全文検索とベクトル検索のインデックス入門|仕組みと使い分け

AIの初心者
AI検索やRAGでは、全文検索とベクトル検索をどう使い分ければよいですか?

AI専門家
どちらも検索を速くするためのインデックスですが、対象にするデータが違います。転置インデックスは主にキーワード検索や全文検索で使い、IVFはベクトル検索で候補を絞るために使います。
AIの初心者
「inverted」という言葉が両方に出てくるので混乱します。RAGやベクトルデータベースの説明でも出てきますよね。
AI専門家
そこがつまずきやすい点です。この記事では、検索インデックスの基本から、転置インデックスとIVFの役割、使い分け、RAGでの考え方まで順番に整理します。
検索インデックスとは。
検索インデックスとは、データを毎回すべて調べなくても目的の候補へ速くたどり着けるようにする索引です。全文検索では、単語からその単語を含む文書を引けるようにした転置インデックスがよく使われます。ベクトル検索では、大量のベクトルをクラスタに分け、近そうな領域だけを調べるIVFのような方式が使われます。どちらも検索を速くする仕組みですが、扱うデータと得意な検索が違います。
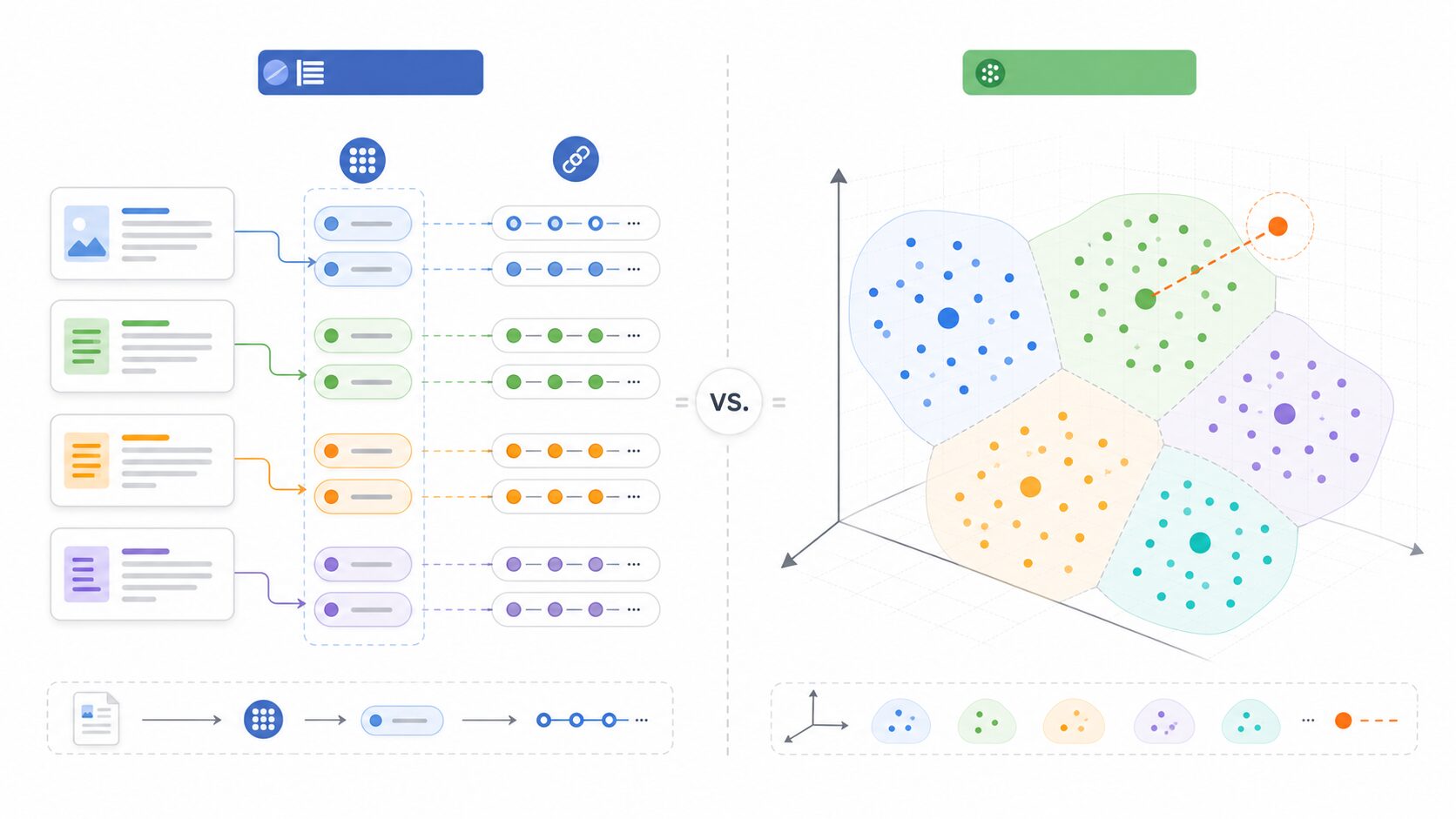
AI検索、RAG、ベクトルデータベースを学び始めると、「転置インデックス」「IVF」「BM25」「Embedding」「近似最近傍探索」といった用語が一気に出てきます。どれも検索に関係するため、最初は同じ種類の技術に見えます。しかし、実際には役割がかなり違います。
転置インデックスは、検索エンジンや全文検索システムで長く使われてきた基本的な仕組みです。たとえば「請求書」という単語を含む文書を探したいとき、全ての文書を1つずつ読んで確認するのではなく、「請求書」という見出しの下に、その単語を含む文書IDの一覧を用意しておきます。これにより、検索時には文書全体を毎回走査せずに候補を取り出せます。
一方、IVFはベクトル検索で使われる代表的なインデックス方式の1つです。ベクトル検索では、文章や画像などを数百次元、数千次元の数値の並びに変換し、意味が近いものほど距離が近くなるように扱います。大量のベクトルを毎回すべて比較すると時間がかかるため、あらかじめ似たベクトル同士を大まかなグループに分け、検索時には近そうなグループだけを見るようにします。この考え方がIVFの中心です。
重要なのは、転置インデックスは「どの単語がどの文書に出るか」を引く索引で、IVFは「どのベクトル群が検索ベクトルに近そうか」を絞る索引だという点です。名前に似た雰囲気があっても、検索対象、得意な検索、調整すべきパラメータが違います。
検索インデックスを一言で整理する
まず、両者を短く整理します。転置インデックスは、キーワード検索や全文検索のための索引です。文書を単語やトークンに分け、「この単語はどの文書に出てくるか」という対応表を作ります。検索語が来たら、その検索語に対応する文書一覧を取り出し、出現頻度、出現位置、文書の長さなどを使って順位付けします。
