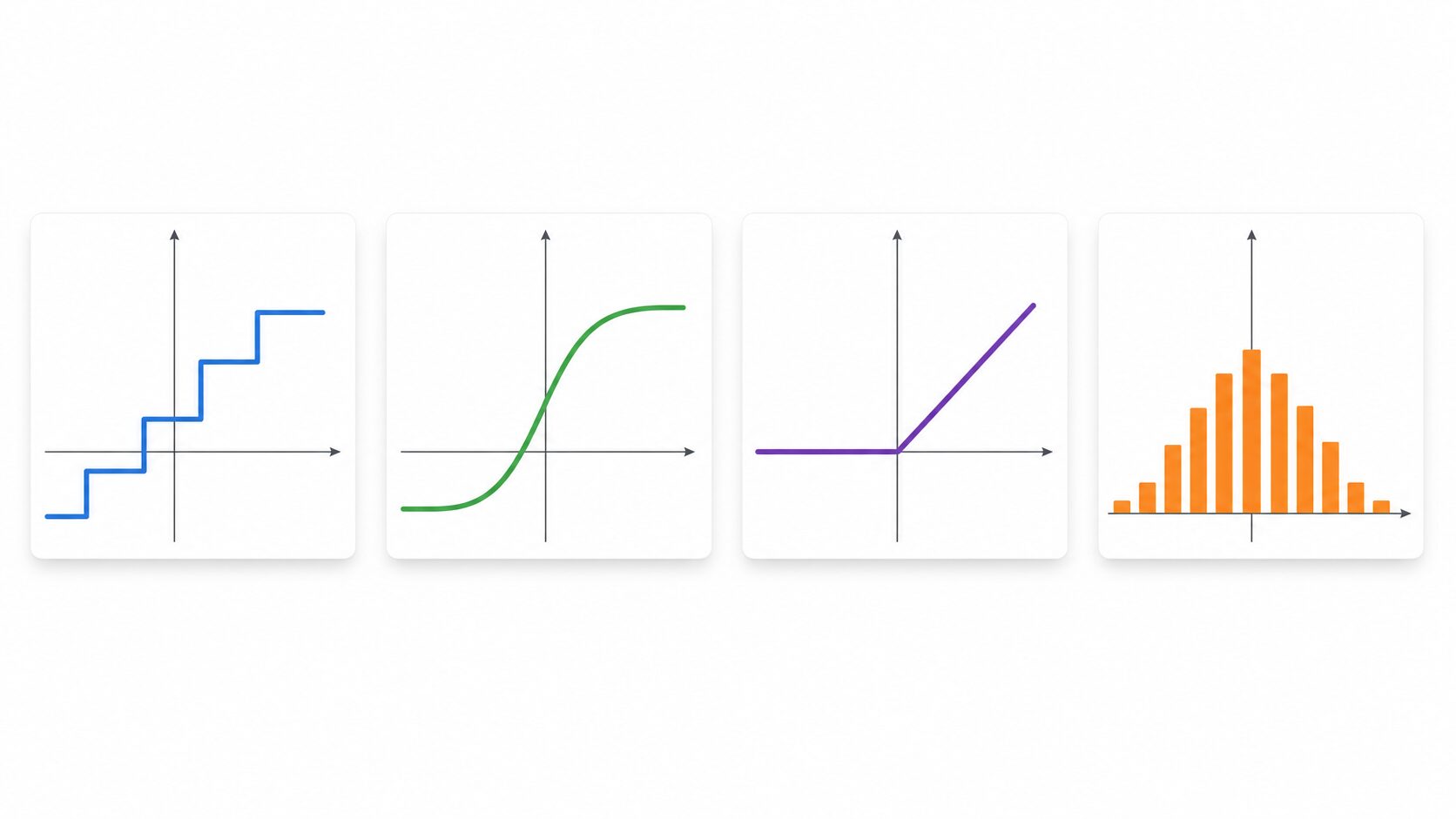
活性化関数には多くの種類がありますが、まずは階段関数、シグモイド関数、ReLU関数、ソフトマックス関数の違いを理解すると全体像をつかみやすくなります。それぞれ出力の形や使われる場所が異なるため、名前だけで覚えるよりも「何に向いているか」で整理するのが実用的です。
| 活性化関数 | 特徴 | 主な使いどころ | 注意点 |
|---|---|---|---|
| 階段関数 | しきい値を超えると1、超えなければ0を出力する。 | 初期のパーセプトロンの説明、概念理解。 | 出力が急に切り替わるため、勾配を使う学習には向きにくい。 |
| シグモイド関数 | 入力を0から1の範囲へ滑らかに変換する。 | 二値分類の出力、確率らしい値を扱いたい場面。 | 値が極端に大きい、または小さいと勾配が小さくなりやすい。 |
| tanh関数 | 入力を-1から1の範囲へ変換する。 | 中心が0に近い出力を扱いたい場面。 | シグモイドと同様に勾配消失に注意が必要。 |
| ReLU関数 | 入力が正ならそのまま、負なら0を出力する。 | 深層学習の隠れ層で広く使われる。 | 負の入力が続くと一部のニューロンが学習しにくくなることがある。 |
| ソフトマックス関数 | 複数の出力を合計1の確率分布に変換する。 | 多クラス分類の出力層。 | 各クラスが排他的な分類問題で使うのが基本。 |
シグモイド関数の特徴
シグモイド関数は、入力値を0から1の範囲に滑らかに変換する活性化関数です。出力が0に近ければ「可能性が低い」、1に近ければ「可能性が高い」と解釈しやすいため、二値分類の出力層でよく説明されます。例えば「画像に猫が写っているか」を判定する場合、0.9なら猫である可能性が高い、0.1なら低い、というように読み取れます。
一方で、シグモイド関数には勾配消失問題が起こりやすいという弱点があります。入力が非常に大きい、または非常に小さい領域では曲線がほぼ水平になり、学習時に修正の手がかりとなる勾配が小さくなります。特に層が深いネットワークでは、この影響が積み重なり、学習が進みにくくなることがあります。
