F1スコア:機械学習の精度の要

AIの初心者
先生、「F1スコア」ってよく聞くんですけど、どういう意味ですか?

AI専門家
そうだね。「F1スコア」は、機械学習モデルの性能を測るためのものだよ。0から1までの値で、1に近いほど良いモデルと言えるんだ。
AIの初心者
1に近いほど良いというのは、具体的にどういうことですか?
AI専門家
簡単に言うと、予測の正確さと、見落としがないかのバランスが取れていることを意味するよ。例えば、不良品を見つける機械で考えると、本当に不良品を見つける能力と、不良品を見逃さない能力の両方が高くないといけないよね。F1スコアは、この両方の能力の高さをまとめて評価しているんだ。
F1スコアとは。
「人工知能」に関する言葉である「F1スコア」について説明します。この言葉は、統計学や機械学習で使われる「F値」という範囲の中の値です。1.0に近いほど良い値とされ、1.0に近い値は、正解率と網羅率の両方が同時にできるだけ高いことを示しています。そのため、「最も効率よくバランスの取れた機械学習の模型」と言えるでしょう。
F1スコアの基礎知識

機械学習の良し悪しを測る尺度は、その学習結果がどれほど正確に未来を言い当てられるかを測る上でとても大切です。そうした尺度の一つにF1スコアというものがあります。これは、学習結果の良し悪しを測る強力な道具です。F1スコアは、0から1までの数字で表され、1に近いほど良い学習結果であることを示します。この尺度は、ただどれくらい当たっているかを見るだけでなく、実際には違うのに当たっているとした場合と、実際には当たっているのに違うとした場合のバランスも見ているため、より様々な面から学習結果を評価できます。言い換えれば、F1スコアが高いほど、その学習結果はより正確で信頼できるものだと言えるでしょう。
具体的に見てみましょう。例えば、病気かどうかを診断する場合を考えてみます。もし健康な人を病気と診断してしまったら(実際には違うのに当たっているとした場合)、必要のない検査や治療を受けてしまうかもしれません。逆に、病気の人を健康と診断してしまったら(実際には当たっているのに違うとした場合)、適切な治療を受けられないことで病気が悪化してしまうかもしれません。このように、誤った判断が大きな影響を及ぼす場合に、F1スコアは特に重要な尺度となります。病気の診断以外にも、迷惑メールの振り分けなど、間違った判断が困る場面で役に立ちます。F1スコアを使うことで、そうした困った事態を減らすのに役立つ学習結果を作ることが期待できます。つまり、F1スコアは、より良い学習結果へと導くための羅針盤のような役割を果たしてくれるのです。
| F1スコアとは | 機械学習の良し悪しを測る尺度の一つ |
|---|---|
| 範囲 | 0~1 |
| 評価 | 1に近いほど良い学習結果 |
| 特徴 | 実際には違うのに当たっているとした場合と、実際には当たっているのに違うとした場合のバランスを考慮 |
| 利点 | 様々な面から学習結果を評価できる 誤った判断が大きな影響を及ぼす場合に特に重要 |
| 使用例 | 病気の診断、迷惑メールの振り分けなど |
適合率と再現率