IVFは、ベクトル検索のための索引です。文章や画像をEmbeddingモデルでベクトル化し、それらを複数のクラスタに分けます。検索クエリもベクトル化し、そのクエリベクトルに近いクラスタをいくつか選び、その中の候補だけを詳しく比較します。つまり、全件比較を避けるための近似的な候補絞り込みです。
転置インデックスが得意なのは、検索語と文書内の語が一致する場面です。「エラーコード A-102」「契約解除」「インボイス制度」のように、言葉そのものが重要な検索では非常に強力です。表記ゆれや同義語への対応は別途工夫が必要ですが、単語の一致を基礎にした検索では高速かつ説明しやすい方式です。
IVFが得意なのは、検索語と文書内の語が完全には一致しなくても、意味が近い文書を探したい場面です。「支払い期限を過ぎた取引先への対応」と検索したとき、「売掛金の督促手順」「入金遅延時の連絡フロー」のような文書を拾いたい場合、単純なキーワード一致だけでは漏れが出ます。ベクトル検索は、表現が違っても意味が近い候補を探すために使われます。
ただし、IVFは「意味を理解して答えを作る仕組み」ではありません。IVFはあくまでベクトルを速く探すためのインデックスです。意味の近さを作るのはEmbeddingモデルであり、候補から最終順位を決めるのは距離計算、スコアリング、再ランキングなどです。ここを混同すると、ベクトルデータベースを導入すれば自動的に高精度な検索ができる、と誤解しやすくなります。
転置インデックスの仕組み
転置インデックスは、文書検索のための「逆引き表」です。通常、文書を読むときは「文書Aの中にどんな単語があるか」という向きで考えます。転置インデックスではその向きを逆にし、「単語Xはどの文書に出てくるか」という形で索引を作ります。この反転した見方が「転置」と呼ばれる理由です。
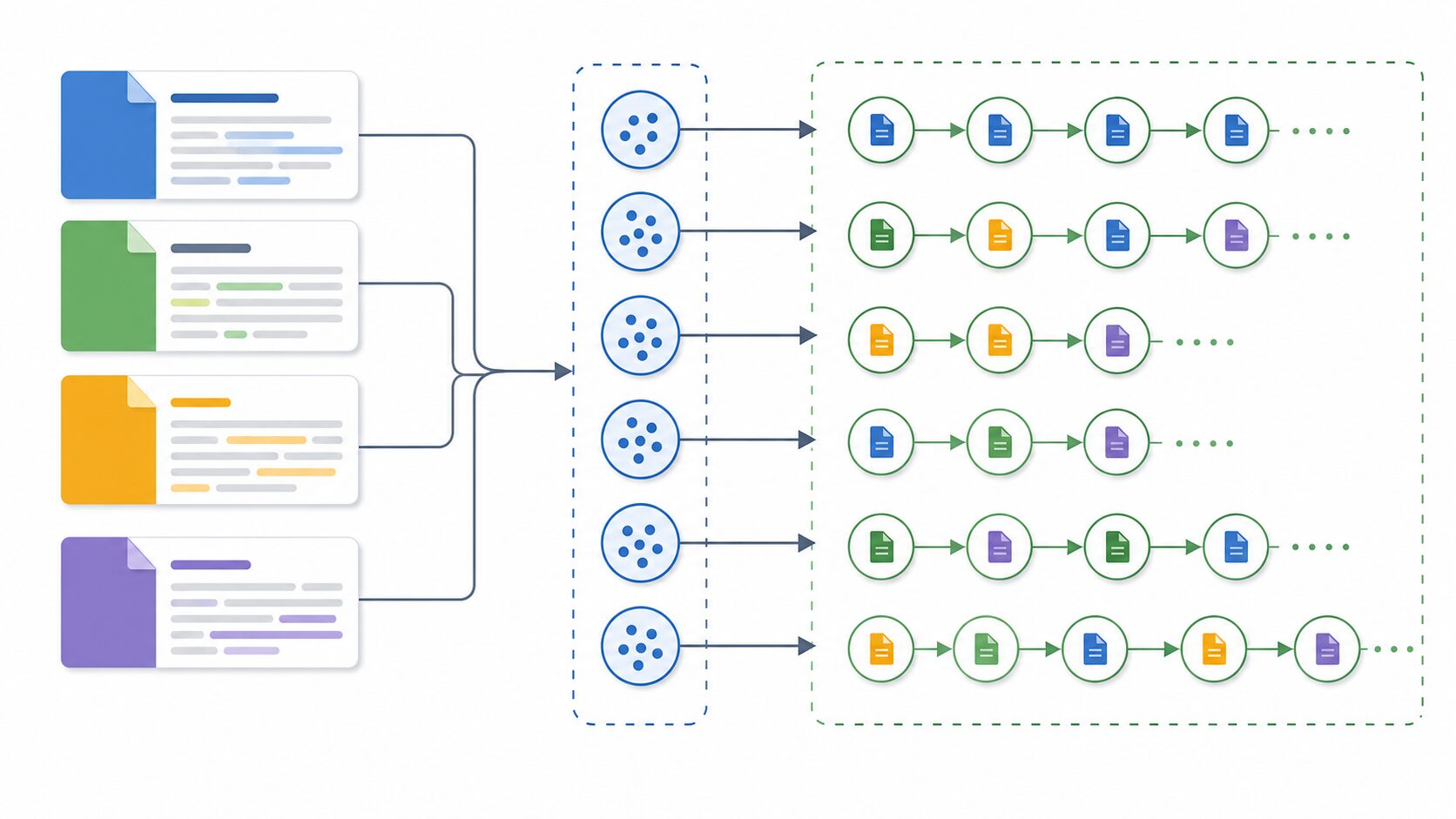
たとえば、3つの文書があるとします。文書1には「AI 検索 インデックス」、文書2には「全文検索 インデックス」、文書3には「AI ベクトル検索」という語が含まれているとします。このとき、転置インデックスは「AI: 文書1, 文書3」「検索: 文書1」「インデックス: 文書1, 文書2」「全文検索: 文書2」「ベクトル検索: 文書3」のような対応表になります。
実際の検索エンジンでは、これに加えて多くの情報を持ちます。単語が文書内に何回出たか、タイトルに出たか本文に出たか、どの位置に出たか、近くにどんな語があるか、文書全体の長さはどれくらいか、といった情報です。これらを使うことで、「単に語が含まれている文書」ではなく、「検索意図に合っていそうな文書」を上位に出せます。
全文検索でよく使われるBM25は、転置インデックスと組み合わせて使われる代表的なランキング手法です。BM25は、検索語が文書に出る頻度、検索語の珍しさ、文書の長さなどを考慮してスコアを計算します。珍しい語が適切に含まれている文書は高く評価されやすく、ただ長いだけで多くの語を含む文書が有利になりすぎないように調整されます。
日本語では、転置インデックスを作る前に分かち書きや形態素解析が重要になります。英語のように単語が空白で区切られていないため、「機械学習」「機械」「学習」をどの単位で扱うかによって検索結果が変わります。検索エンジンによっては、形態素解析に加えてN-gramという文字単位の分割を使うこともあります。
