CTCとは?音声認識の仕組みと接続時系列分類をわかりやすく解説

AIの初心者
「接続時系列分類」って、どういう意味ですか?音声の長さと文字数が合わない問題を扱う方法なんですよね?

AI専門家
その通りだよ。接続時系列分類、つまりCTCは、音声のように長い時系列データから、短い文字列を直接学習しやすくする手法なんだ。どの瞬間がどの文字に対応するかを細かく指定しなくても学習できるのが大きな特徴だよ。
AIの初心者
では、「こんんにちは」や「こんにちはあ」のような途中の出力も、最終的には「こんにちは」と見なせる場合があるんですか?
AI専門家
そうだね。CTCでは、空白記号や同じ文字の繰り返しをうまく整理して、複数の時系列パターンを同じ文字列へまとめる。だから、音の伸びや短い無音があっても、最終的な文字列を推定しやすくなるんだ。
CTCとは。
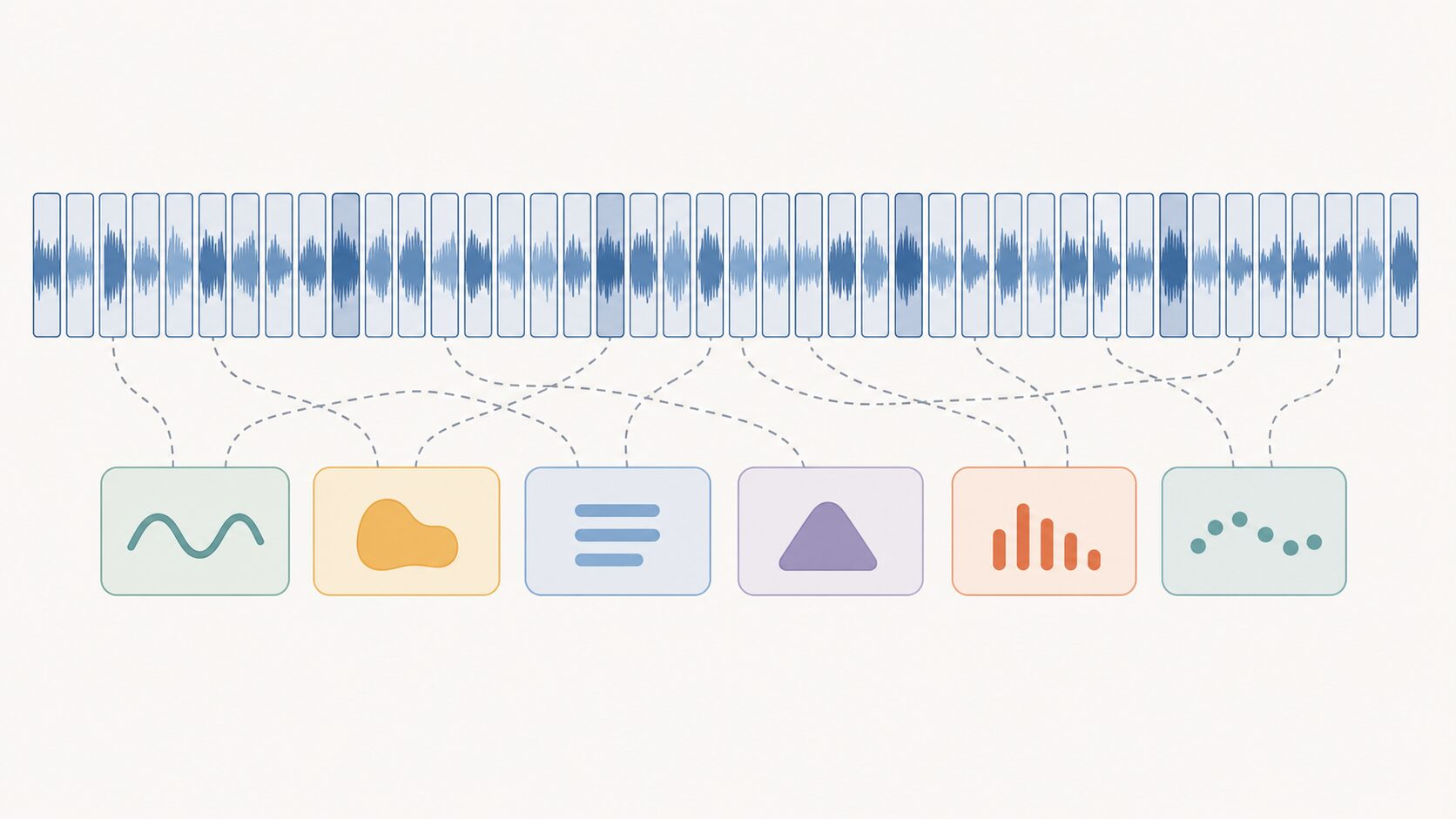
CTCは「Connectionist Temporal Classification」の略で、日本語では「接続時系列分類」と呼ばれます。音声認識では、マイクから得られる音声データは細かい時間単位に分かれますが、出力したい文字列はそれよりずっと短くなります。CTCは、この入力の時間ステップ数と出力文字数が一致しない問題を扱うための機械学習手法です。
CTCとは?音声認識で入力と文字数のずれを扱う仕組み
音声認識は、連続的に変化する音の波形を、文字や単語の列へ変換する技術です。たとえば「こんにちは」と発話した場合、人間にとっては5文字の言葉に見えます。しかしコンピューターが扱う音声は、数十から数百以上の短いフレームに分割された時系列データです。
