バッチ正規化とは?仕組み・計算手順・標準化との違いをわかりやすく解説

AIの初心者
「バッチ正規化」って、深層学習でよく聞きますが、何をしている処理ですか?

AI専門家
簡単に言うと、ミニバッチ内のデータを平均が0、ばらつきが一定になるように整え、ニューラルネットワークが学習しやすい状態にする方法だよ。
AIの初心者
普通の標準化とは違うのですか?なぜ学習が安定するのかも知りたいです。
AI専門家
標準化は主に入力データ全体を整える処理だけれど、バッチ正規化は学習中の層の出力をミニバッチごとに整える点が特徴だよ。仕組みと計算手順を順番に見ていこう。
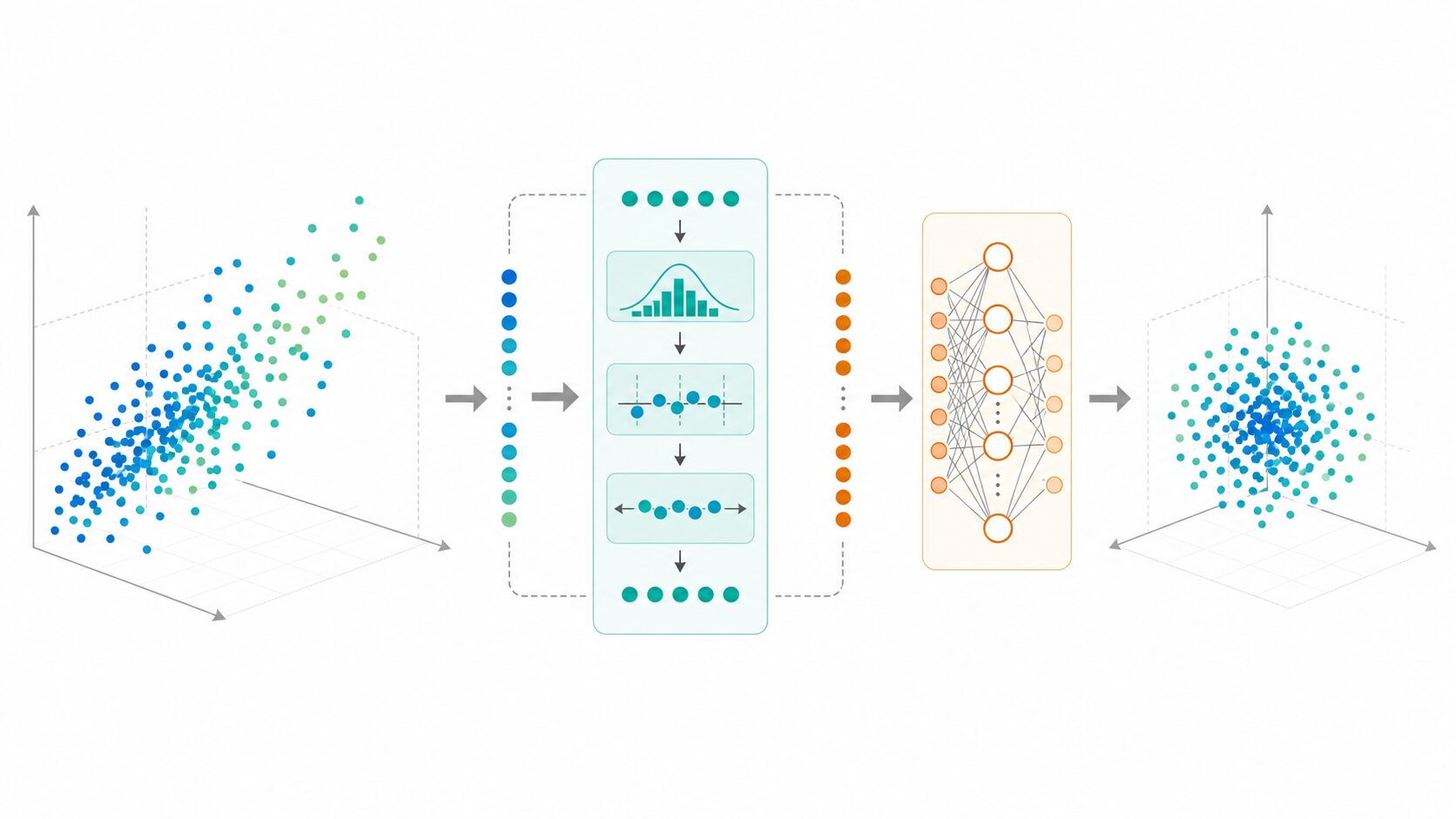
バッチ正規化とは。
バッチ正規化とは、深層学習で使われる正規化手法の一つです。英語ではBatch Normalizationと呼ばれ、ニューラルネットワークの各層に入る値を、ミニバッチ単位で扱いやすい分布に整えます。
基本的な考え方は、ミニバッチ内の値から平均と分散を求め、平均が0、分散が1に近い形へ変換することです。値の範囲が極端に偏ると学習が不安定になりやすいため、層ごとの入力を一定の範囲にそろえて、学習を進めやすくするのがバッチ正規化の役割です。
たとえばテストの点数をそのまま比べると、科目によって平均点やばらつきが違うため比較しにくいことがあります。平均点との差やばらつきを考慮して点数を調整すると、相対的な位置が見やすくなります。バッチ正規化もこれに近く、各層に流れる値を扱いやすい尺度へ整える処理です。
なぜバッチ正規化で学習が安定するのか
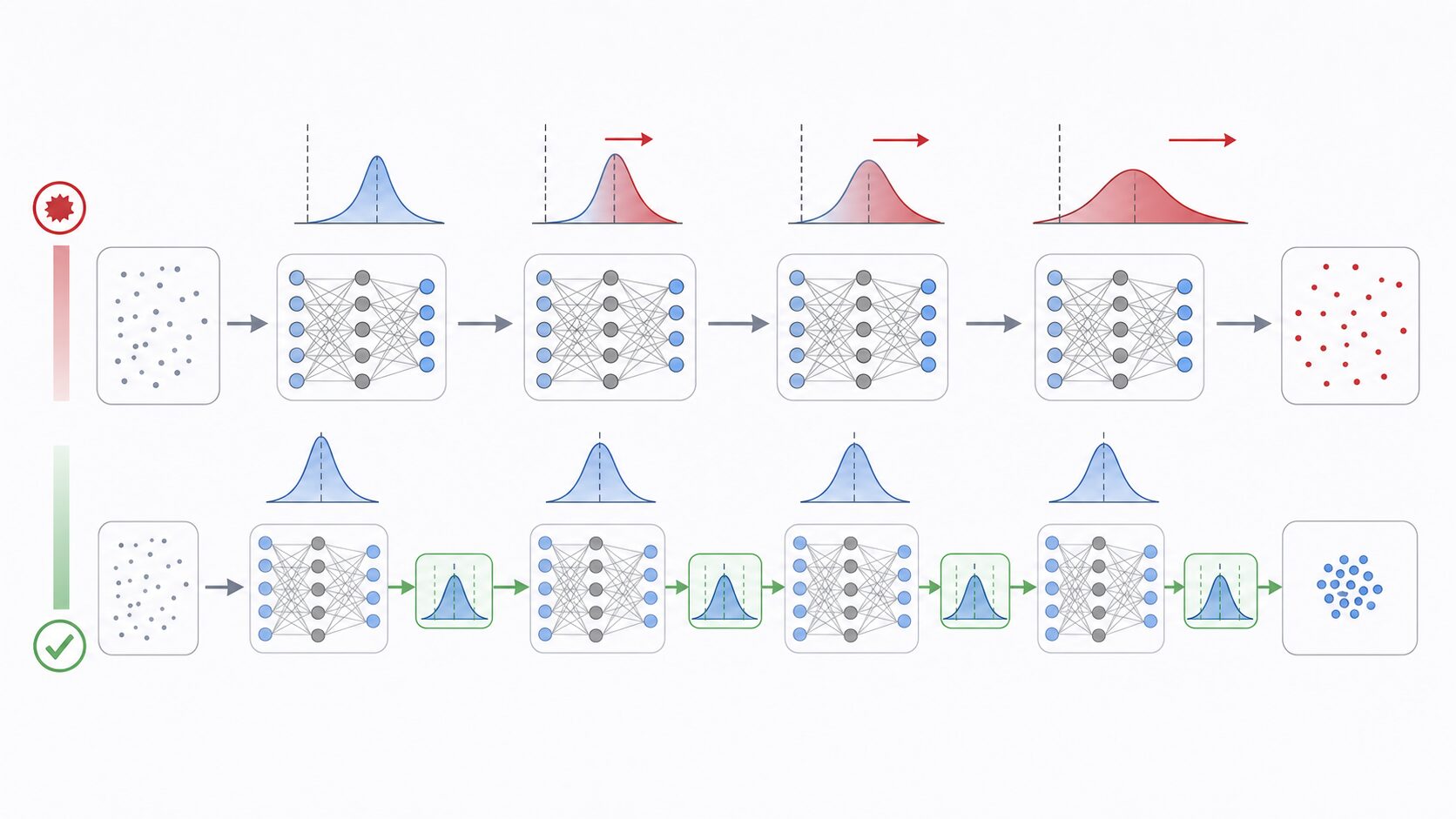
深層学習では、前の層の重みが更新されるたびに、次の層へ渡される値の分布も変わります。層が深くなるほどこの変化が積み重なり、後ろの層は毎回少し違う性質の入力を受け取ることになります。このような学習中の分布変化は、内部共変量シフトと説明されることがあります。
各層へ入る値の分布が大きく動くと、モデルは安定して重みを更新しにくくなります。値が小さくなりすぎると勾配消失が起こり、重みをほとんど更新できません。逆に値が大きくなりすぎると勾配爆発が起こり、学習が発散することがあります。
