プルーニングとは?ニューラルネットワークを軽量化する仕組みをわかりやすく解説

AIの初心者
AIの「刈り込み」や「プルーニング」って、何をする技術なんですか?

AI専門家
プルーニングは、ニューラルネットワークの中で重要度が低い接続や部品を取り除き、モデルを小さく軽くする技術だよ。庭木の余分な枝を整える剪定に近い考え方だね。
AIの初心者
接続を減らしてしまっても、AIはきちんと動くんですか?
AI専門家
削りすぎると精度は落ちるけれど、影響の小さい部分を選んで取り除き、必要に応じて再学習すれば、性能を大きく落とさずに計算量やメモリ使用量を減らせるんだ。
プルーニングとは。
プルーニングは、ニューラルネットワークを構成する重み、接続、ニューロン、フィルターなどのうち、結果への影響が小さい部分を取り除くモデル圧縮手法です。学習済みモデルを軽くし、推論を速くしたり、スマートフォンやIoT機器のような限られた環境で動かしやすくしたりする目的で使われます。
プルーニングとは何か
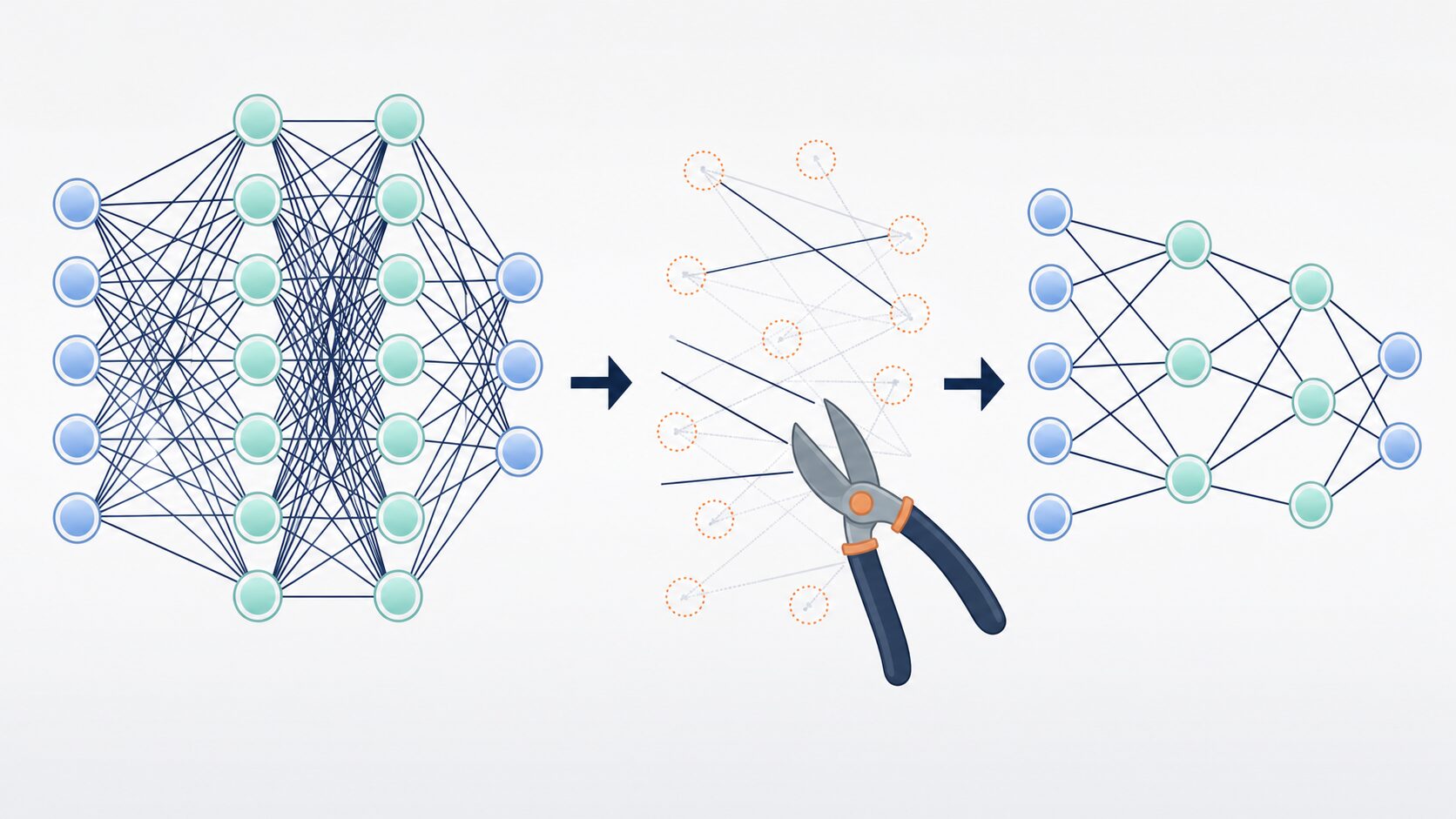
プルーニングとは、ニューラルネットワークの中で重要度が低い部分を削り、モデルを小さくする軽量化技術です。英語の prune には「枝を切る」という意味があり、機械学習では、庭木の剪定のように不要な枝を落として全体を整える考え方にたとえられます。
ニューラルネットワークは、多数のパラメータが層ごとにつながって計算を行います。画像認識であれば画像の特徴を取り出すフィルター、文章処理であれば単語や文脈を扱う重みなどが大量に存在します。しかし、すべてのパラメータが同じだけ重要とは限りません。学習後のモデルには、ほとんど結果に影響しない接続や、似た働きをしている部品が含まれることがあります。