そのため、現在の深層学習では、隠れ層にシグモイド関数を多用するよりも、ReLU関数やその改良版を使うことが多くなっています。ただし、出力を0から1に収めたい場面では今でも重要です。シグモイド関数は「古いから不要」ではなく、適した場所で使う関数と考えるのが正確です。
ReLU関数と改良版
ReLU関数は、入力が0より大きければその値をそのまま出力し、0以下なら0を出力する活性化関数です。計算が単純で、深いニューラルネットワークでも勾配が比較的伝わりやすいため、画像認識など多くの深層学習モデルの隠れ層で使われてきました。
ReLUの利点は、処理が軽く、学習が速く進みやすいことです。シグモイド関数のように両端で勾配が極端に小さくなる問題を避けやすく、実装上も扱いやすい関数です。ただし、入力が負の範囲に偏ると出力が0のままになり、そのニューロンがほとんど学習しなくなることがあります。これはDying ReLUと呼ばれる問題です。
この弱点を補うために、Leaky ReLU、ELU、GELU、Swish、Mishなどの改良版や関連する関数が使われることもあります。初心者の段階では、まずReLUを隠れ層の基本候補として理解し、必要に応じて改良版を検討する、という順番で学ぶと整理しやすくなります。
ソフトマックス関数の利点
ソフトマックス関数は、複数の出力値を確率のように解釈できる形へ変換する関数です。例えば、画像を「犬」「猫」「鳥」のどれかに分類するモデルでは、出力層に3つの値が出ます。そのままでは単なるスコアですが、ソフトマックス関数を通すと、犬70%、猫20%、鳥10%のように合計が1になる形で表せます。
ソフトマックス関数は、多クラス分類の出力層で特に重要です。複数の候補のうち、どれが最も可能性が高いかを比較しやすくなるため、画像認識、自然言語処理、音声認識など幅広い分野で使われます。
