自己回帰モデルで未来予測

AIの初心者
先生、「自己回帰モデル」って難しくてよくわからないんですけど、簡単に説明してもらえますか?

AI専門家
わかった。簡単に言うと、過去のデータを使って未来を予測するモデルのことだよ。例えば、昨日の気温や一昨日の気温から今日の気温を予測するようなものだね。
AIの初心者
過去のデータを使うっていうのはなんとなくわかるんですが、具体的にどう予測するんですか?
AI専門家
そうだね。例えば、今日の気温を予測したいとすると、昨日の気温に何か係数を掛けて、さらに定数を加えるといった計算をするんだ。その係数と定数は、過去のデータから一番予測精度が高くなるように調整されているんだよ。
自己回帰モデルとは。
人工知能の用語で「自己回帰モデル」というものがあります。これは、過去のデータを使って現在のデータを予測する分析方法です。株価や天気の予測といった、時間の流れに沿って変化するデータの予測に使われます。例えば、ある時点での予測値を計算したい場合、一つ前の時点の値と、その時点特有の偶然による変動、そして固定値を使って計算します。計算に必要な調整値は、最小二乗法や最尤法といった方法で見つけ出します。
自己回帰モデルとは

自己回帰モデルは、過去の自分自身の姿から未来の姿を予測する、まるで写し鏡のような手法です。過去のデータが未来を映し出す鍵となり、過去の自分の行動や状態が未来の自分の行動や状態を決定づけるという考え方に基づいています。
例えば、明日の気温を予測したいとします。自己回帰モデルでは、今日の気温だけでなく、昨日の気温、一昨日の気温、さらに過去の気温も参考にすることで、より精度の高い予測をしようとします。過去の気温の変化から、気温が上がり続けるのか、下がり続けるのか、あるいは周期的に変化するのかといったパターンを見つけ出すのです。この過去の気温のパターンが未来の気温を予測する羅針盤となるのです。
株価の予測も同様です。今日の株価だけでなく、過去の株価の動きを分析することで、明日の株価が上がるか下がるかを予測します。過去の株価が上昇傾向にある場合は、明日も上昇する可能性が高いと予測し、逆に下降傾向にある場合は、明日も下降する可能性が高いと予測します。
このように、自己回帰モデルは過去のデータの中に隠された規則性を見つけ出し、未来を予測する統計的手法です。過去のデータが多ければ多いほど、未来予測の精度は向上すると考えられます。ただし、過去のデータが全て未来を正確に反映しているとは限りません。予期せぬ出来事が起こる可能性も考慮する必要があります。未来は過去の延長線上にあるという仮定に基づいているため、過去のトレンドが大きく変化した場合、予測精度が低下する可能性があることにも注意が必要です。そのため、自己回帰モデルは他の予測手法と組み合わせて使用されることもあります。
| 概念 | 説明 | 例 |
|---|---|---|
| 自己回帰モデル | 過去の自分自身の姿から未来の姿を予測する統計的手法。過去のデータの中に隠された規則性を見つけ出し、未来を予測する。過去のデータが多ければ多いほど、未来予測の精度は向上すると考えられる。 | 明日の気温予測、株価予測 |
| 基本的な考え方 | 過去の自分の行動や状態が未来の自分の行動や状態を決定づけるという考え方。過去のデータが未来を映し出す鍵となる。 | 過去の気温の変化から未来の気温を予測、過去の株価の動きから未来の株価を予測 |
| モデルの特性 | 過去のトレンドが大きく変化した場合、予測精度が低下する可能性がある。未来は過去の延長線上にあるという仮定に基づいている。 | 予期せぬ出来事が起こる可能性も考慮する必要がある。 |
| 注意点 | 過去のデータが全て未来を正確に反映しているとは限らない。他の予測手法と組み合わせて使用されることもある。 | – |
モデルの仕組み