ある事柄を正しく見分けるための指標として、適合率と再現率という二つの大切な考え方があります。これらを理解することは、評価指標F1スコアを理解する上で欠かせません。
適合率とは、機械が「該当する」と判断したものの中で、実際に該当していたものの割合です。例えば、迷惑メールを識別するシステムを考えてみましょう。このシステムが迷惑メールだと判断したメールの中で、実際に迷惑メールだったメールの割合が適合率です。適合率が高いほど、機械は該当するものだけを的確に選んでいると言えます。しかし、適合率だけでは、見落としがないかどうかはわかりません。
一方、再現率は実際に該当するものの全体の中で、機械が正しく該当すると判断できたものの割合です。迷惑メールの例で言えば、実際に迷惑メールであるメール全体の中で、システムが迷惑メールだと正しく判断できたメールの割合が再現率です。再現率が高いほど、該当するものを漏れなく見つけていると言えます。しかし、再現率だけでは、該当しないものを誤って該当と判断していないかはわかりません。
例えば、すべてのメールを迷惑メールと判断するシステムを考えてみてください。このシステムの再現率は100%になりますが、同時に多くの普通のメールも迷惑メールとして扱ってしまうため、適合率は非常に低くなります。
F1スコアは、この適合率と再現率を組み合わせた指標です。F1スコアが高いほど、該当するものを漏れなく見つけ、かつ該当しないものを誤って該当と判断することが少ない、バランスの取れたシステムと言えます。つまり、F1スコアは、適合率と再現率の両方を考慮することで、システムの性能をより正確に評価できるのです。
| 指標 | 定義 | メリット | デメリット |
|---|---|---|---|
| 適合率 (Precision) | 機械が「該当する」と判断したものの中で、実際に該当していたものの割合 | 該当するものだけを的確に選んでいるかがわかる | 見落としがあるかどうかはわからない |
| 再現率 (Recall) | 実際に該当するものの全体の中で、機械が正しく該当すると判断できたものの割合 | 該当するものを漏れなく見つけているかがわかる | 該当しないものを誤って該当と判断していないかはわからない |
| F1スコア | 適合率と再現率を組み合わせた指標 | 該当するものを漏れなく見つけ、かつ該当しないものを誤って該当と判断することが少ない、バランスの取れたシステムの評価が可能 | – |
F1スコアの計算方法

「F1スコア」とは、機械学習モデルの性能を測るための重要な指標のひとつです。特に、分類問題において、「適合率」と「再現率」のバランスを評価する際に用いられます。
適合率とは、モデルが陽性と判断したものの中で、実際に陽性であったものの割合を示します。陽性と予測したもののうち、どれだけが正しかったのかを表す指標と言えるでしょう。一方、再現率は、実際に陽性であるもの全体の中で、モデルが陽性と判断できたものの割合を表します。真に陽性であるものを、どれくらい捉えられたのかを示す指標です。
F1スコアは、この適合率と再現率の両方を考慮に入れた指標です。具体的な計算方法は、以下のとおりです。まず、適合率と再現率それぞれの逆数を求めます。次に、それらを足し合わせ、その和の逆数を求めます。最後に、その値を2倍します。数式で表すと、F1 = 2 * (適合率 * 再現率) / (適合率 + 再現率) となります。
F1スコアは、適合率と再現率の単なる平均ではなく、調和平均であることが重要です。普通の平均とは異なり、調和平均は、極端に低い値の影響を大きく受けます。例えば、適合率が非常に高くても、再現率が非常に低い場合、F1スコアは低い値になります。逆に、再現率が非常に高くても、適合率が非常に低い場合も、F1スコアは低い値になります。つまり、F1スコアを高くするためには、適合率と再現率の両方が高い値である必要があるのです。
これは、現実世界の問題を解決する上で重要な意味を持ちます。例えば、病気の診断において、陽性と診断された人が実際に病気である割合(適合率)が高いだけでは不十分です。実際に病気である人を見逃さないように、病気である人を正しく陽性と診断する割合(再現率)も高くなくてはなりません。F1スコアは、このようなバランスを評価するのに役立ちます。F1スコアが高いモデルは、陽性と判断したものの大部分が実際に陽性であり、かつ、実際に陽性であるものの大部分を陽性と判断できている、と言えるでしょう。
| 指標 | 説明 | 計算方法 |
|---|---|---|
| F1スコア | 分類問題において、適合率と再現率のバランスを評価する指標。調和平均を用いるため、どちらか一方の値が低くてもF1スコアは低くなる。 | F1 = 2 * (適合率 * 再現率) / (適合率 + 再現率) |
| 適合率 | モデルが陽性と判断したものの中で、実際に陽性であったものの割合。 | 陽性と予測したもののうち、実際に陽性だった数 / 陽性と予測した数 |
| 再現率 | 実際に陽性であるもの全体の中で、モデルが陽性と判断できたものの割合。 | 実際に陽性だったもののうち、陽性と予測できた数 / 実際に陽性だった数 |
F1スコアの活用事例