シグモイド関数との違いも押さえておきましょう。シグモイド関数は各出力を独立に0から1へ変換するため、複数のラベルが同時に当てはまる問題にも使われます。一方、ソフトマックス関数は全体の合計が1になるように調整するため、基本的には「犬・猫・鳥のうち1つを選ぶ」のような排他的な多クラス分類に向いています。
シグモイド、ReLU、ソフトマックスの使い分け

活性化関数を選ぶときは、関数そのものの有名さではなく、層の位置とタスクの種類を基準に考えます。隠れ層では特徴を学習しやすくすることが重要なので、ReLU関数やその改良版がよく候補になります。二値分類の出力層では、0から1の値に変換できるシグモイド関数が使われます。多クラス分類の出力層では、確率分布として解釈しやすいソフトマックス関数が基本です。
回帰問題のように連続値をそのまま予測したい場合は、出力層で活性化関数を使わない、または恒等関数として扱うこともあります。例えば売上金額や気温のように、出力範囲を0から1に限定したくない場合は、シグモイド関数を無理に使うと表現できる値の範囲が狭くなってしまいます。
| 目的 | よく使われる関数 | 考え方 |
|---|---|---|
| 隠れ層で特徴を学習する | ReLU、Leaky ReLU、GELUなど | 勾配が伝わりやすく、学習を進めやすい関数を選ぶ。 |
| 二値分類を行う | シグモイド関数 | 出力を0から1に収め、陽性・陰性の確率のように扱う。 |
| 多クラス分類を行う | ソフトマックス関数 | 複数クラスのスコアを合計1の確率分布に変換する。 |
| 連続値を予測する | 恒等関数、または出力層では関数を使わない | 予測値の範囲を不必要に制限しない。 |
初心者が注意したいポイント
活性化関数を学ぶときは、「どの関数が最も優れているか」と考えすぎないことが大切です。実際には、データの性質、ネットワークの深さ、出力の形式、損失関数との組み合わせによって適した関数が変わります。まずは、隠れ層ならReLU系、二値分類ならシグモイド、多クラス分類ならソフトマックスという基本を押さえるとよいでしょう。