転置インデックスの強みは、検索語が文書中に存在するかどうかを高速に確認でき、なぜヒットしたのかを説明しやすいことです。検索結果にハイライトを付けたり、「この文書はこの語を含むためヒットしました」と説明したりしやすいのも利点です。業務システムのログ検索、規程検索、商品番号検索、FAQ検索など、語の一致が重要な場面では今でも中心的な技術です。
一方で、転置インデックスは意味の近さを直接扱うわけではありません。「料金」と「価格」、「退職」と「離職」、「支払い遅延」と「入金遅れ」のような関係は、人間には近く見えても、文字列としては別の語です。同義語辞書、表記ゆれ補正、クエリ拡張、ランキング改善を組み合わせないと、検索漏れが起きることがあります。
IVFの仕組み
IVFは、ベクトル検索で候補数を減らすためのインデックス方式です。正式には Inverted File Index と呼ばれます。名前に「Inverted」が入るため転置インデックスと混同されがちですが、全文検索の単語索引とは対象が違います。IVFで扱うのは、単語そのものではなく、Embeddingモデルによって作られた数値ベクトルです。
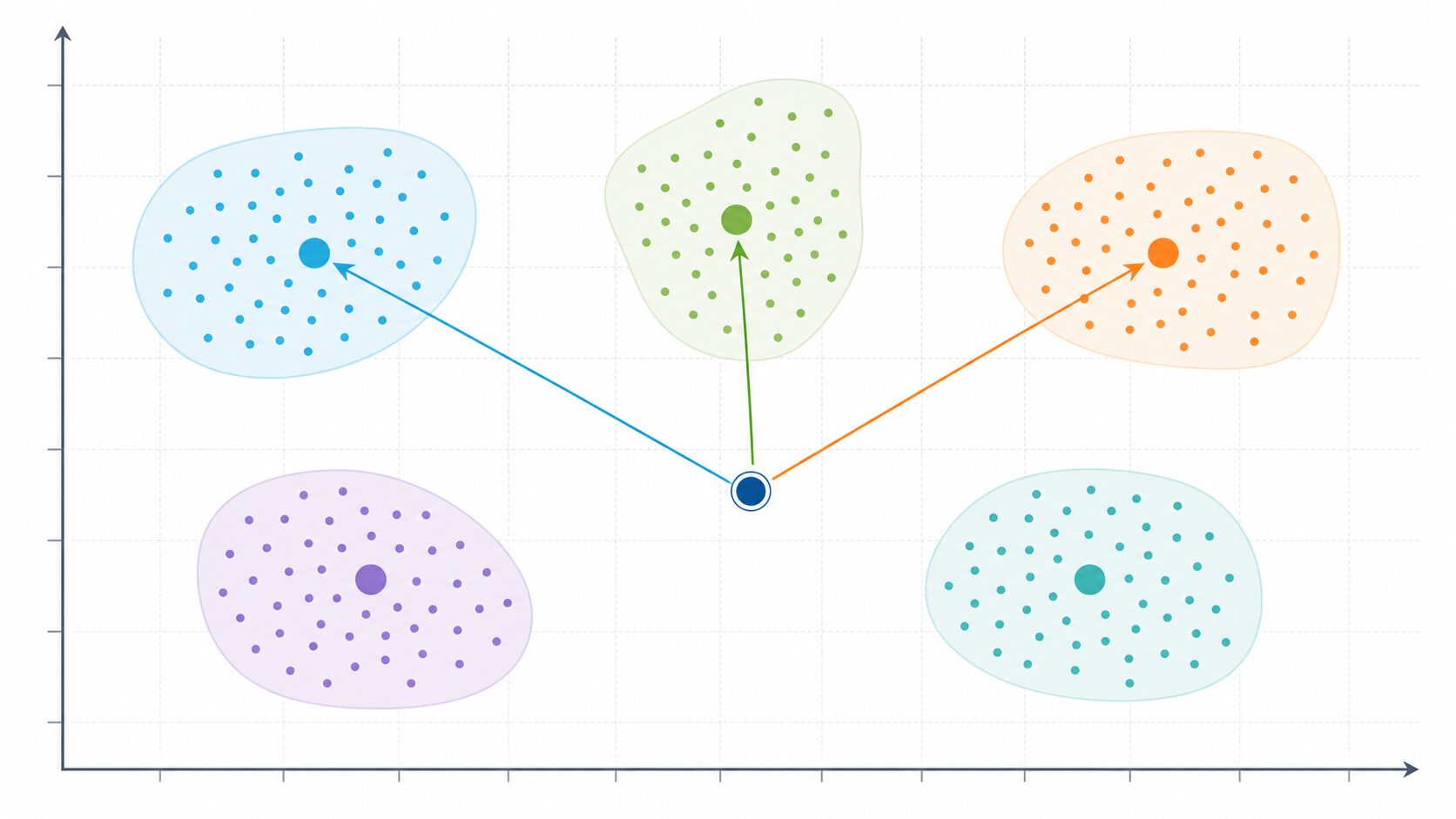
ベクトル検索では、文書、段落、画像、質問文などをベクトルに変換します。近い意味を持つデータは、ベクトル空間上でも近い位置に配置されることが期待されます。検索時には、クエリも同じEmbeddingモデルでベクトル化し、そのクエリベクトルに近いデータを探します。これが最近傍探索です。
データ件数が少ない場合は、クエリベクトルと全てのデータベクトルを比較しても問題ありません。しかし、数十万件、数百万件、数千万件になると、全件比較は重くなります。そこで使われるのが近似最近傍探索、つまりANNです。ANNは、厳密に全件を調べる代わりに、かなり近い候補を高速に見つけるための方法です。
IVFでは、まず大量のベクトルをいくつかのクラスタに分けます。クラスタの代表点はセントロイドと呼ばれます。検索時には、クエリベクトルに近いセントロイドを探し、そのセントロイドに対応するクラスタ内のベクトルだけを詳しく比較します。これにより、全データを見るよりも少ない計算で候補を取り出せます。
たとえば100万件のベクトルを1000個のクラスタに分けたとします。検索時に全100万件を比較する代わりに、近いクラスタを10個だけ調べれば、比較対象を大きく減らせます。もちろん、クラスタの分け方や調べるクラスタ数によって、速度と精度のバランスは変わります。
IVFでよく出てくるパラメータに、クラスタ数やnprobeがあります。クラスタ数を増やすと1クラスタあたりの候補は少なくなりますが、クラスタ分割が細かくなりすぎると、近い候補が別クラスタに分かれて見逃される可能性もあります。nprobeは検索時にいくつのクラスタを調べるかを表すことが多く、nprobeを増やすと精度は上がりやすい一方で検索は遅くなります。