調和平均を用いた指標であるF1スコアは、機械学習モデルの良し悪しを測る物差しとして、様々な場面で使われています。 特に、正解データとそうでないデータの数が大きく違う場合に、その力を発揮します。
例えば、病気の有無を診断する場面を考えてみましょう。多くの人は健康であり、病気の人は少ないのが現状です。このような場合、単純に病気でない人を全て正解と判断するだけでも、全体の正答率は高くなってしまいます。しかし、本当に重要なのは、少ない病気の人を正しく見つけることです。F1スコアは、病気の人を見つける精度(再現率)と、病気と診断した人が実際に病気である精度(適合率)の両方を考慮するため、このような状況でのモデル評価に適しています。
また、インターネットで欲しい情報を探すときにも、F1スコアは活躍しています。検索エンジンは、入力された言葉に合う情報を膨大なデータの中から探し出します。このとき、検索結果に欲しい情報が含まれているか(再現率)だけでなく、表示された情報がどれだけ入力した言葉と関連性が高いか(適合率)も重要です。F1スコアは、この両方のバランスを評価することで、検索エンジンの性能を測ることができます。
さらに、クレジットカードの不正利用を見つける場面でも、F1スコアは役立ちます。不正利用は稀な出来事ですが、見逃すと大きな損害につながります。不正利用を正しく見つける(再現率)と同時に、誤って通常の利用を不正と判断しない(適合率)ことが重要です。F1スコアは、この両方を考慮した指標なので、不正利用検知モデルの評価に適しています。
このように、F1スコアは、少ないデータを正しく見つけることが重要な様々な場面で、機械学習モデルの性能を正しく評価するための、なくてはならない指標となっています。
| 場面 | 重視する点 | F1スコアの利点 |
|---|---|---|
| 病気の診断 | 少ない病気の人を正しく見つける(再現率) 病気と診断した人が実際に病気である(適合率) |
正解データと不正解データの数の差が大きい場合でも、適切にモデルを評価できる。 |
| インターネット検索 | 検索結果に欲しい情報が含まれている(再現率) 表示された情報が検索キーワードと関連性が高い(適合率) |
検索エンジンの性能を測ることができる。 |
| クレジットカードの不正利用検知 | 不正利用を正しく見つける(再現率) 誤って通常の利用を不正と判断しない(適合率) |
不正利用検知モデルの評価に適している。 |
F1スコアの限界