ここで問題になるのが、音声フレームと文字の対応が一対一ではないことです。「こ」の音が長く伸びることもあれば、「ん」と「に」の境目がはっきりしないこともあります。発話速度、間の取り方、無音区間、雑音、個人差によって、同じ言葉でも波形の長さや形は変わります。
CTCは、このような状況で各フレームに正解文字を手作業で割り当てなくても、音声全体と正解文字列のペアから学習できるようにする方法です。音声認識だけでなく、手書き文字認識や時系列データからラベル列を取り出す問題でも使われます。
| 用語 | 意味 |
|---|---|
| 音声フレーム | 音声を短い時間ごとに区切った入力単位 |
| 文字列 | 認識結果として出したい文字や記号の並び |
| アラインメント | どの入力時刻がどの文字に対応するかという対応関係 |
| CTC | アラインメントが未知でも、入力系列から出力系列を学習するための手法 |
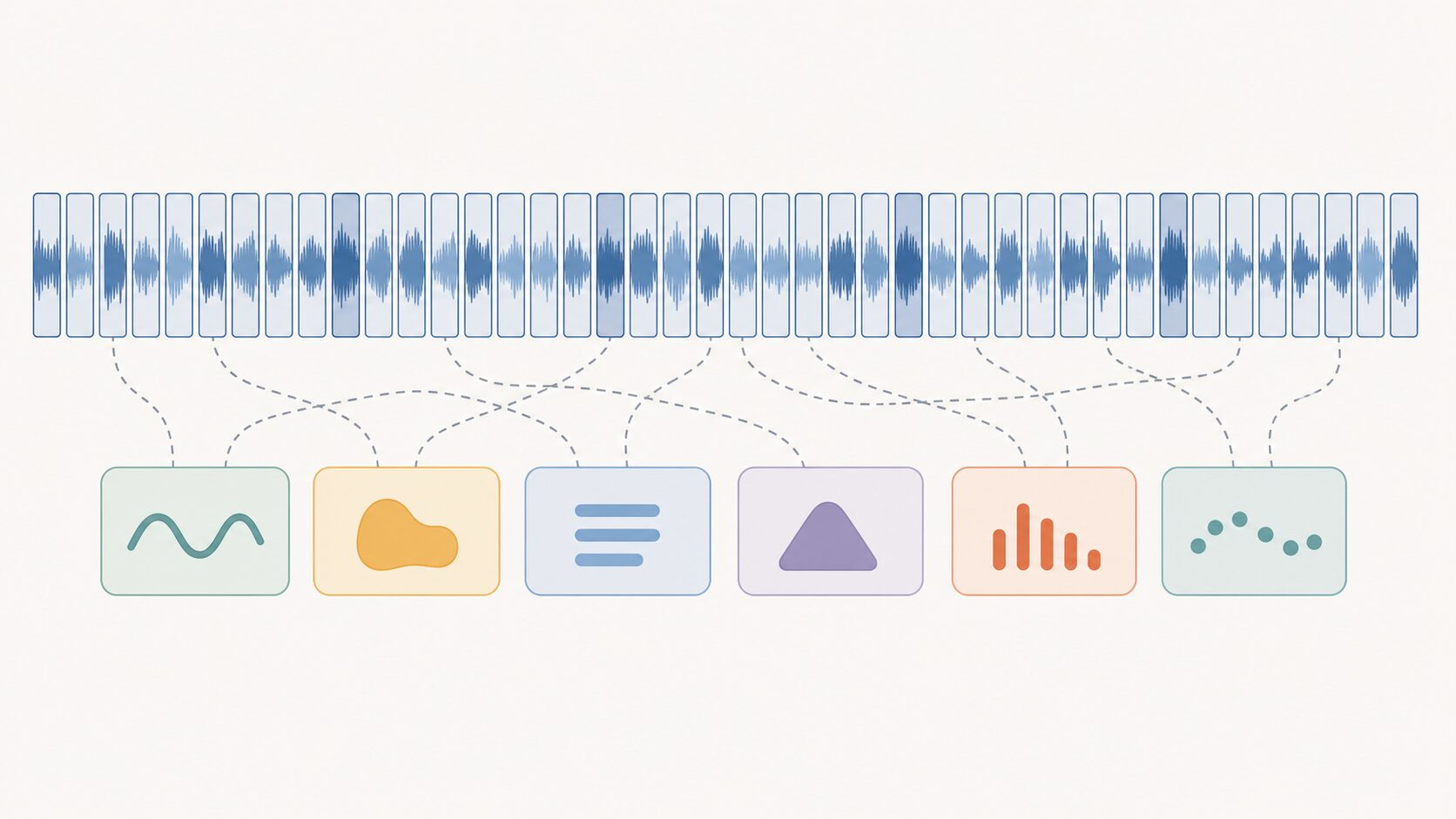
なぜ音声とテキストはそのまま対応しないのか

従来の考え方では、音声データの各時刻に「この部分は『こ』」「この部分は『ん』」のようなラベルを付ける必要がありました。しかし実際の音声では、文字の境界を正確に切り出すのは簡単ではありません。「こんにちは」の「こ」がどこで終わり、「ん」がどこから始まるのかは、波形だけを見ても明確に決めにくいからです。
また、音声には文字に対応しない部分も含まれます。息継ぎ、短い沈黙、発音の揺れ、周囲の雑音などは、最終的な文字列には現れません。一方で、音が伸びているだけなのか、同じ文字を本当に繰り返しているのかを見分ける必要がある場面もあります。