プルーニングでは、そうした部分を選んで削除または無効化します。うまく行えば、精度を大きく落とさずにモデルサイズ、計算量、メモリ使用量を減らせます。そのため、ニューラルネットワークの軽量化、モデル圧縮、エッジAIの実装を考えるときに重要な手法の一つです。
なぜニューラルネットワークを軽量化できるのか
多くのニューラルネットワークは、学習時に十分な表現力を持たせるため、やや大きめに設計されます。大きなモデルは高い性能を出しやすい一方で、保存容量、推論時間、消費電力が増えます。プルーニングは、学習後に「この部分は出力への影響が小さい」と判断できる要素を減らすことで、実用時の負担を下げます。
代表的な方法は、重みの絶対値を見るやり方です。重みが小さい接続は、入力から出力へ伝える影響が小さい可能性があります。そこで、あらかじめ決めたしきい値より小さい重みをゼロにしたり、接続そのものを取り除いたりします。ただし、重みが小さいから必ず不要とは限らないため、より高度な方法では、損失への影響、勾配、層ごとの重要度なども考慮します。
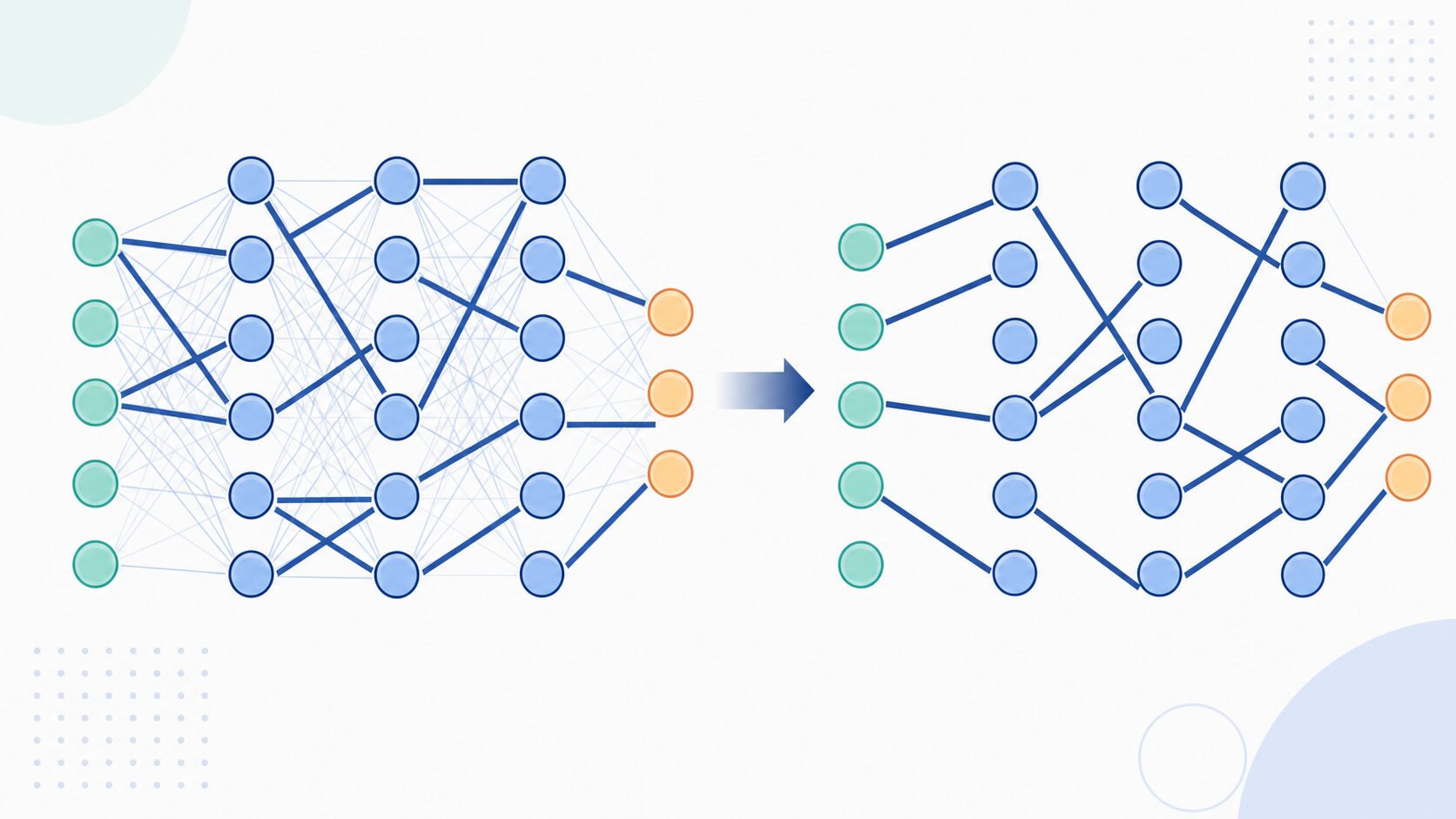
削除後のモデルは、接続がまばらな構造になります。このままでは精度が少し落ちることがあるため、再学習やファインチューニングを行い、残したパラメータで性能を回復させます。つまりプルーニングは、単に削るだけでなく、削る場所を選び、削った後の性能を確認し、必要なら調整する一連の作業です。
プルーニングの基本手順
プルーニングは、一般に次のような流れで進めます。最初に、対象タスクで十分に学習したモデルを用意します。画像分類、物体検出、文章分類、音声認識など、すでに基準となる精度を出しているモデルが出発点になります。
| 手順 | 内容 | 確認するポイント |
|---|---|---|
