サンプリング:データ活用の鍵

AIの初心者
『サンプリング』って、データの一部を取り出すってことですよね? どうすれば全体の様子がわかるんですか?

AI専門家
いい質問ですね。全体を調べなくても、一部をうまく取り出せば全体の様子を推測できるんです。例えば、大きな鍋で作ったカレーの味見をする時、鍋全体を食べるんじゃなくて、スプーン一杯で味見をすれば全体の味もだいたい想像できますよね?
AIの初心者
なるほど。でも、カレーと違ってデータだと偏りがあるかもしれないですよね?
AI専門家
その通り!偏りがないように、まんべんなく取り出すことが重要なんです。例えば、カレーの中に大きなじゃがいもが入っていたとして、スプーンですくったところにたまたまじゃがいもがなかったら、カレーの味を正しく推測できないかもしれません。だから、色んな場所から味見をするように、データも色んな種類をバランスよく取り出す工夫が必要なんです。
サンプリングとは。
『人工知能』の用語で『サンプリング』というものがあります。これは、統計調査で、全体から一部を取り出す操作のことです。統計学や機械学習では大切な技術として使われています。言い換えると、ある全体の特徴を表す分布p(z)から、その特徴に合ったサンプルZ(l)=(z1,..,zl)を取り出すことです。たくさんのサンプルを集めることで、全体から直接計算するのが難しい場合でも、学習した全体の特徴を表す分布から得られた、人工的に作られたデータは、その全体の特徴を表す分布の標本(サンプル)に相当するため、サンプルから答えを出すことができます。
サンプリングとは

統計の調べものをする時、全部を調べるのは大変なことが多いです。例えば、全国の小学生の平均身長を調べたいとします。日本中の小学生全員の身長を測るのは、時間もお金もかかりすぎて現実的ではありません。このような時、一部の人だけを選んで調べ、そこから全体の様子を推測する方法があります。これを「抜き取り」と言います。
抜き取りは、統計や機械学習の分野でよく使われる大切な技術です。全部の情報を扱うのが難しい時や、処理に時間がかかりすぎる時などに役立ちます。上手に抜き取りを行うと、少ない情報からでも全体の特徴をつかみ、確かな分析結果を得ることができます。
抜き取りの方法には色々な種類があります。例えば、くじ引きのように、誰にでも同じように選ばれるチャンスがある方法や、地域や年齢などのグループごとに人数を決めて抜き取る方法などがあります。どの方法を使うかは、調べたい内容や持っている情報の性質によって、一番良いものを選ぶ必要があります。
例えば、ある地域に男の子が多く住んでいるとします。この地域で子供の平均身長を調べたい時、単純にくじ引きで抜き取りをすると、男の子が多く選ばれてしまい、実際の平均身長よりも高くなってしまうかもしれません。このような偏りを正しく反映した抜き取り方を選ばないと、正しい結果が得られないことがあります。つまり、目的に合った正しい抜き取り方を選ぶことが、信頼できる結果を得るためにとても重要なのです。

確率分布とサンプリング

偶然性に左右される出来事の起こりやすさを表すのが確率分布です。たとえば、サイコロを振ったときに出る目は1から6までのいずれかで、それぞれの目が出る確率は同じ、つまり6分の1です。これは一様分布と呼ばれる確率分布の一種です。また、コインを投げたときに表と裏が出る確率はそれぞれ2分の1で、これも確率分布で表すことができます。
確率分布は、様々な現象を理解し予測するために用いられます。例えば、商品の売れ行き予測や株価の変動予測など、様々な場面で確率分布が役立ちます。ある商品の売れ行きが、過去のデータから正規分布に従うと仮定できれば、今後の売れ行きをある程度の確率で予測することが可能になります。
サンプリングとは、この確率分布から実際にデータを取り出す操作のことです。サイコロを振って出た目や、コインを投げて出た表裏は、それぞれ確率分布から得られたサンプルと言えます。また、商品の売れ行きデータや株価のデータも、それぞれの確率分布から得られたサンプルと考えることができます。
サンプリングは、母集団全体の性質を推定するために用いられます。例えば、全国の小学生の平均身長を知りたい場合、全員の身長を測ることは現実的に困難です。そこで、一部の小学生を無作為に選び、彼らの身長を測ることで、全国の小学生の平均身長を推定します。このとき、選ばれた小学生の身長データはサンプルであり、全国の小学生の身長の分布は母集団の確率分布となります。サンプル数が多ければ多いほど、母集団の確率分布の形状や特徴をより正確に把握でき、信頼性の高い推定が可能になります。つまり、たくさんのサンプルを集めることで、母集団の性質をより正確に理解することができるのです。