CTCは、こうした長さの不一致と境界のあいまいさを前提にします。音声フレームごとにただ1つの正解を固定するのではなく、正解文字列につながる複数の可能な並びをまとめて考えることで、学習の負担を軽くします。
CTCが使う空白記号と繰り返しの考え方
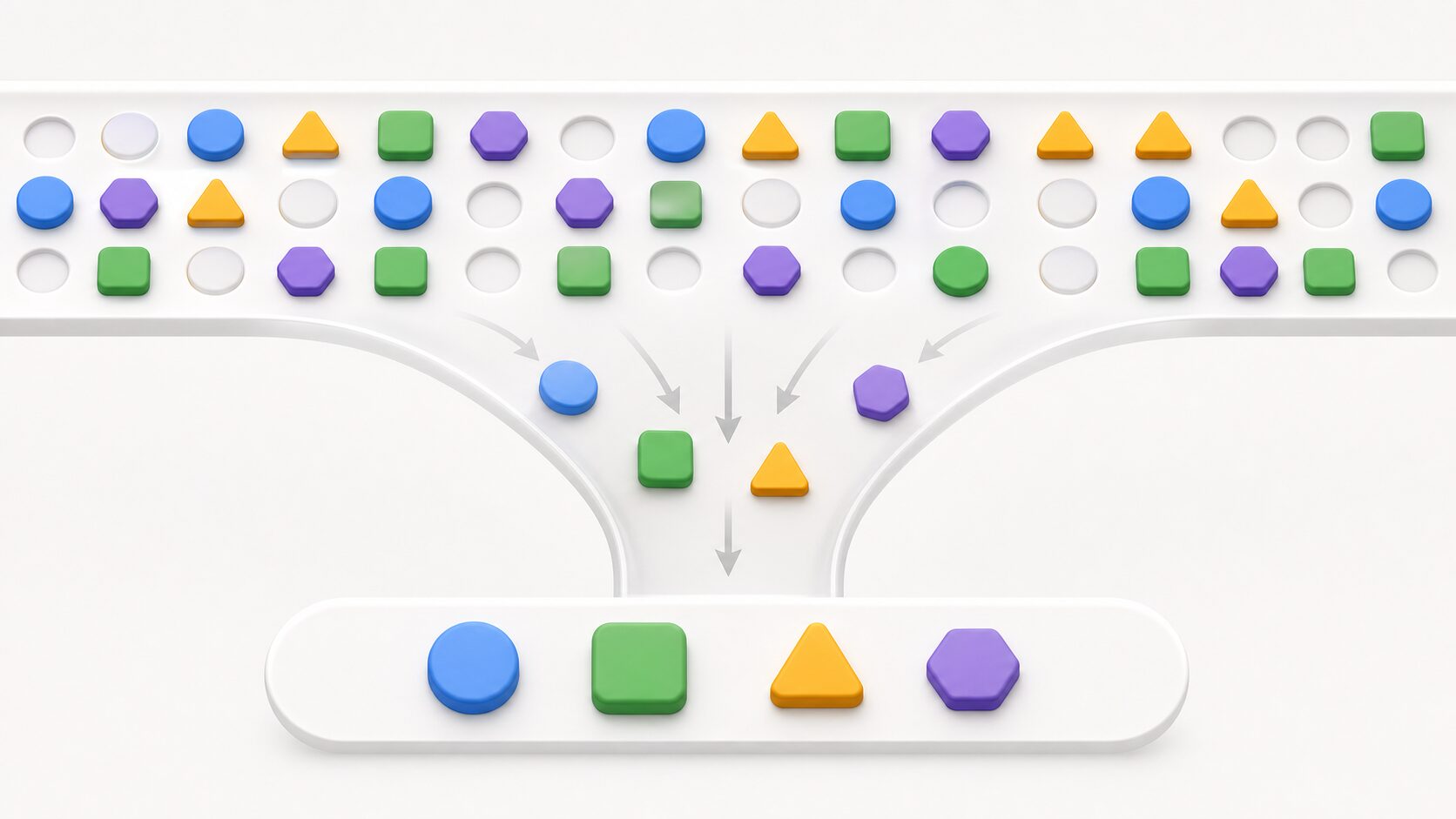
CTCの理解で重要なのが、「空白記号」と「繰り返し」です。ここでいう空白は、文章中のスペースとは別の、CTC内部で使う特別な記号です。音声フレームの中には、どの文字にも対応しない時間があります。そのような部分を表すために、CTCは空白記号を使います。
もう1つのポイントは、同じ文字が連続して出ることを許す点です。たとえば「こ」の音が長く続くと、モデルは複数の連続したフレームで「こ」を出すかもしれません。CTCでは、同じ文字の連続を1つにまとめ、さらに空白記号を取り除くことで、最終的な文字列を得ます。
例として、空白を「_」で表すと、「こ_ん_に_ち_は」や「ここ_ん_に_ち_は」のような時系列出力は、整理すると「こんにちは」になります。大切なのは、CTCが「どんな誤りでも正解にする」わけではないことです。同じ最終文字列に畳み込める時系列パターンを、確率的にまとめて扱うのがCTCの考え方です。
| CTC内部の出力例 | 処理 | 最終文字列 |
|---|---|---|
| こ_ん_に_ち_は | 空白を削除 | こんにちは |
| ここ_ん_に_ち_は | 連続する同じ文字をまとめ、空白を削除 | こんにちは |
| こ_ん_に_ち_は_ | 末尾の空白も削除 | こんにちは |
複数のパスを1つの文字列にまとめる流れ
