L0正則化とは?モデルの複雑さを抑える仕組みと注意点

AIの初心者
「L0正則化」は、パラメータをなるべくゼロにしてモデルをシンプルにする方法、という理解で合っていますか?

AI専門家
大きくは合っています。L0正則化は、ゼロではないパラメータの数を減らすことで、モデルを単純にし、過学習を抑える考え方です。重みがゼロになると、その重みに対応する特徴量は予測に使われにくくなります。
AIの初心者
L1正則化やL2正則化とは、どこが違うのでしょうか?
AI専門家
L1やL2は主にパラメータの大きさを抑えます。一方、L0正則化は「ゼロではないパラメータがいくつ残っているか」を直接見ます。特徴量選択には分かりやすい考え方ですが、計算が難しいため、実務ではL1正則化などで近似することが多いです。
L0正則化とは。
L0正則化とは、機械学習モデルのパラメータのうち、ゼロではない値を持つものの個数にペナルティを与える正則化手法です。モデルが多くの特徴量や重みを使いすぎると、学習データにはよく合っても未知のデータに弱くなることがあります。L0正則化は、必要なパラメータだけを残す方向に学習を促し、モデルの複雑さを直接抑えようとします。
L0正則化とは何か
L0正則化は、モデルの重みや係数の中で「0ではないもの」を数え、その数が多いほど損失関数に罰則を加える方法です。重みがゼロになると、その重みに対応する特徴量は予測にほとんど使われません。そのため、L0正則化は特徴量選択と深く関係しています。
たとえば、住宅価格を予測するモデルに「駅からの距離」「築年数」「部屋数」「壁の色」「広告文の長さ」など多くの特徴量があるとします。予測に役立たない特徴量まで使うと、モデルは不要な情報に反応しやすくなります。L0正則化は、こうした不要な特徴量に対応する重みをゼロにし、重要な特徴だけを残すことを目指します。