機械学習における活用例

機械学習は、まるで人間の学習と同じように、コンピュータに大量のデータを与えて、そこからパターンや規則性を自動的に見つけ出す技術です。この学習過程において、データの扱い方が非常に重要になってきます。すべてのデータを漏れなく使うのが理想ですが、データ量が膨大な場合、時間や計算資源の消費が莫大になり、現実的ではありません。そこで登場するのが「抜き取り」という考え方です。これは、全体のデータから一部を選び出して使う手法で、全体の傾向をなるべく保ちつつ、効率的に学習を進めるために使われます。
例えば、何百万枚もの画像を使って、猫を認識するシステムを作るとしましょう。すべての画像を使うと、学習に膨大な時間がかかります。そこで、「抜き取り」を使って、全体の画像から特徴をよく表していると思われる数万枚を選び出して学習させれば、時間と資源を節約できます。また、集めたデータに偏りがある場合にも、「抜き取り」が役立ちます。例えば、猫の画像データに、特定の毛色の猫ばかりが多いと、他の毛色の猫の認識精度が低くなる可能性があります。このような場合、「抜き取り」によって、少ない毛色の猫の画像を多く選び出すことで、データの偏りを減らし、より正確な認識システムを作ることができます。
さらに、「抜き取り」は、データが少ない場合の対策にも使えます。学習済みのシステムは、データの特徴を捉えた確率の分布を学習しています。この分布に基づいて、コンピュータが擬似的なデータを作り出すことが可能です。これは、いわば元のデータの「コピー」のようなものですが、学習に役立つ情報を加えることで、少ないデータでもより性能の高いシステムを作ることができます。このように、「抜き取り」は、データの効率的な利用や偏りの修正、データ生成など、機械学習には欠かせない技術なのです。

様々なサンプリング手法

抽出調査は、全体を調べることなく一部だけを調べて全体の様子を推測する方法です。様々な抽出方法があり、それぞれに良さがあります。適切な方法を選ぶことで、より正確な全体像を把握できます。
まず、単純無作為抽出法は、くじ引きのように、母集団全てから偏りなく無作為に標本を選び出す方法です。母集団のリストがあれば簡単に実施でき、全体を代表する標本を得やすいという利点があります。しかし、母集団が大きい場合は、標本抽出に手間がかかることがあります。
次に、層化抽出法は、母集団をいくつかのグループ(層)に分け、各グループから単純無作為抽出を行う方法です。例えば、男女比や年齢層など、母集団の特徴に基づいてグループ分けを行います。この方法は、各グループの特徴を反映した標本を得ることができ、母集団の偏りを考慮した分析が可能です。全体をより正確に反映した結果を得られます。
そして、集落抽出法は、母集団をいくつかの集まり(集落)に分け、いくつかの集落を無作為に選び、選ばれた集落の全員を標本とする方法です。例えば、市町村や学校などを集落として扱うことができます。この方法は、地理的に分散した母集団を調査する場合に効率的です。大規模な調査でも、比較的少ない手間で標本を抽出できます。ただし、選ばれた集落の特徴が全体を代表していない場合、結果に偏りが生じる可能性があります。
最後に、どの抽出方法を選ぶかは、調査の目的や母集団の特性、費用や時間などの制約を考慮して決める必要があります。例えば、精度を重視する場合は層化抽出法、効率性を重視する場合は集落抽出法といったように、状況に応じて適切な方法を選択することで、より信頼性の高い結果を得ることができます。
| 抽出方法 | 説明 | 利点 | 欠点 |
|---|---|---|---|
| 単純無作為抽出法 | 母集団全体から偏りなく無作為に標本を選び出す方法 | 母集団のリストがあれば簡単に実施でき、全体を代表する標本を得やすい | 母集団が大きい場合は、標本抽出に手間がかかる |
| 層化抽出法 | 母集団をいくつかのグループ(層)に分け、各グループから単純無作為抽出を行う方法 | 各グループの特徴を反映した標本を得ることができ、母集団の偏りを考慮した分析が可能。全体をより正確に反映した結果を得られる。 | |
| 集落抽出法 | 母集団をいくつかの集まり(集落)に分け、いくつかの集落を無作為に選び、選ばれた集落の全員を標本とする方法 | 地理的に分散した母集団を調査する場合に効率的。大規模な調査でも、比較的少ない手間で標本を抽出できる。 | 選ばれた集落の特徴が全体を代表していない場合、結果に偏りが生じる可能性がある。 |
サンプリングの注意点