IVFの本質は、ベクトル空間を先に大まかに区切り、検索時には近そうな区画だけを調べることです。地図で考えると、全国の全住所を1件ずつ調べるのではなく、まず都道府県や市区町村のような大きな区画で絞り、その中で詳しく探すイメージに近いです。
ただし、IVFは近似検索です。設定やデータ分布によっては、本当に近いベクトルが調べなかったクラスタに入っていて、検索結果から漏れることがあります。そのため、IVFを使うときは速度だけでなく、再現率、検索件数、再ランキング、評価データを合わせて考える必要があります。
全文検索とベクトル検索の違い
検索インデックスの違いを理解するには、まず全文検索とベクトル検索の違いを押さえる必要があります。全文検索は、文書に含まれる単語や文字列をもとに候補を探します。ベクトル検索は、データを数値ベクトルに変換し、距離や類似度をもとに候補を探します。
全文検索は、検索語が明確なときに強いです。商品型番、エラーコード、人名、契約条項名、法令名、専門用語など、文字列の一致が重要な情報では、転置インデックスによる検索が非常に有効です。また、検索結果の根拠を説明しやすい点も重要です。「この語がタイトルに含まれている」「本文中に3回出ている」といった説明ができます。
ベクトル検索は、表現が揺れる問い合わせに強いです。ユーザーが「ログインできない」と入力したとき、「認証に失敗する」「パスワード再設定」「アカウントロック」のような関連文書を探したい場合、単語一致だけでは拾いきれないことがあります。ベクトル検索では、Embeddingモデルが学習した意味的な近さを利用して候補を探します。
ただし、ベクトル検索は万能ではありません。数字、固有名詞、コード、日付、型番のように、1文字の違いが重要な検索では、ベクトルの意味的な近さだけに頼ると危険です。「A-102」と「A-120」はベクトル上では近く扱われる可能性がありますが、業務上はまったく別のエラーかもしれません。このような場面では全文検索やフィルタ条件が必要です。
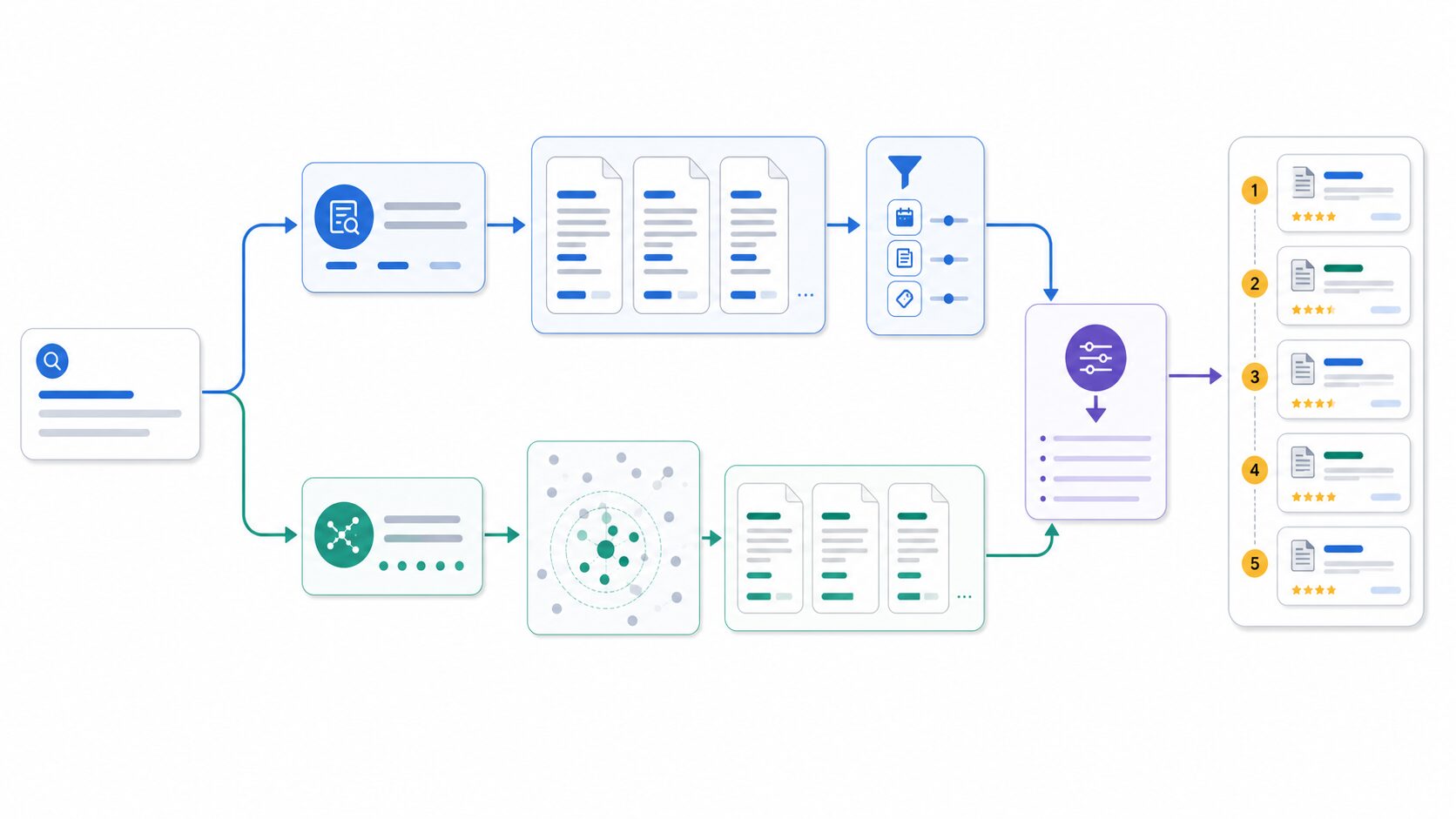
RAGでは、全文検索とベクトル検索を組み合わせることがよくあります。これをハイブリッド検索と呼ぶことがあります。キーワード一致で確実に拾うべき文書を集めつつ、ベクトル検索で意味的に近い文書も集め、最後にスコアを統合したり再ランキングしたりします。
検索システムの設計では、どちらが新しいか、どちらがAIらしいかではなく、検索対象と検索意図で選ぶことが重要です。社内規程の条文番号を探すなら全文検索が合います。問い合わせ文から関連FAQを探すならベクトル検索が有効です。両方の性質が必要なら、組み合わせて設計します。
代表的な検索インデックスの比較
全文検索で使う転置インデックスと、ベクトル検索で使うIVFを比べると、検索設計で見るべき違いがはっきりします。
| 観点 | 転置インデックス | IVF |
|---|---|---|
| 主な用途 | 全文検索、キーワード検索、ログ検索、文書検索 | ベクトル検索、近似最近傍探索、意味検索 |
| 扱うデータ | 単語、トークン、文書ID、出現位置 | Embeddingベクトル、クラスタ、セントロイド |
| 検索の考え方 | 検索語を含む文書を逆引きする | クエリベクトルに近いクラスタを調べる |