このように、L0正則化の目的は単に精度を上げることではありません。モデルを必要以上に複雑にしないことで、過学習を抑え、結果の解釈をしやすくすることが重要な狙いです。
正則化と過学習の関係
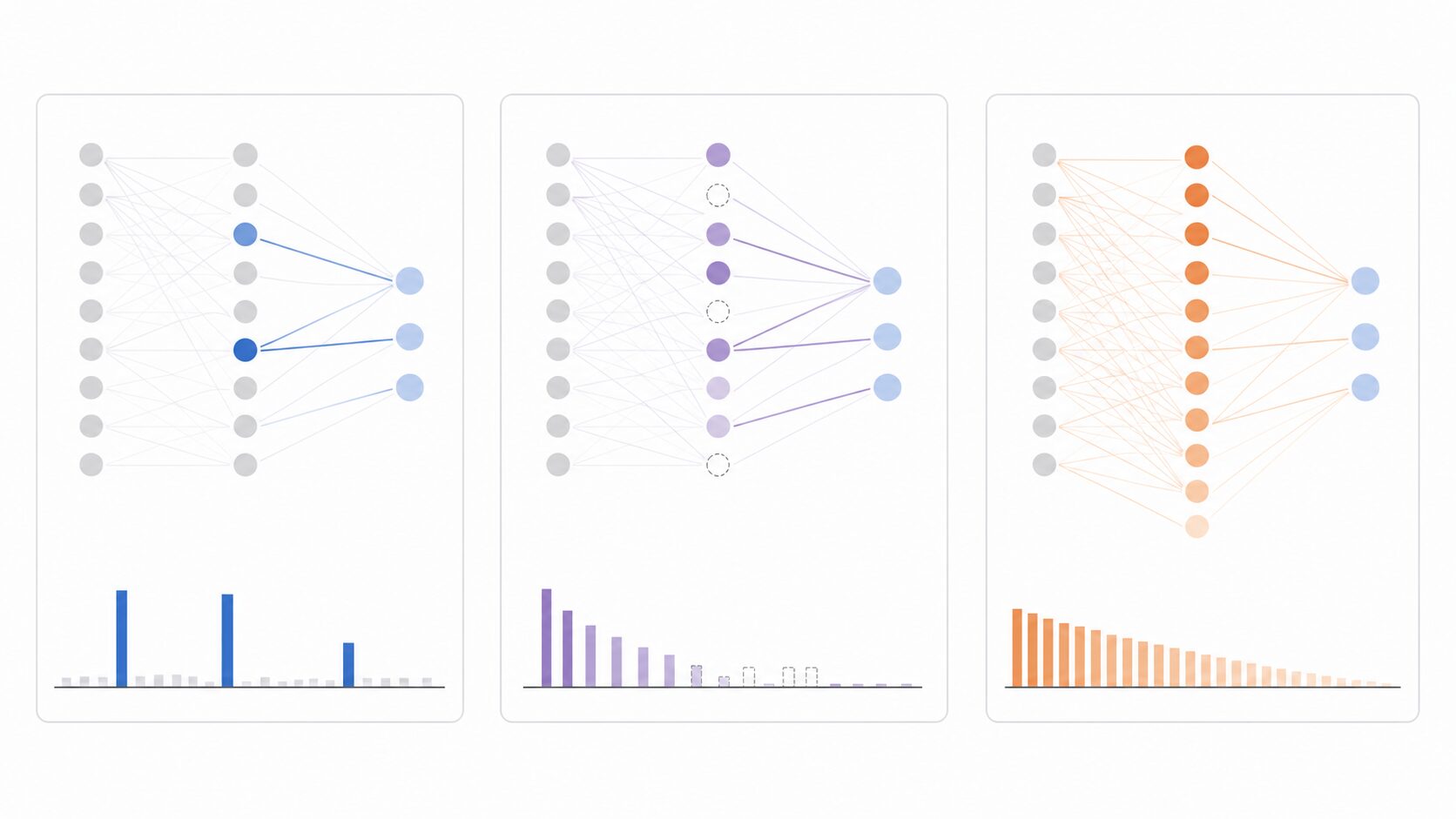
正則化とは、モデルが学習データに合わせ込みすぎないように、学習時の評価基準へ追加の制約を入れる考え方です。機械学習では、訓練データでは高い精度を出せるのに、新しいデータでは予測が外れやすい状態が起こります。これが過学習です。
通常の学習では、予測値と正解値のずれを表す損失関数を小さくします。ただし、損失だけを追いかけると、モデルが訓練データの細かな揺れやノイズまで覚えてしまうことがあります。そこで、損失関数に正則化項を加え、複雑すぎるモデルを選びにくくします。
L0正則化では、この正則化項として「ゼロではないパラメータの個数」を使います。値の大きさそのものよりも、使っているパラメータの数に注目するため、モデルの構造を単純にする効果が強く表れます。
L0正則化の仕組み
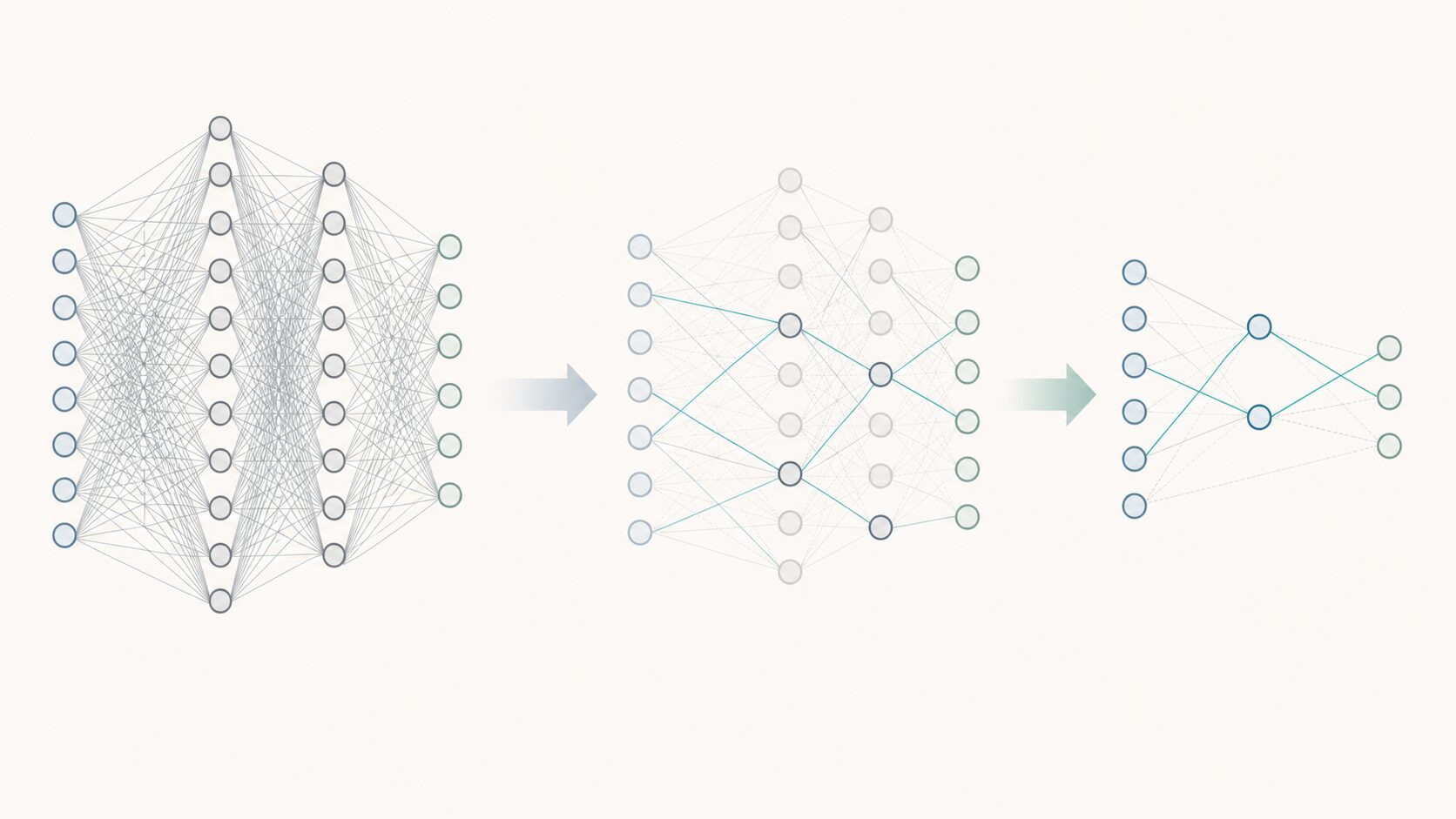
L0正則化では、パラメータがゼロか、ゼロではないかを見ます。ゼロではないパラメータが多いほど、モデルは多くの特徴量を使っていると判断され、正則化のペナルティが大きくなります。反対に、ゼロのパラメータが多いほど、モデルは単純であると見なされます。
この性質により、L0正則化はスパース性を生みやすい手法です。スパース性とは、多くの要素がゼロで、少数の要素だけが非ゼロである状態を指します。機械学習では、スパースなモデルは「どの特徴量が予測に効いているのか」を追いやすく、解釈性の面で利点があります。
一方で、パラメータをゼロにすることは情報を捨てることでもあります。重要な特徴まで削ってしまうと、モデルは単純になりすぎ、訓練データにも未知データにも十分に対応できなくなります。そのため、L0正則化では、どれくらい強くパラメータ数を減らすかの調整が重要です。