| 1. 学習済みモデルを用意 | 通常の学習で性能の基準となるモデルを作る | 削る前の精度、推論時間、モデルサイズを記録する |
| 2. 重要度を評価 | 重み、接続、ニューロン、フィルターの影響度を見積もる | 重みの大きさだけでなく、タスクへの影響も見る |
| 3. 不要な部分を削除 | しきい値や削除率に従って一部をゼロ化または除去する | 削りすぎで精度が急落していないか確認する |
| 4. 再学習する | 残した構造でファインチューニングし、性能を戻す | 軽量化と精度のバランスを検証する |
| 5. 必要なら繰り返す | 少しずつ削りながら目標サイズや速度に近づける | 実行環境で本当に速くなったか測る |
初心者が特に注意したいのは、削除率を一度に大きくしすぎないことです。いきなり多くの接続を取り除くと、モデルが学習した特徴まで失われ、精度が戻りにくくなります。実務では、削除率を段階的に上げ、各段階で検証データの精度や推論時間を測る進め方がよく使われます。
プルーニングで得られるメリット
プルーニングの主なメリットは、モデルを保存する容量を減らせること、推論時の計算量を減らせること、消費電力を抑えやすくなることです。これにより、クラウドサーバーだけでなく、スマートフォン、カメラ、センサー、組み込み機器などにもAIモデルを載せやすくなります。
たとえば画像認識モデルを端末上で動かす場合、大きなモデルはメモリを圧迫し、推論にも時間がかかります。プルーニングで不要な接続やフィルターを減らせば、アプリの応答速度を改善したり、バッテリー消費を抑えたりできる可能性があります。
また、過学習の抑制につながる場合もあります。過学習とは、学習データに合わせ込みすぎて、未知のデータに弱くなる状態です。プルーニングによって余分な表現力を抑え、重要な特徴に集中させることで、汎化性能が改善することがあります。ただし、常に精度が上がるわけではなく、削り方と再学習の設計に左右されます。