| 得意な検索 | 語句一致、固有名詞、型番、専門用語 | 意味の近さ、表現ゆれ、類似文書探索 |
| 注意点 | 同義語や言い換えに弱い場合がある | 近似検索なので候補漏れや調整が発生する |
| 代表的な関連語 | BM25、形態素解析、N-gram、posting list | ANN、Embedding、nprobe、ベクトルデータベース |
この表で特に大切なのは、扱うデータの違いです。転置インデックスは、文書を単語単位で見ます。IVFは、文書やチャンクをベクトルとして見ます。つまり、同じ文書検索でも、どの表現に変換してから探すのかが違います。
また、転置インデックスは検索語が文書に出ているかどうかを基礎にするため、ヒット理由を追いやすい傾向があります。IVFを使ったベクトル検索では、候補が近い理由を人間が直感的に説明しにくいことがあります。特に企業利用では、検索結果の説明可能性や監査性が必要になるため、両者の違いは実務上も重要です。
使い分けと具体例
実務では、転置インデックスとIVFのどちらか一方だけを覚えるより、検索したい対象に応じて使い分けることが大切です。検索対象が「言葉そのもの」なのか、「意味の近さ」なのかを考えると判断しやすくなります。
たとえば、社内のログ検索を考えます。エラーコード、ユーザーID、IPアドレス、処理名、発生時刻などを探す場合、転置インデックスや条件検索が向いています。ユーザーが入力した文字列とログ内の文字列が一致することに意味があるためです。この場合、ベクトル検索だけに頼ると、似ているが違うコードを拾ってしまうリスクがあります。
一方、社内FAQを自然文で検索する場合は、ベクトル検索が役立ちます。ユーザーは「経費精算の領収書をなくした」と入力するかもしれませんが、FAQの見出しは「証憑紛失時の申請手順」かもしれません。言葉が一致しなくても、意味が近ければ候補に出したい場面です。
商品検索では、両方が必要になることが多いです。型番、ブランド名、サイズ、色などは文字列一致が重要です。一方で、「軽い通勤用バッグ」「雨の日に使いやすい靴」のような検索では、意味や属性の近さも重要になります。転置インデックスで確実な条件を拾い、ベクトル検索で曖昧なニーズを補う設計が考えられます。
RAGで社内文書を検索する場合も同じです。就業規則の第何条を探す、特定のシステム名を含む仕様書を探す、といった検索では全文検索が強いです。ユーザーの質問に関連する説明箇所を探す、言い換えられた問い合わせに対応する、といった検索ではベクトル検索が強いです。
ハイブリッド検索では、転置インデックスとベクトル検索の結果を別々に取得し、それらを統合します。単純にスコアを足す方法もありますが、スコアの尺度が違うため注意が必要です。BM25のスコアとベクトル類似度は同じ意味ではありません。そのため、順位の統合、正規化、再ランキングモデルの利用などが検討されます。
初心者におすすめの考え方は、最初から複雑な構成にしすぎないことです。検索対象が小さいうちは、まず全文検索だけ、またはベクトル検索だけで評価し、どのような失敗が起きるかを観察します。そのうえで、検索漏れ、ノイズ、固有名詞の取り違え、回答生成の誤りを見ながら、必要な方式を追加していくと理解しやすくなります。