| 観点 | L0正則化で起きること |
|---|---|
| 複雑さ | ゼロではないパラメータ数が少ないほど単純なモデルになる |
| 特徴量選択 | 不要な特徴量に対応する重みをゼロにしやすい |
| 解釈性 | 使われている特徴量が少ないため、判断理由を追いやすい |
| 注意点 | 必要な特徴まで削ると、表現力が不足する |
数式で見るL0正則化
\(\min_w \; L(w) + \lambda \|w\|_0
\)
上の式では、L(w) が予測誤差を表す損失関数、\lambda が正則化の強さ、\|w\|_0 がゼロではないパラメータの個数を表します。つまり、L0正則化では「予測誤差を小さくすること」と「使うパラメータ数を減らすこと」を同時に考えます。
\lambda を大きくすると、ゼロではないパラメータを残すコストが高くなり、より少ない特徴量で説明するモデルが選ばれやすくなります。反対に \lambda が小さいと、正則化の影響は弱まり、モデルは多くのパラメータを使いやすくなります。
なお、L0「ノルム」と呼ばれることがありますが、厳密な数学上のノルムとは性質が異なります。初学者は、まず「ゼロではない要素の個数を数える指標」と理解するとよいでしょう。
計算が難しい理由
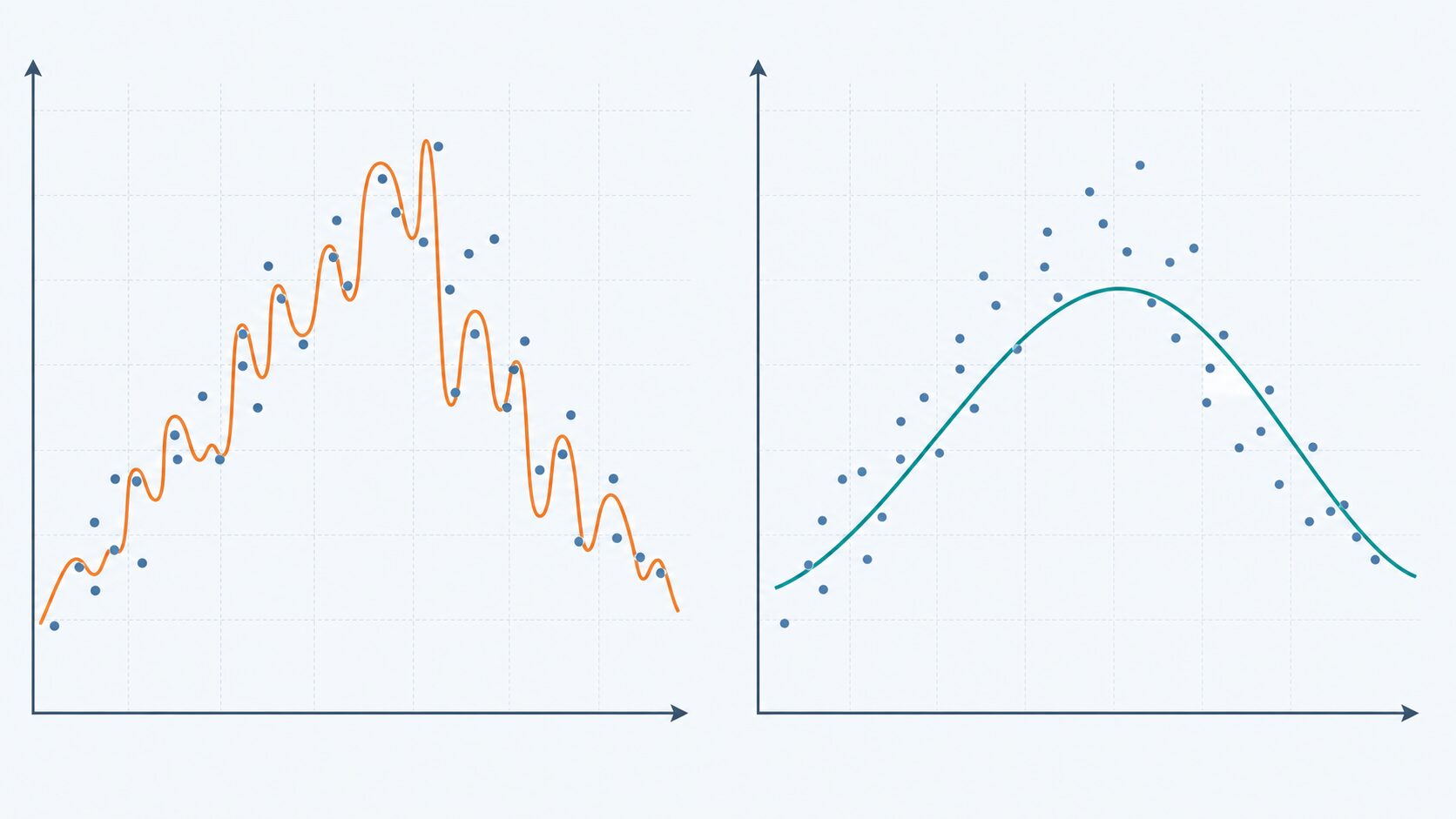
L0正則化の大きな課題は、計算が難しいことです。一般的な最適化では、損失関数の傾き、つまり微分を使って、どの方向へパラメータを動かせばよいかを判断します。しかし、L0正則化で数える「ゼロか、ゼロではないか」は滑らかな変化ではないため、微分を使った方法を直接適用しにくいのです。
さらに、厳密に最適な組み合わせを探すには、どのパラメータを残し、どのパラメータをゼロにするかを調べる必要があります。パラメータが3個なら、残す・残さないの組み合わせは8通りです。しかし、パラメータが20個なら約100万通り、100個なら現実的に調べきれないほどの組み合わせになります。