プルーニングの主な種類
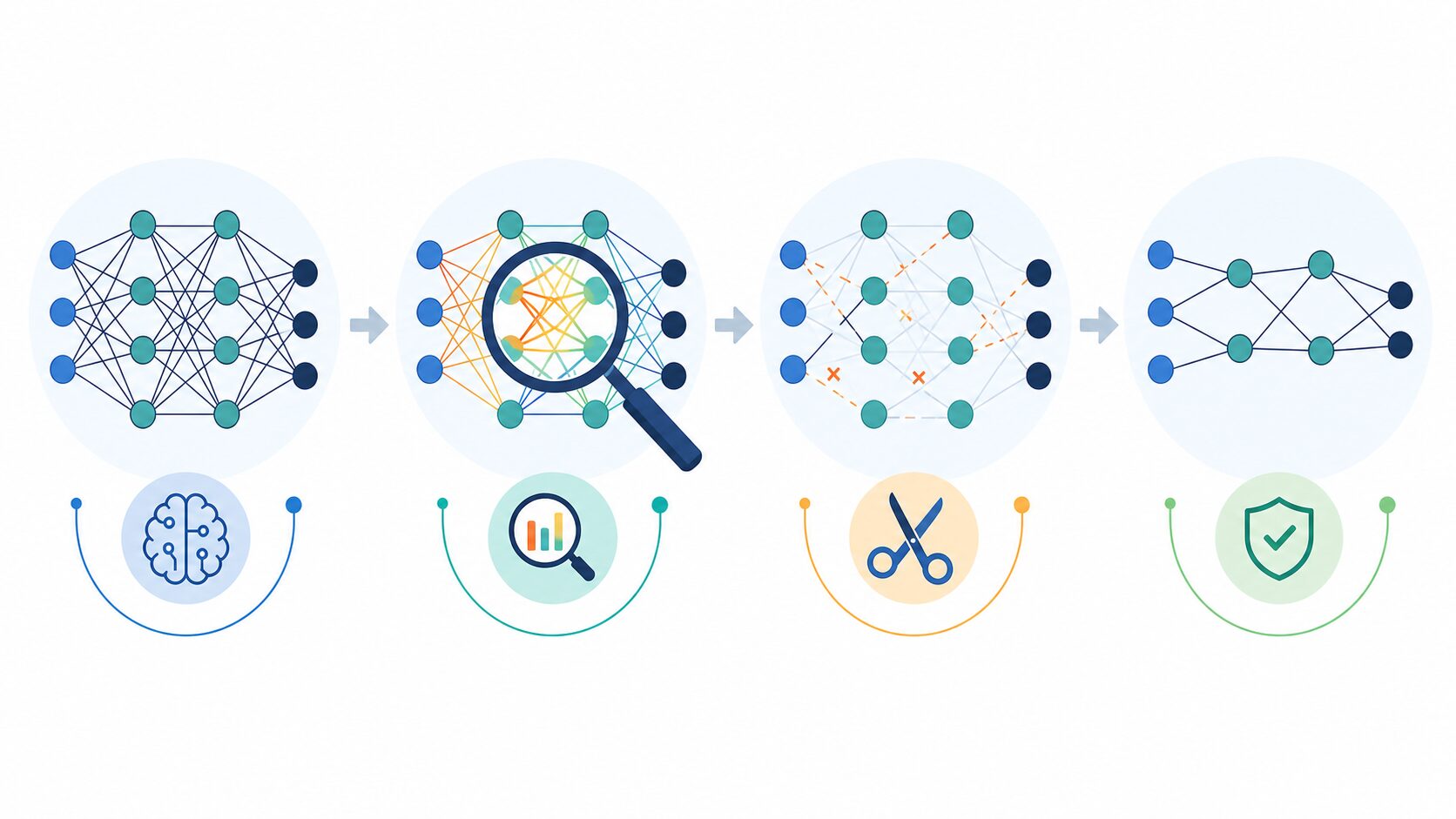
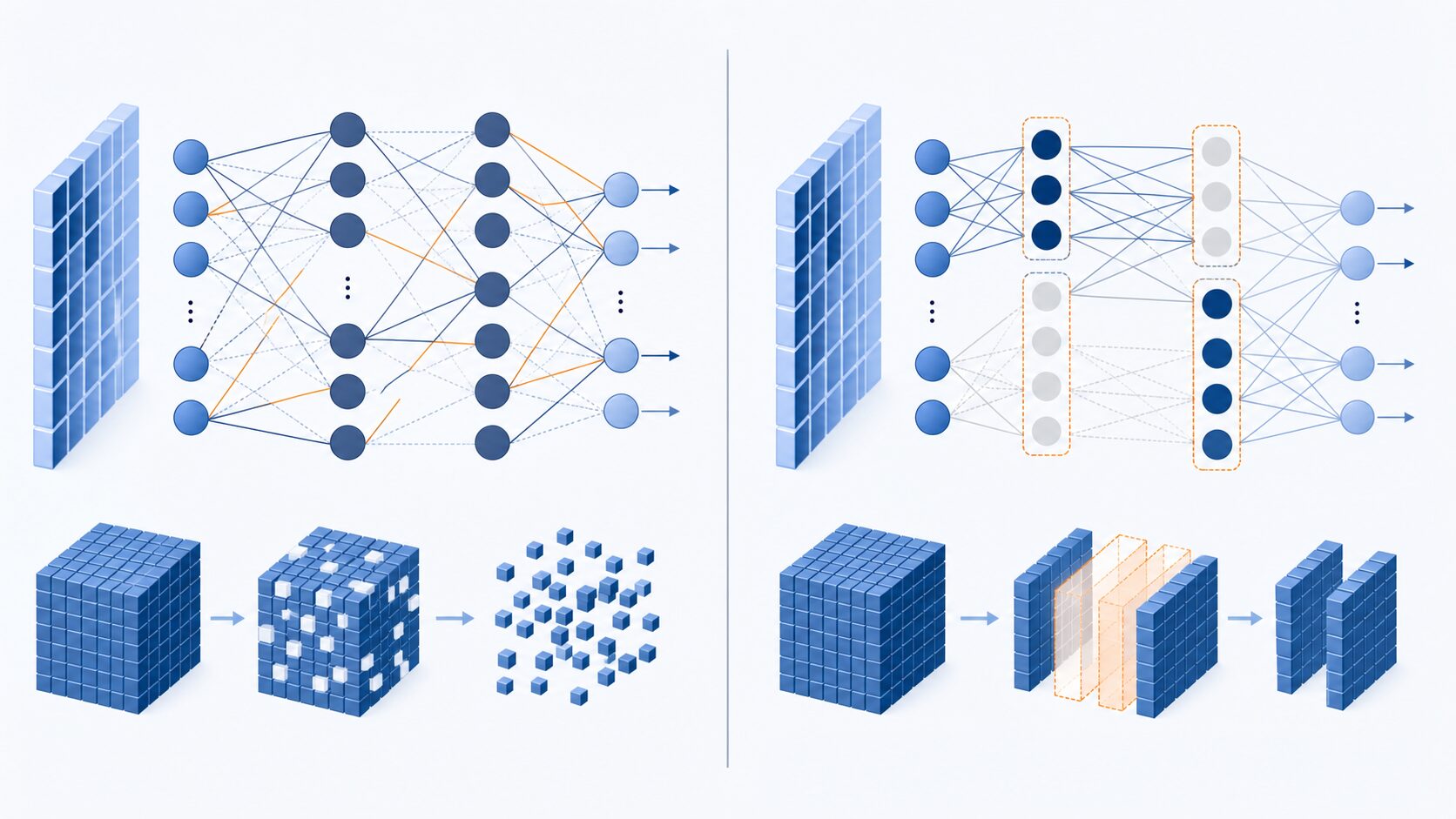
プルーニングにはいくつかの分類があります。まず重要なのが、非構造化プルーニングと構造化プルーニングの違いです。非構造化プルーニングは、個々の重みや接続を細かくゼロにします。柔軟に削れるため高い圧縮率を狙いやすい一方で、行列がまばらになるため、通常のハードウェアでは速度向上に直結しない場合があります。
構造化プルーニングは、ニューロン、チャネル、フィルター、層の一部など、まとまった単位で削ります。モデル構造そのものが小さくなるため、一般的なGPUやCPUでも高速化の効果を得やすいことがあります。その反面、重要なまとまりを削ると精度への影響が大きくなりやすく、慎重な評価が必要です。
| 分類 | 削る単位 | 特徴 | 注意点 |
|---|---|---|---|
| 非構造化プルーニング | 個々の重みや接続 | 細かく削れるため圧縮率を上げやすい | 疎行列計算に対応しない環境では速くなりにくい |
| 構造化プルーニング | ニューロン、チャネル、フィルターなど | モデル構造が小さくなり実行速度に効きやすい | 削る単位が大きく、精度低下が出やすい |
| 静的プルーニング | 学習後のモデル | 導入しやすく、既存モデルに適用しやすい | 削除後の再学習が重要になる |
| 動的プルーニング | 学習中または推論時に変化する構造 | 状況に応じて柔軟に削れる | 実装や制御が複雑になりやすい |
他の軽量化手法との違い
ニューラルネットワークの軽量化には、プルーニング以外にも量子化、知識蒸留、低ランク近似などがあります。これらは目的が似ていますが、何を変えるかが異なります。