RAGで考えるときの実務的な注意点
RAGでは、検索インデックスの選び方が回答品質に大きく影響します。RAGは、外部文書を検索し、その検索結果を大規模言語モデルに渡して回答を生成する仕組みです。検索で必要な文書が取れなければ、生成モデルがどれだけ高性能でも正しい回答は難しくなります。
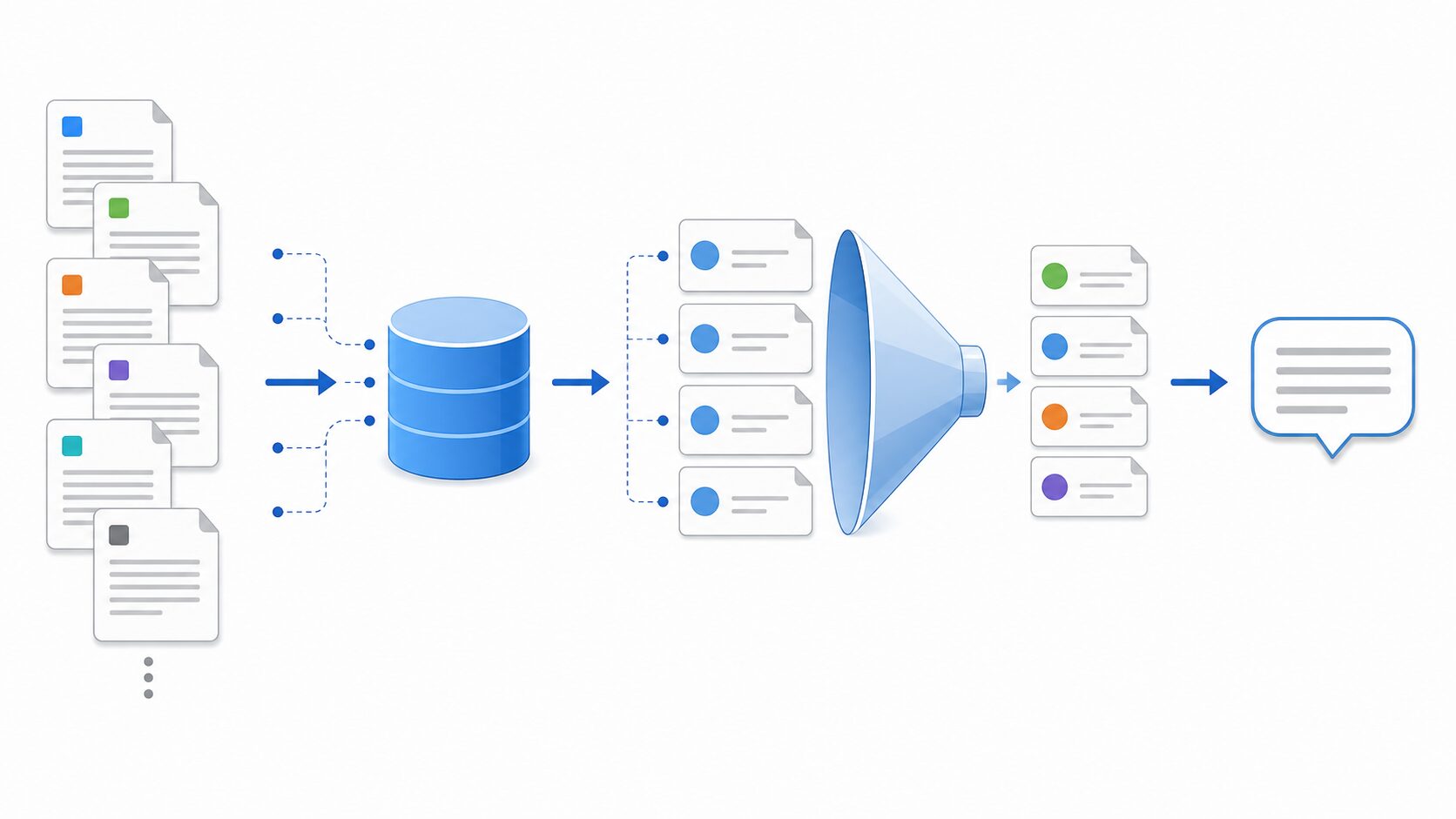
転置インデックスとIVFは、RAGの中では主に「候補を集める」段階で使われます。転置インデックスはキーワード一致に基づいて候補を集め、IVFはベクトルの近さに基づいて候補を集めます。その後、候補を再ランキングし、上位の文書を回答生成に渡す設計がよく使われます。
ここで注意したいのは、インデックス方式だけでRAGの品質が決まるわけではないことです。チャンクの切り方、メタデータの付け方、Embeddingモデルの選定、検索件数、再ランキング、プロンプト設計、回答の引用表示など、複数の要素が関係します。IVFを使って検索が速くなっても、チャンクが不適切なら必要な情報は取り出せません。
たとえば、1つの社内規程を長い1チャンクとして登録すると、検索には引っかかっても、回答生成に渡す情報が広すぎて焦点がぼやけることがあります。逆に、細かく分けすぎると、文脈が失われて正しい判断が難しくなることがあります。転置インデックスでもベクトル検索でも、チャンク設計は検索精度に直結します。
また、IVFを使う場合は近似検索の性質を理解する必要があります。高速化のために調べるクラスタ数を減らすと、検索漏れが増える可能性があります。RAGでは、重要な根拠文書が1つ漏れただけで回答が変わることがあります。そのため、速度、コスト、再現率のバランスを評価することが重要です。
全文検索を使う場合も、検索語の分割や表記ゆれに注意が必要です。日本語の社内文書では、同じ意味でも「申請」「届出」「提出」「登録」のように語が揺れることがあります。転置インデックスだけでは拾いきれない場合、同義語辞書やクエリ拡張、ベクトル検索との併用が有効です。
RAGを設計するときは、検索、再ランキング、回答生成を分けて評価することが大切です。検索段階で正しい文書が候補に入っているか、再ランキングで上位に来ているか、生成モデルが根拠を正しく使っているかを分けて確認します。そうしないと、失敗の原因がインデックスなのか、Embeddingなのか、プロンプトなのか分からなくなります。
初心者がつまずきやすいポイント
1つ目のつまずきは、「転置インデックス」と「IVF」を名前だけで同じものだと思ってしまうことです。どちらにも inverted という語が関係しますが、転置インデックスは単語から文書を引くための索引で、IVFはベクトルをクラスタに分けて候補を絞るための索引です。対象データが違うため、同じ説明で理解しようとすると混乱します。
2つ目は、ベクトル検索を意味理解そのものだと思ってしまうことです。ベクトル検索は、Embeddingモデルが作ったベクトルの近さを使います。つまり、意味の近さはEmbeddingモデルの品質、学習データ、入力文の作り方に依存します。IVFはそのベクトルを高速に探す手段であり、意味の良し悪しを作る部品ではありません。