評価指標として広く使われているF1スコア。一見万能に思えるこの指標にも、実は限界があります。うまく活用するためには、その特性を正しく理解する必要があります。F1スコアは、適合率と再現率の調和平均で計算されます。適合率とは、陽性と予測したデータのうち、実際に陽性だったデータの割合です。一方、再現率は、実際に陽性であるデータ全体のうち、陽性と予測できたデータの割合です。F1スコアはこれらのバランスを重視するため、どちらの値も高いほど、良いスコアとなります。
しかし、現実の問題では、適合率と再現率のどちらをより重視するべきかが、状況によって異なります。例えば、病気の診断の場合を考えてみましょう。病気の人を健康と誤診する(偽陰性)ことは、重篤な結果につながる可能性があります。この場合、偽陰性を最小限に抑える、つまり再現率を高くすることが最優先となります。一方、迷惑メールの判定では、普通のメールを迷惑メールと誤判定する(偽陽性)と、重要な連絡を見逃してしまう可能性があります。この場合は、偽陽性を最小限に抑える、つまり適合率を高くすることが重要になります。このように、F1スコアだけで判断するのではなく、状況に応じて適合率と再現率を個別に評価する必要があります。
さらに、F1スコアはデータの偏りの影響を受けやすいという欠点も持ち合わせています。例えば、陽性データが非常に少ない場合、たとえモデルがすべてのデータを陰性と予測しても、高いF1スコアが得られる可能性があります。これは、実際には役に立たないモデルであるにもかかわらず、指標上は良い値を示してしまうことを意味します。このような場合、F1スコアだけでなく、他の指標も併用して、モデルの性能を多角的に評価することが不可欠です。データの特性を理解した上で、適切な指標を選び、総合的に判断することで、より信頼性の高い評価を行うことができます。
| 評価指標 | 定義 | 長所 | 短所 | 重視する状況 |
|---|---|---|---|---|
| F1スコア | 適合率と再現率の調和平均 | 適合率と再現率のバランスを重視 | データの偏りの影響を受けやすい、状況によっては適合率または再現率をより重視すべき | – |
| 適合率 | 陽性と予測したデータのうち、実際に陽性だったデータの割合 | 偽陽性を最小限に抑える | 偽陰性を軽視する可能性がある | 迷惑メールの判定など、偽陽性を避けたい場合 |
| 再現率 | 実際に陽性であるデータ全体のうち、陽性と予測できたデータの割合 | 偽陰性を最小限に抑える | 偽陽性を軽視する可能性がある | 病気の診断など、偽陰性を避けたい場合 |
まとめ

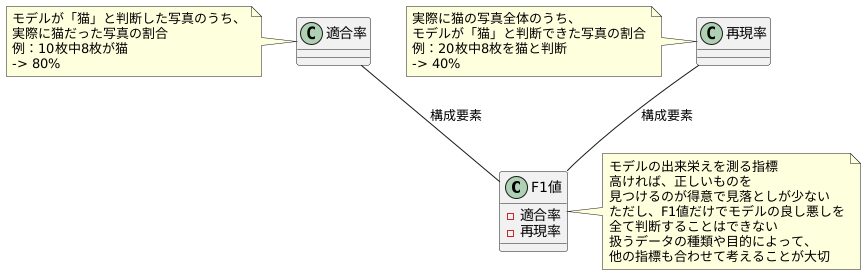
機械学習の出来栄えを測る物差しの一つに、F1値と呼ばれるものがあります。この値は、機械学習モデルがどれくらいきちんと学習できているかを判断するのに役立ちます。具体的には、「適合率」と「再現率」という二つの要素を組み合わせたものです。
適合率とは、モデルが「正しい」と判断したものの中で、実際にどれだけが正しかったのかを示す割合です。一方、再現率は、実際に正しいもの全体の中で、モデルがどれくらい正しく「正しい」と判断できたのかを示す割合です。
例えば、たくさんの写真の中から猫の写真を見つけ出すことを考えてみましょう。モデルが10枚の写真を「猫」と判断し、そのうち8枚が本当に猫の写真だった場合、適合率は80%になります。また、全部で20枚の猫の写真があったとして、モデルがそのうち8枚を正しく「猫」と判断できた場合、再現率は40%になります。
F1値は、この適合率と再現率を両方考慮した値です。どちらか一方だけが良くても、F1値は高くはなりません。つまり、F1値が高いほど、モデルは「正しい」ものを見つけるのが得意で、かつ、見落としが少ないと言えるのです。
ただし、F1値だけでモデルの良し悪しを全て判断することはできません。例えば、病気の診断のように、見落としが許されない場合には、再現率を特に重視する必要があります。また、大量のデータの中から特定の情報を抽出する場合には、適合率を重視する方が良い場合もあります。
F1値はあくまでも一つの目安であり、扱うデータの種類や目的によって、他の指標も合わせて考えることが大切です。F1値を正しく理解し、適切に使うことで、より精度の高い機械学習モデルを作ることができるでしょう。