量子化は、重みや計算に使う数値の精度を下げる方法です。たとえば32ビット浮動小数点を8ビット整数に近づけることで、メモリ使用量や計算コストを減らします。プルーニングが「不要な部分を減らす」手法だとすれば、量子化は「数値を軽い表現にする」手法です。
知識蒸留は、大きな教師モデルの出力を使って、小さな生徒モデルを学習させる方法です。初めから小さいモデルを作る方向に近く、プルーニングのように既存モデルの一部を削るとは限りません。実務では、プルーニングと量子化、蒸留を組み合わせることもあります。
実務で使うときの注意点
プルーニングでは、パラメータ数が減ったからといって、必ず推論が速くなるとは限りません。特に非構造化プルーニングでは、重みがゼロになっても、実行環境がその疎な構造を効率よく扱えなければ、計算時間の削減が小さいことがあります。実際の高速化を狙うなら、利用するフレームワーク、推論エンジン、ハードウェアが疎行列や構造化削除に対応しているかを確認する必要があります。
また、評価は精度だけでは不十分です。モデルサイズ、推論レイテンシ、スループット、メモリ使用量、消費電力を、実際に使う端末やサーバーに近い環境で測ることが重要です。研究用の指標では軽く見えても、本番環境では期待した効果が出ないことがあります。
削除率の決め方にも注意が必要です。削りすぎると、画像の細かな特徴を見落としたり、文章の文脈理解が弱くなったりする可能性があります。プルーニングは「不要なものを一気に捨てる」作業ではなく、性能を見ながら少しずつ軽くしていく調整作業として扱うのが現実的です。
プルーニングの応用例