また、活性化関数は単独で性能を決めるものではありません。重みの初期化、正規化、学習率、損失関数、データの前処理などとも関係します。学習がうまく進まない場合は、活性化関数だけでなく、周辺の設定も一緒に見直す必要があります。
特に勾配消失問題は、初心者がニューラルネットワークを理解するうえで重要な概念です。勾配が小さくなりすぎると、モデルがどの方向へ修正すればよいかを学びにくくなります。シグモイド関数やtanh関数を深い層で使うときは、この点に注意が必要です。
活性化関数の今後
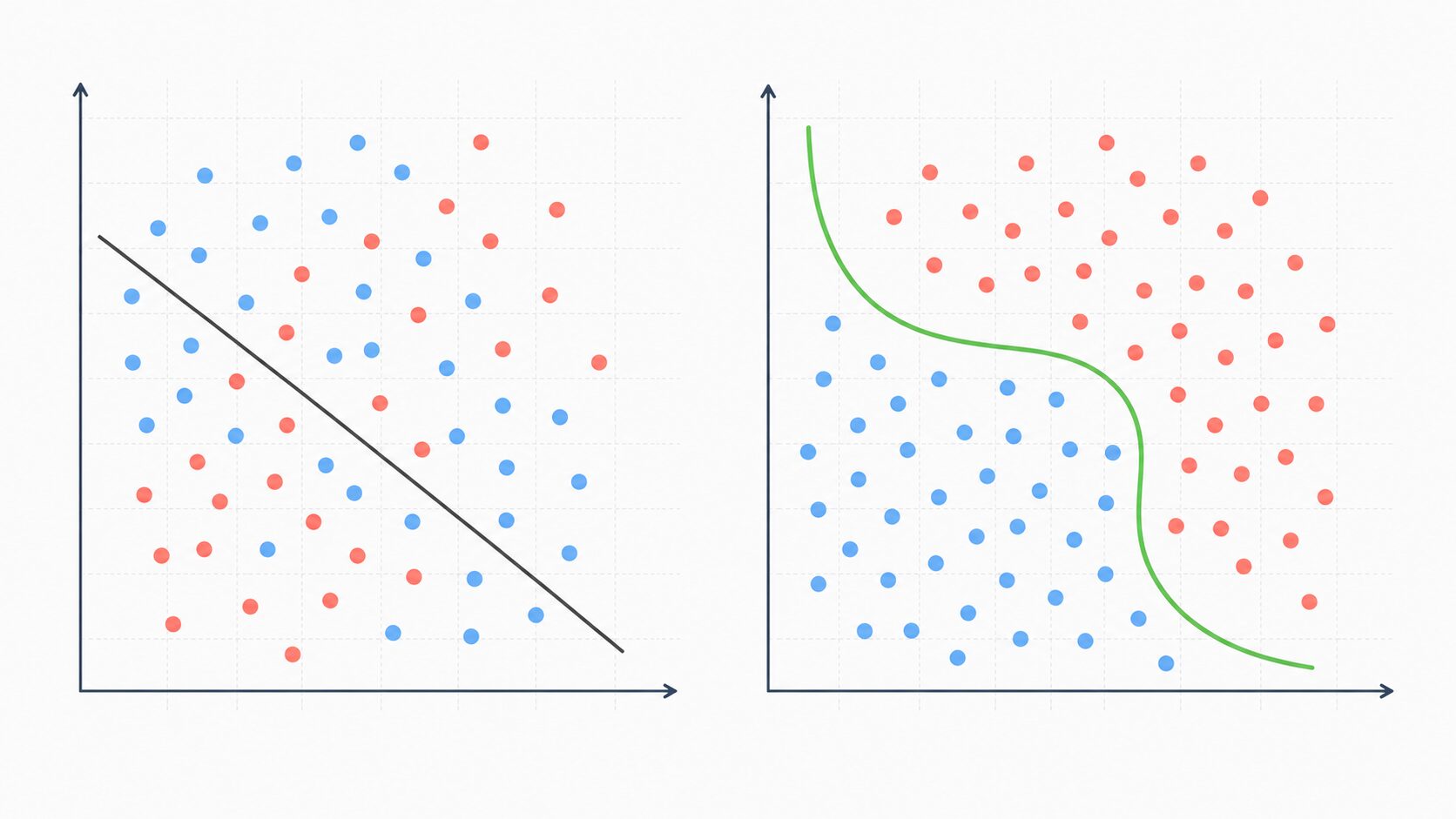
活性化関数の研究は現在も続いています。ReLU関数は計算が軽く実用的ですが、すべての問題に最適というわけではありません。そのため、Swish、Mish、GELUのように、滑らかさや勾配の伝わり方を改善しようとする関数が提案されてきました。
さらに、モデルやデータに合わせて活性化関数の形を自動的に調整する考え方も研究されています。これは、固定された関数を人間が選ぶだけでなく、学習対象に応じてより良い変換の形を探す方向です。今後、ニューラルネットワークがより複雑なタスクを扱うほど、活性化関数の設計や選択は重要なテーマであり続けるでしょう。
まとめ
活性化関数は、ニューラルネットワークの層間で信号を変換し、モデルに非線形性を加える重要な仕組みです。これにより、AIは画像、音声、文章のような複雑なデータから特徴を学習しやすくなります。
代表的な関数には、シグモイド関数、ReLU関数、ソフトマックス関数などがあります。シグモイドは二値分類、ReLUは隠れ層、ソフトマックスは多クラス分類の出力層でよく使われます。活性化関数は一つを暗記するのではなく、どの層で、どの目的に使うのかを基準に理解することが大切です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月1日 | 活性化関数の定義、非線形性、代表的な種類、シグモイド・ReLU・ソフトマックスの違い、選び方を初心者向けに再構成 |