3つ目は、全文検索を古い技術だと誤解することです。生成AIやベクトル検索が注目されると、キーワード検索は不要に見えるかもしれません。しかし、固有名詞、専門用語、ID、品番、日付、金額、法令名など、文字列一致が不可欠な場面は多くあります。AI検索の実務では、全文検索は今でも重要な基盤です。
4つ目は、評価をせずにパラメータだけを調整することです。IVFのクラスタ数やnprobe、検索件数、チャンクサイズ、BM25の設定などは、データと目的によって適切な値が変わります。正解データや評価クエリを用意せずに調整すると、体感だけで判断することになり、改善したのか悪化したのか分かりません。
5つ目は、検索結果の上位だけを見て判断してしまうことです。RAGでは、検索結果の1位が少し違うだけでも回答が変わることがあります。上位に正しい根拠が入っているか、不要な文書が混ざっていないか、似ているが誤った文書が上位に来ていないかを確認する必要があります。
初心者の学習では、まず小さなデータセットで両者の違いを体験すると理解が進みます。数十件の文書で転置インデックスを作り、検索語から文書IDを引く流れを確認します。次に、同じ文書をEmbeddingでベクトル化し、類似文書検索を試します。検索結果の違いを見比べると、言葉の一致と意味の近さの違いが具体的に分かります。
関連用語との違い
転置インデックスとIVFを理解するうえで、関連用語も整理しておきましょう。まずBM25は、転置インデックスそのものではなく、全文検索の順位付けによく使われるスコアリング手法です。転置インデックスで候補を取り出し、BM25で関連度を計算する、という組み合わせで考えると分かりやすいです。
Embeddingは、文章や画像などを数値ベクトルに変換する技術です。IVFはEmbeddingで作られたベクトルを検索しやすくするためのインデックスです。つまり、Embeddingがベクトル表現を作り、IVFが大量のベクトルから候補を探す手助けをします。
ANNは Approximate Nearest Neighbor、近似最近傍探索のことです。大量のベクトルから近いものを高速に探すための考え方全般を指します。IVFはANNを実現する代表的な方式の1つです。他にもHNSWなどの方式があります。
HNSWは、ベクトル同士の近さをグラフ構造で表し、高速に近傍を探す方式です。IVFがクラスタで空間を大まかに分ける考え方なのに対し、HNSWは近い点同士を結んだ多層グラフをたどるイメージです。どちらが常に優れているというより、データ量、更新頻度、メモリ、検索速度、精度要件によって選びます。
ベクトルデータベースは、Embeddingベクトルを保存し、検索するためのデータベースです。内部でIVF、HNSW、量子化などのインデックス方式を使うことがあります。ユーザーはベクトルデータベースを使うとき、どのインデックス方式が使われているか、どのパラメータが検索品質に影響するかを理解しておくと、運用時の調整がしやすくなります。