CTCでは、音声フレームごとの出力候補の並びを「パス」と考えます。あるパスは「こ、こ、_、ん、_、に、ち、は」のような並びかもしれませんし、別のパスは「_、こ、_、ん、に、に、ち、は」のような並びかもしれません。これらは内部的には違う時系列ですが、空白の削除と繰り返しの統合を行うと、同じ「こんにちは」へ変換されることがあります。
学習時には、正解文字列へ畳み込めるすべてのパスを1つずつ手で列挙するのではなく、効率よく合計して確率を計算します。これにより、モデルは「この時刻が必ずこの文字」と固定されなくても、正解文字列に近づく方向へ学習できます。
この仕組みによって、CTCは発話速度の違いや音の伸びを吸収できます。短く発話された「こんにちは」と、ゆっくり発話された「こーんにちは」は、フレーム数が違っても、同じ文字列へつながる複数のパスとして扱えるからです。
CTCの学習では何を最適化しているのか
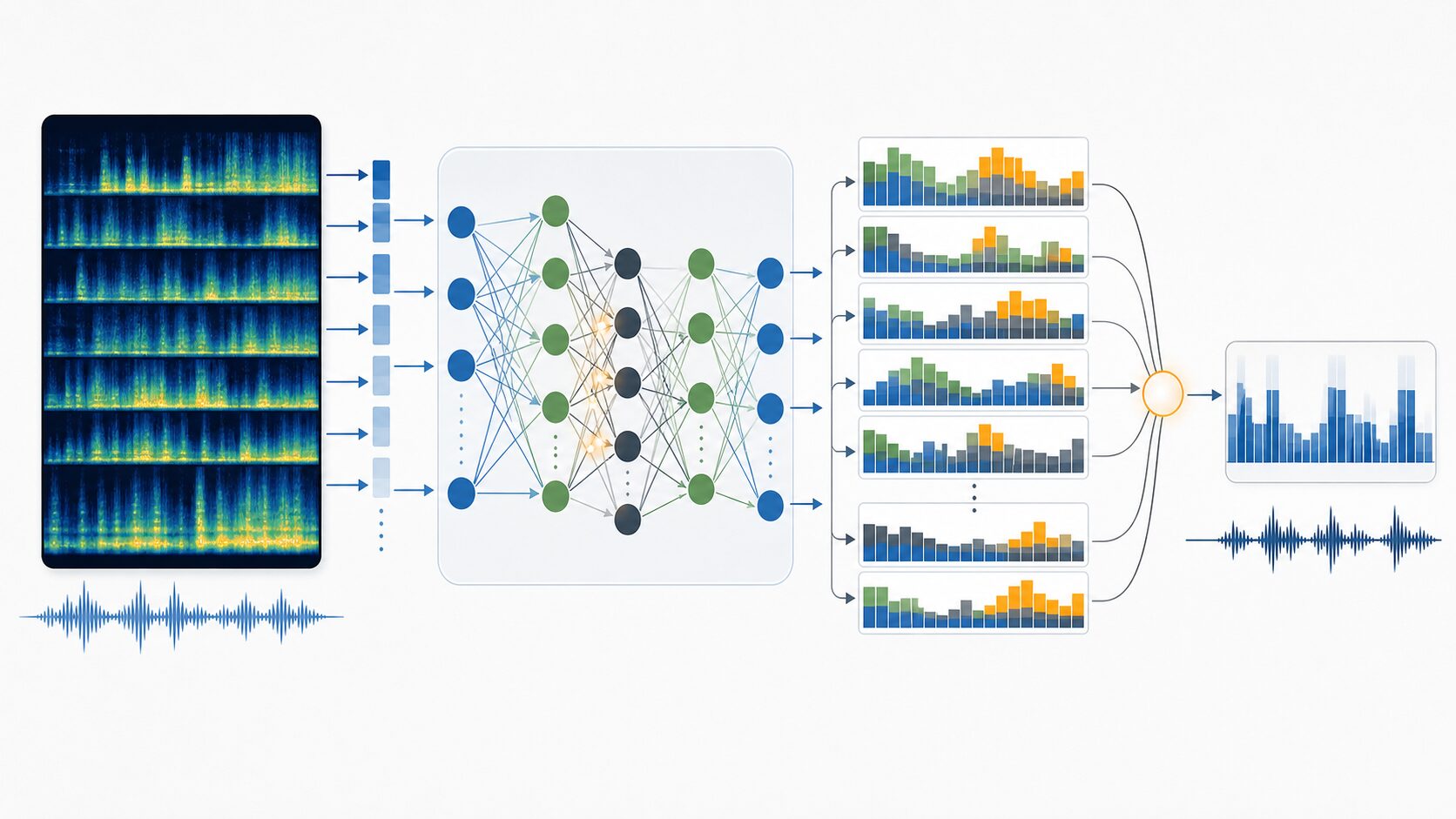
CTCを使うモデルは、音声特徴量を入力として受け取り、各時刻について「空白」「こ」「ん」「に」などの候補がどれくらいありそうかを確率として出力します。最初は見当違いな確率を出すかもしれませんが、正解文字列と比較しながら、正解に対応するパス全体の確率が高くなるように重みを更新します。
このとき、モデルが直接覚えるのは「何秒から何秒までが『こ』」という固定的な境界ではありません。正解文字列へ変換できるパスの確率を高めることで、結果として音声と文字の対応を学んでいきます。ニューラルネットワーク、十分な音声データ、正解テキスト、計算資源が必要になるのはこのためです。