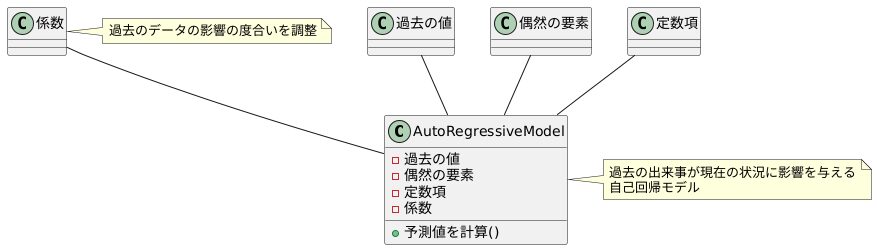
このモデルは、過去の出来事が現在の状況に影響を与えるという考え方に基づいて作られています。ちょうど、今日の気温が昨日の気温に関係しているように、過去のデータが現在の値に影響を与えると考えています。これを自己回帰モデルと呼びます。
具体的には、予測したい値は、三つの要素を組み合わせて計算されます。一つ目は過去の値です。過去のデータがどれくらい現在の値に影響を与えるかを数値で表します。二つ目は、予測できない偶然の要素です。これは、どんなに過去のデータを分析しても完全に予測できない部分を表します。三つ目は、常に一定の値を持つ定数項です。これは、予測したい値の基本的な部分を決定します。
過去のデータの影響の度合いは、調節可能な数値で調整します。この数値を「係数」と呼びます。それぞれの過去のデータに、どれだけの重みをつけるかを、この係数で決めます。例えば、昨日の気温が今日の気温に大きく影響するのであれば、昨日の気温に対応する係数を大きく設定します。逆に、一週間前の気温は今日の気温にあまり影響しないのであれば、その係数を小さく設定します。
この係数を適切に調整することが、モデルの精度を高める鍵となります。過去のデータから未来への影響度を適切に見積もることで、より正確な予測が可能になります。係数の調整は、様々な方法で行います。例えば、過去のデータと実際の値を比較し、その差が最小になるように係数を調整する方法があります。適切な係数を見つけることで、モデルの予測精度を向上させ、より信頼性の高い予測結果を得ることができるのです。
このように、自己回帰モデルは、過去のデータに基づいて未来を予測する、強力な道具となります。適切な係数の設定を行うことで、様々な分野で精度の高い予測を実現できる可能性を秘めています。
パラメータ推定

「パラメータ推定」とは、観測されたデータに基づいて、統計モデルのパラメータの値を最適化する作業のことです。この作業は、自己回帰モデルなどの予測モデルの精度向上に不可欠です。パラメータとは、モデルの挙動を決定づける重要な値であり、適切な推定を行うことで、モデルが将来の値をより正確に予測できるように調整できます。
代表的なパラメータ推定の手法として、「最小二乗法」と「最尤法」の二つがあります。まず、最小二乗法について説明します。この手法は、モデルが予測した値と実際に観測された値の差、つまり誤差に着目します。この誤差を二乗した値の合計を最小にするようにパラメータを調整することで、モデルの予測精度を高めます。直感的で理解しやすく、計算も比較的容易であるため、広く利用されています。
次に、最尤法について説明します。この手法は、観測されたデータが得られる確率に着目します。あるパラメータの値のもとで、観測データが得られる確率を「尤度」と呼びます。最尤法は、この尤度を最大にするようにパラメータを調整する手法です。つまり、観測されたデータが最も高い確率で発生するようにパラメータを最適化します。
どちらの手法も、過去のデータに基づいて、未来への影響度を表すパラメータを調整することで、モデルの予測精度を向上させます。ただし、それぞれの手法には異なる特性があるため、データの性質やモデルの目的に応じて適切な手法を選択することが重要です。例えば、データに外れ値が含まれる場合、最小二乗法は外れ値の影響を受けやすい一方、最尤法はより頑健な推定値を得られる場合もあります。最適な手法を選ぶことで、より信頼性の高い予測モデルを構築することができます。
| 手法 | 説明 | 目的 | 特徴 |
|---|---|---|---|
| 最小二乗法 | モデルの予測値と実測値の誤差の二乗和を最小にする | 予測精度を高める | 直感的、計算が容易、外れ値の影響を受けやすい |
| 最尤法 | 観測データが得られる確率(尤度)を最大にする | 予測精度を高める | 観測データの発生確率を最大化、外れ値に強い場合がある |
モデルの適用事例