プルーニングは、画像認識、自然言語処理、音声認識、異常検知など、深層学習を使う幅広い分野で応用されています。特に効果が見えやすいのは、計算資源が限られた環境です。スマートフォン上の画像分類、監視カメラ内での物体検出、工場センサーでの異常検知などでは、クラウドへ毎回データを送らず、端末側で処理したい場面があります。
端末側でAIを動かすエッジAIでは、通信遅延を減らせること、通信できない場所でも動作しやすいこと、個人情報や機密データを外部へ送らずに済むことが利点になります。一方で、端末のメモリ、CPU、バッテリーには制約があります。プルーニングは、こうした制約の中でAIモデルを扱いやすくするための実用的な選択肢です。
また、クラウド環境でもプルーニングは有効です。大量のリクエストを処理する推論サーバーでは、1回あたりの計算量を少し減らすだけでも、全体のコストや応答時間に影響します。モデルの軽量化は、端末だけでなく、サービス運用の効率化にもつながります。
まとめ
プルーニングは、ニューラルネットワークの中で重要度が低い重みや構造を取り除き、モデルを軽くする手法です。学習済みモデルを評価し、不要な部分を削り、再学習で性能を整えることで、精度と効率のバランスを取ります。
主な目的は、モデルサイズの削減、推論速度の向上、メモリ使用量や消費電力の削減です。非構造化プルーニングと構造化プルーニングでは効果の出方が異なり、実行環境によっても結果が変わります。導入時は、精度だけでなく、実際の端末やサーバーでの速度、消費リソース、運用コストまで確認することが大切です。
AIモデルが大きく高性能になるほど、軽量化の重要性も高まります。プルーニングは、量子化や知識蒸留と並んで、ニューラルネットワークを現実のサービスや端末で使いやすくするための基本技術です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月9日 | 手順、種類、実装時の確認点を補い構成を再調整 |