バッチ正規化は、各層の出力または入力をミニバッチごとに正規化することで、この揺れを抑えます。値の中心とばらつきがそろうため、活性化関数に入る値が極端な範囲へ寄りにくくなり、より大きな学習率を使っても学習が破綻しにくい状態を作れます。
ただし、バッチ正規化は内部共変量シフトだけを単純に取り除く魔法の処理ではありません。実際には、損失関数の地形を滑らかにし、勾配の更新を扱いやすくする効果も大きいと考えられています。初心者はまず「層に流れる値のスケールを整え、勾配更新を安定させる仕組み」と理解するとよいでしょう。
| 起こりやすい問題 | 状態 | バッチ正規化の役割 |
|---|---|---|
| 分布の変化 | 層を進むたびに値の中心やばらつきが変わる | ミニバッチごとに平均と分散を使って整える |
| 勾配消失 | 勾配が小さくなり、重みが更新されにくい | 値の範囲を保ち、学習信号を伝わりやすくする |
| 勾配爆発 | 勾配が大きくなり、学習が不安定になる | 極端な値の影響を抑え、更新を安定させる |
バッチ正規化の計算手順
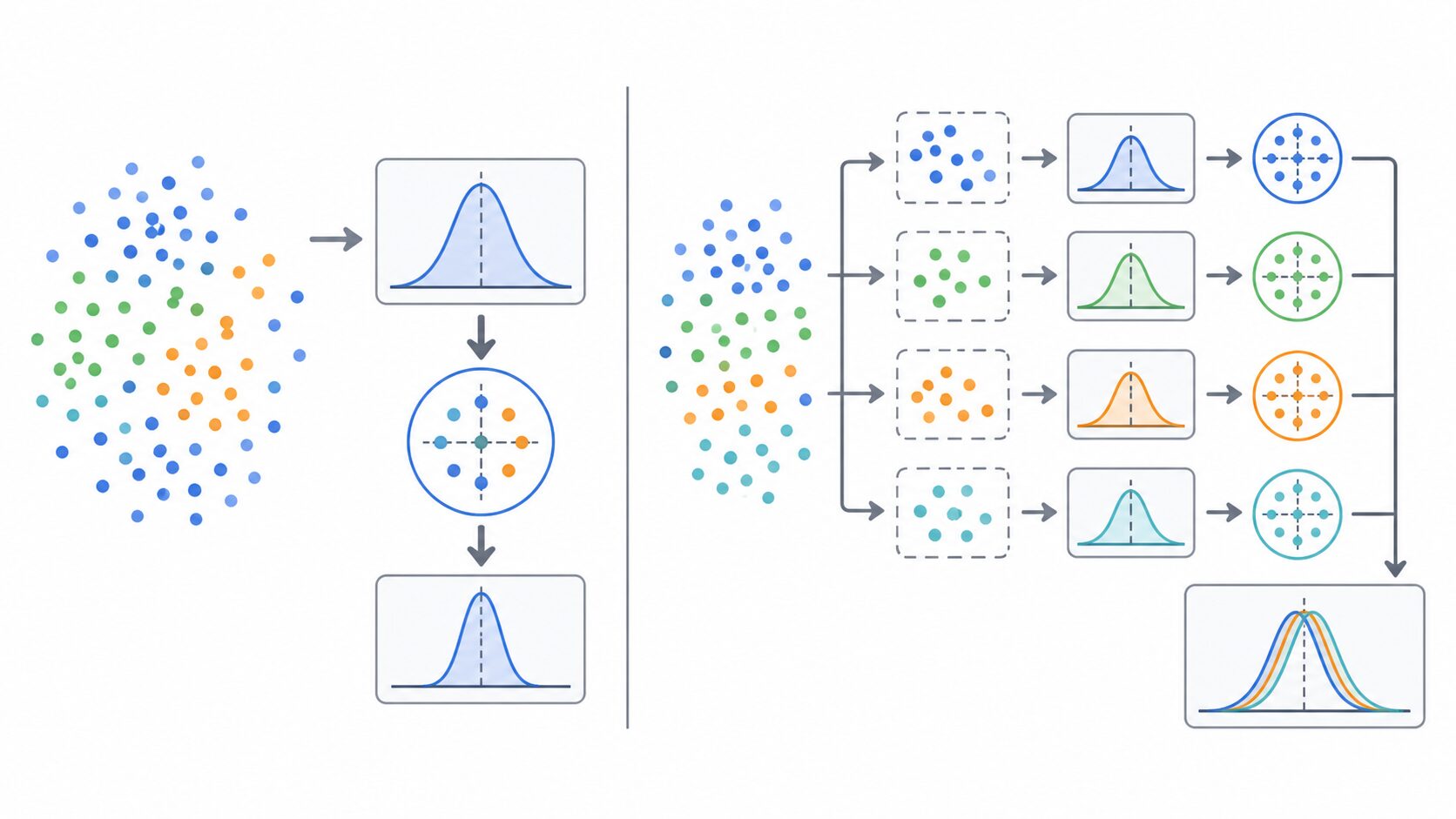
バッチ正規化の計算は、ミニバッチを単位として進みます。ミニバッチとは、学習データ全体から一度の更新に使う小さなデータのまとまりです。画像分類なら、たとえば32枚や64枚の画像をまとめて処理する単位がミニバッチになります。
まず、ミニバッチ内の値から平均を求めます。次に、平均からどれだけ値が散らばっているかを表す分散を求めます。そのうえで、各値から平均を引き、分散に小さな値を足したものの平方根で割ります。
\(x\) をミニバッチ内の値、\(\mu_B\) をミニバッチ平均、\(\sigma_B^2\) をミニバッチ分散、\(\epsilon\) をゼロ除算を避けるための小さな値とすると、正規化後の値 \(\hat{x}\) は次のように表せます。
\(\hat{x}=\frac{x-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}\)このままだと、すべての値が平均0、分散1に近い形へ強く制約されます。そこでバッチ正規化では、正規化後の値に対してスケール \(\gamma\) とシフト \(\beta\) を適用します。