RAGは、検索で取り出した情報を生成AIの回答に使う仕組みです。転置インデックスやIVFは、RAGの検索部分を支える候補取得の技術です。RAGそのものは、検索、根拠文書の選択、プロンプトへの組み込み、回答生成、引用表示などを含む大きな設計です。
どちらを学べばよいか
AI検索を学ぶなら、転置インデックスとIVFのどちらか一方ではなく、両方の基本を押さえるのがおすすめです。理由は、実務の検索システムでは、キーワード一致と意味検索の両方が必要になることが多いからです。
学習の順番としては、まず転置インデックスを理解するとよいでしょう。単語、文書ID、posting list、スコアリングという考え方は、検索の基礎として非常に重要です。なぜ検索が速くなるのか、なぜ語の分割が重要なのか、なぜランキングが必要なのかを理解できます。
次に、Embeddingとベクトル検索を学びます。文章が数値ベクトルになること、距離や類似度で近さを測ること、全件比較が重くなることを理解します。そのうえで、IVFやHNSWのようなANNインデックスを学ぶと、「なぜ近似が必要なのか」「なぜパラメータ調整が必要なのか」が見えてきます。
実装を試す場合は、小さな文書集合で十分です。10件から100件程度の文書で、キーワード検索とベクトル検索を両方試し、同じクエリで結果がどう変わるかを見ます。たとえば「退職手続き」「会社を辞めるときの流れ」「離職時の必要書類」のような表現で検索し、全文検索とベクトル検索の結果を比較すると、違いが分かりやすくなります。
また、業務で使う場合は、検索対象の性質を先に確認しましょう。ログやマスタデータが中心なら、まず全文検索や構造化フィルタが重要です。FAQやナレッジベースの自然文検索が中心なら、ベクトル検索が効果を発揮しやすいです。契約書や規程のように厳密な語句と意味理解の両方が必要な場合は、ハイブリッド検索を検討します。
まとめ
全文検索とベクトル検索では、同じ「検索インデックス」でも役割が異なります。転置インデックスは、単語から文書を引くための索引です。全文検索やキーワード検索で使われ、語句一致、固有名詞、型番、専門用語の検索に強みがあります。
IVFは、ベクトル検索で大量のベクトルから近い候補を探すための索引です。ベクトル空間をクラスタに分け、クエリに近そうなクラスタだけを調べることで、全件比較を避けます。意味検索、類似文書検索、RAGの候補取得などで使われます。
両者の違いを一言で言えば、転置インデックスは「言葉から文書を探す」、IVFは「ベクトル空間から近い候補を探す」ということです。この違いを押さえると、全文検索、ベクトル検索、ハイブリッド検索、RAGの設計を整理しやすくなります。
生成AI時代の検索では、ベクトル検索だけで全てを解決しようとするのではなく、キーワード検索の確実さとベクトル検索の柔軟さを組み合わせる視点が重要です。検索したい情報が文字列として明確なのか、意味的に近い情報を探したいのかを見極め、必要に応じて転置インデックスとIVFを使い分けましょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月16日 | 初回公開 |
| 2026年5月16日 | タイトルと冒頭表現を、記事内容に合わせて更新 |