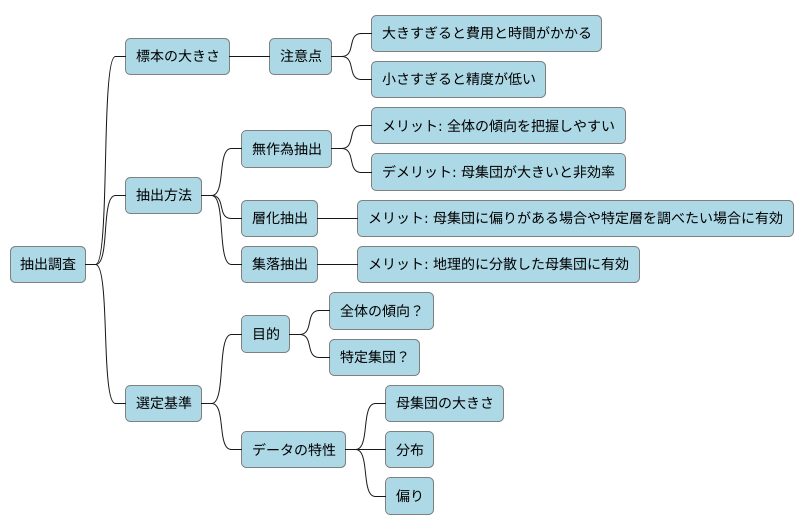
調べものをするとき、全部を調べるのは大変な場合が多いです。そのため、一部だけを調べて全体の様子を推測するやり方があります。これを標本調査と言います。標本調査で大切なのは、一部から全体をうまく推測できるような調べ方をすることです。いくつか注意すべき点があります。
まず、どれだけの数を調べるかが重要です。調べる数が少なすぎると、全体の様子を正しく捉えられないことがあります。例えば、100人のクラスで3人だけにアンケートを取っても、クラス全体の意見を反映しているとは言えません。逆に、調べる数が多すぎると、時間やお金がかかりすぎてしまいます。100人のクラスで98人にアンケートを取っても、全員に聞くのとあまり変わらない手間がかかります。調べるのにちょうど良い数は、統計の計算方法を使って求めることができます。
次に、どのようにして調べるものを選ぶかも大切です。例えば、クラスで一番前の席の人だけにアンケートを取ると、クラス全体の意見を正しく反映していない可能性があります。特定の場所に座る生徒には共通の何かがあるかもしれません。全体から偏りなく選ぶことが重要です。くじ引きのように、誰にでも同じように選ばれる機会がある方法が良いでしょう。
最後に、一部だけを調べているので、どうしても全体とは少しずれが生じてしまうことを理解しておく必要があります。全体を調べた結果と、一部を調べて推測した結果には、違いが出てしまうのです。この違いを標本誤差と言います。この誤差を少しでも小さくするために、適切な調べ方を選び、調べる数を適切に決めることが重要です。適切な標本の大きさや抽出方法は統計学によって裏付けされています。闇雲に数を増やせば良いというものではなく、正しい方法を用いることで、より少ない手間で、より正確な結果を得ることができるのです。
| 標本調査の注意点 | 詳細 |
|---|---|
| どれだけの数を調べるか |
|
| どのようにして調べるものを選ぶか |
|
| 標本誤差 |
|
まとめ

限られた情報から全体の傾向をつかむために、抽出調査は統計や機械学習で欠かせない手法です。適切な抽出方法を用いることで、少ないデータからでも全体の様子を把握し、確度の高い分析結果を得ることが可能になります。この手法をうまく活用すれば、費用や時間を抑えながら、質の高い分析を行うことができます。
抽出調査には様々な方法があり、それぞれに得意な点と不得意な点があります。例えば、無作為抽出は、母集団から偏りなく無作為に標本を抽出する方法で、全体の傾向を把握するのに適しています。しかし、母集団が大きく多様な場合は、標本の数が膨大になり非効率的な場合があります。
一方、層化抽出は、母集団をいくつかの層に分け、それぞれの層から標本を抽出する方法です。母集団に偏りがある場合や、特定の層について詳しく調べたい場合に有効です。また、集落抽出は、母集団をいくつかの集落に分け、いくつかの集落を無作為に選び、選ばれた集落に属する要素全てを標本とする方法です。地理的に分散した母集団を調査する場合に適しています。
どの抽出方法を選ぶかは、調査の目的やデータの特性によって異なります。目的が全体の傾向を把握することなのか、特定の集団について詳しく調べることなのかを明確にする必要があります。また、データの特性として、母集団の大きさや分布、偏りの有無などを考慮する必要があります。適切な方法を選択することで、より精度の高い分析結果を得ることができます。抽出調査は、データ分析を行う上で必ず知っておくべき手法と言えるでしょう。理解を深めることで、より高度な分析が可能になり、データに基づいた的確な判断ができるようになります。抽出調査を行う際には、標本の大きさにも注意が必要です。標本の大きさが小さすぎると、結果の精度が低くなります。反対に大きすぎると、費用や時間がかかりすぎて非効率になります。適切な標本の大きさを決めるには、統計的な知識が必要になります。