このような組み合わせの爆発があるため、L0正則化は考え方としては分かりやすくても、大規模なモデルにそのまま使うのは簡単ではありません。そのため、実務では近似アルゴリズムや、より計算しやすい正則化手法が選ばれることが多くなります。
L1正則化・L2正則化との違い
L0正則化は「ゼロではないパラメータの数」を減らします。これに対して、L1正則化はパラメータの絶対値の和を小さくし、L2正則化はパラメータの二乗和を小さくします。つまり、L0は数、L1とL2は主に値の大きさに注目します。
L1正則化は、パラメータをちょうどゼロにしやすい性質があるため、L0正則化に近い特徴量選択の効果を得られることがあります。LASSOはL1正則化を使った代表的な手法で、回帰問題で重要な特徴量を選びながらモデルを単純にしたいときによく登場します。
L2正則化は、パラメータを全体的に小さくする方向に働きますが、L1ほどゼロにはなりにくい傾向があります。そのため、特徴量を明確に削るというより、重みが大きくなりすぎないようにして、モデルを安定させる目的で使われます。
| 手法 | 注目するもの | 主な効果 | 注意点 |
|---|---|---|---|
| L0正則化 | ゼロではないパラメータの個数 | 特徴量選択、スパースなモデル | 厳密な最適化の計算負荷が高い |
| L1正則化 | パラメータの絶対値の和 | 重みをゼロにしやすく、特徴量選択に使える | L0のように個数を直接制御するわけではない |
| L2正則化 | パラメータの二乗和 | 重みをなめらかに抑え、モデルを安定させる | 不要な特徴量がゼロとして消えるとは限らない |
| LASSO | L1正則化を使う回帰手法 | 予測と特徴量選択を同時に扱いやすい | 相関の強い特徴量がある場合は選ばれ方に注意が必要 |