自己回帰モデルは、過去のデータに基づいて未来を予測する統計的手法であり、様々な分野で広く活用されています。このモデルは、過去の値を現在の値の予測に利用するという特性から、時系列データの分析に特に適しています。
金融業界では、株価の変動予測に自己回帰モデルが活用されています。過去の株価の推移を分析することで、将来の株価の動きを予測し、投資戦略の立案に役立てています。また、為替レートや金利の予測にも応用され、金融市場におけるリスク管理にも貢献しています。
気象予報においても、自己回帰モデルは重要な役割を果たしています。過去の気温、降水量、風速などの気象データを分析することで、将来の天気の変化を予測します。これにより、豪雨や台風などの自然災害への対策を立てることができ、人々の安全確保に役立っています。さらに、長期的な気候変動の予測にも活用され、地球温暖化対策などの政策決定にも貢献しています。
医療分野では、患者の状態変化の予測に自己回帰モデルが利用されています。例えば、患者のバイタルデータ(心拍数、血圧、体温など)の変化を分析することで、病気の進行状況や治療の効果を予測することができます。これにより、医師は適切な治療方針を決定し、患者の容態を早期に改善することができます。
需要予測や売上予測にも自己回帰モデルは活用されています。過去の販売実績や市場動向を分析することで、将来の需要や売上を予測し、生産計画や在庫管理の最適化に役立てています。これにより、企業は効率的な経営を行い、収益性を向上させることができます。
このように、自己回帰モデルは様々な分野で活用され、データに基づいた意思決定を支援する重要なツールとなっています。今後も、データ分析技術の進歩とともに、自己回帰モデルの応用範囲はさらに広がっていくと期待されます。
| 分野 | 活用例 |
|---|---|
| 金融 | 株価、為替レート、金利の予測、リスク管理 |
| 気象予報 | 天気変化の予測、自然災害対策、長期的な気候変動予測 |
| 医療 | 患者の状態変化予測、治療効果予測、治療方針決定 |
| 需要予測 | 需要や売上予測、生産計画や在庫管理の最適化 |
モデルの限界

予測を繰り返す仕組みを持つ自己回帰モデルは、様々な分野で力を発揮する便利な道具ですが、完璧な予測機械ではありません。いくつか注意すべき点、つまり限界があります。
まず、自己回帰モデルは、過去のデータに基づいて未来を予測します。これは、これまでと同じような傾向がこれからも続くと考えるということです。例えば、過去数年間、毎年売上高が10%ずつ伸びていたとします。このモデルは、来年も10%の増加を見込むでしょう。しかし、急な変化や誰も予想しなかった出来事が起こると、この予測は外れてしまいます。世界的な流行り病や大きな自然災害などは、過去のデータには含まれていないため、モデルは対応できません。このような予測できない出来事が起こると、モデルの精度は大きく下がる可能性があります。
次に、自己回帰モデルを正しく使うには、適切な設定が欠かせません。この設定は、モデルの動きを決める様々な値を調整する作業で、ちょうど機械のネジを細かく調整するようなイメージです。この設定が適切でないと、モデルは本来の力を発揮できません。しかし、最適な設定を見つけるのは簡単ではありません。複雑な計算が必要で、専門的な知識が必要となる場合もあります。
自己回帰モデルは強力な道具ですが、万能ではありません。その限界を理解し、適切な使い方をすることが大切です。急な変化や予想外の出来事の影響、そして適切な設定の難しさを常に意識することで、より信頼性の高い予測に繋げることができます。
| メリット | デメリット | 対策 |
|---|---|---|
| 過去のデータに基づいて未来を予測できる |
|
限界を理解し、適切な使い方をする |
| 様々な分野で力を発揮する |
|
急な変化や予想外の出来事の影響、そして適切な設定の難しさを常に意識する |
今後の展望