実務では、CTC単体で使われる場合もありますが、前段の音声特徴抽出、エンコーダーモデル、後段の言語モデルやデコーダーと組み合わせて使われることも多くあります。音としては似ている候補が複数ある場合、文脈から自然な語を選ぶには、CTC以外の情報も重要になるためです。
従来手法との違いとCTCのメリット
CTC以前の音声認識では、音声フレームと文字の対応を事前に用意する、または複雑な前処理で推定する必要がありました。これは大量のデータを扱うほど負担が大きく、境界の付け方によって学習結果も影響を受けます。
CTCのメリットは、正解文字列だけを用意すれば、細かな境界ラベルなしで学習しやすいことです。音声と文字の長さが違っていても扱えるため、音声入力、文字起こし、音声検索のような実用的なタスクに向いています。
ただし、CTCは万能ではありません。強い雑音がある音声、話者が重なっている音声、専門用語や固有名詞が多い文章、長い文脈を使わないと判断しにくい表現では、認識品質が落ちることがあります。そのため、データの品質、ノイズ対策、モデル構造、辞書や言語モデルの設計も同時に考える必要があります。
| 観点 | 従来の対応付け中心の方法 | CTC |
|---|---|---|
| 音声と文字の長さ | 対応をそろえる工夫が必要 | 長さが違っていても扱える |
| 境界ラベル | 細かいラベル付けが負担になりやすい | 正解文字列だけで学習しやすい |
| あいまいな発音 | 境界のずれが誤りにつながりやすい | 複数のパスをまとめて確率的に扱える |
| 注意点 | 前処理やラベル品質に依存しやすい | 文脈理解や雑音対策は別途重要 |
CTCの活用例と実務での注意点