\(y=\gamma\hat{x}+\beta\)\(\gamma\) と \(\beta\) は学習によって調整されるパラメータです。つまり、バッチ正規化は値を単に固定するだけではなく、必要に応じてモデルが適切なスケールや位置を取り戻せるようにしています。これにより、正規化による安定性とニューラルネットワークの表現力を両立できます。
標準化との違い
標準化とバッチ正規化は、どちらも値の平均やばらつきをそろえる処理です。しかし、対象とするデータ、使われる場所、計算のタイミングが異なります。
一般的な標準化は、学習前の前処理として入力データ全体に対して行います。たとえば身長、年齢、購入金額のように単位や値の範囲が違う特徴量を、平均0、標準偏差1に変換します。一度学習データから平均と標準偏差を求めたら、検証データやテストデータにも同じ値を使います。
一方、バッチ正規化はニューラルネットワークの層の中で使われます。入力データそのものだけでなく、層の出力である中間表現をミニバッチごとに正規化します。学習中に重みが変わると中間表現も変わるため、学習の途中で変化する値を、その場で整える点が標準化との大きな違いです。
また、バッチ正規化は学習時と推論時で扱いが変わります。学習時はミニバッチごとの平均と分散を使いますが、推論時は一件ずつ予測することも多いため、学習中に蓄積した移動平均と移動分散を使うのが一般的です。この違いを知らないと、学習時はうまく動くのに推論時の性能が不安定になる原因を見落としやすくなります。
| 項目 | 標準化 | バッチ正規化 |
|---|---|---|
| 主な対象 | 入力データ全体 | 層の入力または出力 |
| 計算単位 | 学習データ全体の統計量 | ミニバッチごとの統計量 |
| 使う場面 | 学習前の前処理 | ニューラルネットワーク内部 |
| 推論時の扱い | 学習時に求めた平均と標準偏差を使う | 学習中に蓄積した移動平均と移動分散を使う |
| 主な目的 | 特徴量の尺度をそろえる | 学習中の分布変化を抑えて更新を安定させる |
効果と利点
バッチ正規化の代表的な利点は、学習の安定化と高速化です。値の分布が整うことで、勾配の更新が極端になりにくく、収束までのステップ数を減らせる場合があります。特に深いニューラルネットワークでは、層を重ねるほど値のスケールが崩れやすいため、バッチ正規化の効果が見えやすくなります。