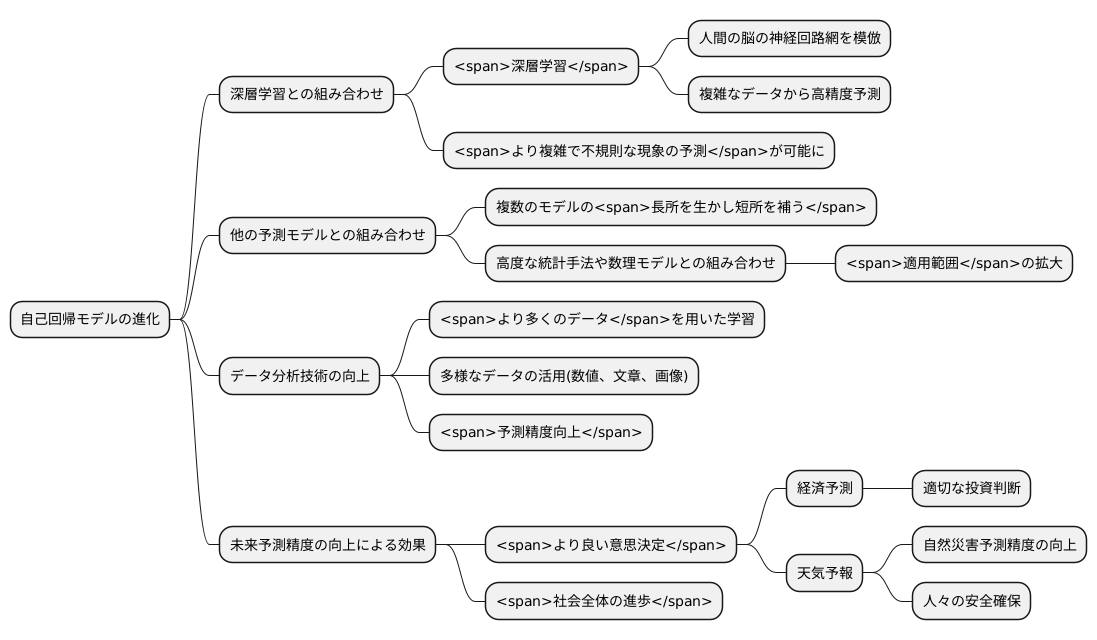
自己回帰モデルは、過去データに基づいて未来を予測する手法であり、絶えず進歩を続けています。近年では、深層学習と組み合わせることで、飛躍的な進化を遂げています。深層学習は、人間の脳の神経回路網を模倣した学習モデルであり、複雑なデータからでも精度の高い予測を可能にします。この深層学習を取り入れることで、従来の自己回帰モデルでは難しかった、より複雑で不規則な現象の予測も可能になりつつあります。
また、自己回帰モデルは、他の予測モデルと組み合わせることで、更なる発展が期待されています。例えば、複数の異なる予測モデルを組み合わせ、それぞれの長所を生かしつつ短所を補うことで、より精度の高い予測が可能になります。また、他の分野で開発された高度な統計手法や数理モデルを組み合わせることで、予測の適用範囲も広がることが期待されます。
自己回帰モデルの進化は、データ分析技術の向上と共にあります。大量のデータを高速で処理できるようになったことで、より多くのデータを学習に用いることが可能になりました。また、データの種類も多様化しており、数値データだけでなく、文章や画像などのデータも活用できるようになってきています。これらのデータ分析技術の進歩は、自己回帰モデルの予測精度向上に大きく貢献しています。
未来予測の精度の向上は、様々な分野でより良い意思決定を可能にします。例えば、経済予測においては、景気の動向を予測することで、企業は適切な投資判断を行うことができます。また、天気予報においては、自然災害の予測精度を高めることで、人々の安全を守ることに繋がります。自己回帰モデルの更なる発展は、社会全体の進歩に大きく貢献していくと考えられます。