実務で使うときの注意点
L0正則化を理解すると、モデルの複雑さをどう制御するかを考えやすくなります。ただし、実務で重要なのは「なるべく多くゼロにすればよい」と単純に考えないことです。パラメータを減らしすぎると、モデルが必要な情報を表現できず、予測性能が落ちます。
正則化の強さは、訓練データだけで判断せず、検証データや交差検証で確認します。訓練データの誤差が少し増えても、未知データでの誤差が下がるなら、正則化がうまく働いている可能性があります。反対に、訓練データでも検証データでも性能が悪い場合は、正則化が強すぎるか、モデルそのものが単純すぎる可能性があります。
また、大規模データや深層学習モデルでは、L0正則化を厳密に入れるよりも、L1正則化、ドロップアウト、重み減衰、近似的なスパース化手法などを使うほうが現実的な場合があります。L0正則化は、実装手段としてだけでなく、モデルのどの複雑さを減らしたいのかを考える基準としても役立ちます。
L0正則化のまとめ
L0正則化は、ゼロではないパラメータの個数を減らすことで、モデルの複雑さを直接抑える正則化手法です。特徴量選択やスパースなモデルの理解に役立ち、過学習を防ぐための重要な考え方でもあります。
一方で、L0正則化は微分を使った最適化が難しく、パラメータの組み合わせ探索も膨大になりやすいという課題があります。そのため、実務ではL1正則化やLASSOなど、計算しやすい手法で近い効果を狙うことがよくあります。
初学者は、L0正則化を「使う特徴量の数を直接減らそうとする方法」と押さえると理解しやすくなります。そのうえで、L1やL2との違い、正則化の強さの調整、過学習との関係を合わせて学ぶと、機械学習モデルの設計をより見通しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年5月16日 | L1・L2との違いと計算困難性を追いやすい流れに更新 |