次に、初期値への依存を軽くできる点も重要です。ニューラルネットワークは重みの初期値によって学習の進み方が変わりますが、各層の値が正規化されることで、初期値が多少違っても学習が破綻しにくくなります。これは、モデル設計や実験を進めるうえで大きな助けになります。
さらに、ミニバッチごとに平均と分散が少しずつ変わるため、学習中の値に軽いノイズが入るような効果もあります。この性質により、過学習を抑える正則化効果が期待できます。ただし、Dropoutやデータ拡張の完全な代替ではありません。汎化性能を高めたい場合は、タスクやデータ量に応じて他の手法と組み合わせて考える必要があります。
実務では、画像認識の畳み込みニューラルネットワークでよく使われてきました。学習が不安定なとき、収束が遅いとき、深いモデルで勾配の扱いが難しいときに、バッチ正規化は有力な選択肢になります。
使うときの注意点
バッチ正規化は便利ですが、どの状況でも必ず最適とは限りません。特に注意したいのはバッチサイズです。ミニバッチが小さすぎると、平均や分散の推定が不安定になります。統計量が毎回大きく揺れると、正規化そのものがノイズになり、かえって学習を乱すことがあります。
また、学習時と推論時の動作差にも注意が必要です。推論時にはミニバッチの統計量ではなく、学習中に蓄積した移動平均と移動分散を使うのが一般的です。学習モードと推論モードの切り替えを誤ると、予測結果が不安定になることがあります。フレームワークでは、学習時はtrainモード、推論時はevalモードのように明示的に切り替える場面があります。
時系列データや自然言語処理、強化学習のように、ミニバッチの構成やデータの依存関係が複雑な場合も慎重に扱います。バッチ内の統計量に依存する性質が、タスクによっては望ましくない影響を与えることがあるためです。
初心者は、バッチ正規化を入れれば必ず精度が上がると考えるより、学習を安定させるための選択肢の一つとして見るとよいでしょう。バッチサイズ、学習率、正則化、活性化関数、モデル構造と合わせて調整することが大切です。
関連する正規化手法と今後の展望
バッチ正規化のほかにも、深層学習ではさまざまな正規化手法が使われます。Layer Normalizationは、バッチ方向ではなく特徴量方向に正規化するため、バッチサイズの影響を受けにくい特徴があります。Transformer系のモデルで広く使われるのは、この性質が関係しています。