CTCは、スマートフォンの音声入力、会議や講義の文字起こし、音声検索、コールセンター音声の分析、多言語音声翻訳など、音声を文字に変える場面で活用されます。どの用途でも、入力音声の長さと出力文字列の長さが一致しないため、CTCの考え方が役立ちます。
一方で、実務で音声認識を使う場合は、CTCの仕組みだけを理解しても十分ではありません。マイク品質、録音環境、話者の発音、背景ノイズ、専門用語の多さ、学習データの偏りによって結果は大きく変わります。たとえば、静かな部屋の短い音声入力では高精度でも、複数人が同時に話す会議では誤認識が増えることがあります。
また、CTCは時系列の対応付けを扱う強力な方法ですが、長い文脈を深く理解する仕組みそのものではありません。同音異義語や文脈依存の表現を自然に選ぶには、言語モデル、Transformerベースのモデル、辞書、後処理などと組み合わせて品質を高める設計が重要です。
まとめ
CTCは、音声認識における「入力音声は長い時系列、出力文字列は短い記号列」というずれを扱うための重要な手法です。空白記号と繰り返しを使い、複数の時系列パスを同じ文字列へまとめることで、音の伸び、無音、発話速度の違いを吸収します。
初心者が押さえるべきポイントは、CTCが細かな文字境界を手作業で決めずに学習できる仕組みだという点です。ただし、認識精度はCTCだけで決まるわけではなく、学習データ、モデル構造、ノイズ対策、文脈処理も重要です。CTCを理解すると、音声認識モデルがなぜ「長さの違う音声と文字」を結びつけられるのかが見えやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月20日 | CTCの変換規則と学習時の見方を補い、音声認識での位置づけを調整 |