Instance Normalizationは、主に画像生成やスタイル変換で使われることがあります。Group Normalizationは、チャネルをグループに分けて正規化する方法で、小さいバッチサイズでも比較的安定しやすい手法として知られています。
どの正規化手法がよいかは、モデルの種類、データの性質、バッチサイズ、計算資源によって変わります。画像認識ではバッチ正規化が強い選択肢になることが多い一方、系列データや大規模言語モデルではLayer Normalization系の手法が使われることも多くあります。
今後も、より小さいバッチでも安定して学習できる方法、推論時の挙動を扱いやすくする方法、正規化を使わずに安定した深いモデルを作る方法などが研究されていくでしょう。バッチ正規化は、深層学習の発展を支えてきた基本技術として、他の正規化手法を理解する入口にもなります。
| 手法 | 特徴 | 使われやすい場面 |
|---|---|---|
| Batch Normalization | ミニバッチ方向の統計量を使う | 画像認識、畳み込みニューラルネットワーク |
| Layer Normalization | 各サンプル内の特徴量方向で正規化する | Transformer、自然言語処理、系列モデル |
| Instance Normalization | サンプルごと、チャネルごとに正規化する | 画像生成、スタイル変換 |
| Group Normalization | チャネルをグループに分けて正規化する | 小さいバッチサイズでの画像モデル |
まとめ
バッチ正規化は、深層学習の学習中にミニバッチごとの平均と分散を使って値の分布を整える手法です。各層に流れる値のスケールを安定させることで、勾配消失や勾配爆発を抑え、学習速度や収束の安定性を改善しやすくなります。
一方で、標準化とは対象やタイミングが異なり、バッチサイズや推論時の移動平均にも注意が必要です。バッチ正規化の仕組みを理解しておくと、Layer NormalizationやGroup Normalizationなど、他の正規化手法との使い分けも見通しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月31日 | 計算式、推論時の扱い、関連手法の比較を追記 |