
深層学習とデータ量の関係とは?必要なデータ量と質を初心者向けに解説

AIの初心者
「バーニーおじさんのルール」では、ディープラーニングの学習にパラメータ数の10倍以上のデータが必要だと聞きました。実際には、どれくらい大量のデータが必要なのでしょうか?

AI専門家
目安として考えると分かりやすいです。例えば、パラメータが100万個ある画像認識モデルなら、単純計算では1000万件ほどの学習データが必要になる、という考え方です。
AIの初心者
1000万件となると、かなり大きな規模ですね。データを集めるだけでも大変そうです。
AI専門家
その通りです。だからこそ、インターネットの普及で画像、文章、音声、動画などのデータを大量に扱えるようになったことが、深層学習の発展を大きく後押ししました。ただし、量だけでなくデータの質も重要です。
ディープラーニングのデータ量とは。
深層学習は、AIが大量のデータから特徴や規則性を学び、画像認識、自然言語処理、音声認識などに活用される学習方法です。モデルが複雑になるほど調整すべきパラメータが増えるため、一般に多くの学習データが必要になります。「バーニーおじさんのルール」と呼ばれる経験則では、理想的な学習にはパラメータ数の10倍以上のデータ量が必要だと説明されることがあります。ただし、これは厳密な法則ではなく、課題の難しさ、データの質、モデルの作り方によって必要量は変わります。
深層学習とデータ量の関係とは

深層学習では、モデルに多くのデータを見せることで、入力と出力の間にあるパターンを学習します。画像分類であれば、花びらの形、色、背景、角度などの特徴を多数の画像から学び、未知の画像に対しても分類できるようにします。文章を扱う場合は、単語の並び、文脈、意味の近さなどを大量のテキストから学びます。
ここで重要なのは、深層学習が単にデータを丸暗記しているわけではないという点です。十分な量と多様性のあるデータがあると、モデルは個別の例だけでなく、別の場面にも使える一般的な特徴を見つけやすくなります。反対に、学習データが少なすぎると、たまたま含まれていた特徴に強く引っ張られ、実際の利用場面でうまく判断できないことがあります。
そのため、深層学習におけるデータ量は、モデルの性能を支える土台です。特に、画像、音声、自然言語のように入力の種類が多く、ばらつきも大きい分野では、十分なデータ量がモデルの汎化性能を高めるために欠かせません。
なぜ深層学習には大量のデータが必要なのか
深層学習モデルは、たくさんの層とパラメータを持ちます。パラメータとは、学習によって調整される数値のことで、モデルがどの特徴をどれくらい重視するかを決める役割を持ちます。パラメータ数が多いモデルは複雑な関係を表現できますが、その分だけ適切に調整するための材料も多く必要になります。
例えば、植物を分類するAIを考えてみます。数十枚の写真だけで学習したモデルは、特定の明るさ、背景、撮影角度の植物には反応できても、別の季節や環境で撮影された植物には弱いかもしれません。一方で、種類、角度、成長段階、背景、照明条件が異なる写真を大量に学習すれば、より多くの状況に対応しやすくなります。
つまり、大量データが必要なのは、モデルが「学習データに含まれる一部の癖」ではなく、「本当に判断に使える特徴」を見つけるためです。深層学習では、モデルの表現力が高いほど、データの不足や偏りの影響も受けやすくなります。
パラメータ数とデータ量の目安
元記事で紹介されている「バーニーおじさんのルール」は、深層学習モデルのパラメータ数に対して、少なくとも10倍程度の学習データが必要だとする経験則です。例えば、100万個のパラメータを持つモデルであれば、1000万件程度のデータが理想的だと考える、という目安になります。
ただし、この目安はそのまま全てのAI開発に当てはまるものではありません。必要なデータ量は、データ1件がどれだけ情報を持つか、ラベルが正確か、解きたい課題が単純か複雑か、モデルが事前学習済みかどうかによって変わります。例えば、既に大規模データで学習済みのモデルを使って一部だけ調整する場合は、ゼロから学習する場合より少ないデータで済むことがあります。
初心者は、10倍という数字を絶対条件として覚えるよりも、モデルが複雑になるほど多様で十分な学習データが必要になるという考え方を理解することが大切です。実務では、最初に使えるデータでモデルを作り、検証データで性能を測りながら、データ追加、前処理、モデル変更を進めます。
| 項目 | 考え方 |
|---|---|
| パラメータ数 | 学習で調整される数値の数。多いほど複雑な関係を表現しやすい |
| データ量 | モデルが特徴を学ぶための材料。少ないと偏った学習になりやすい |
| 10倍ルール | パラメータ数の10倍以上のデータを目安とする経験則 |
| 注意点 | データ品質、課題の難しさ、事前学習の有無で必要量は変わる |
データ不足で起こる過学習
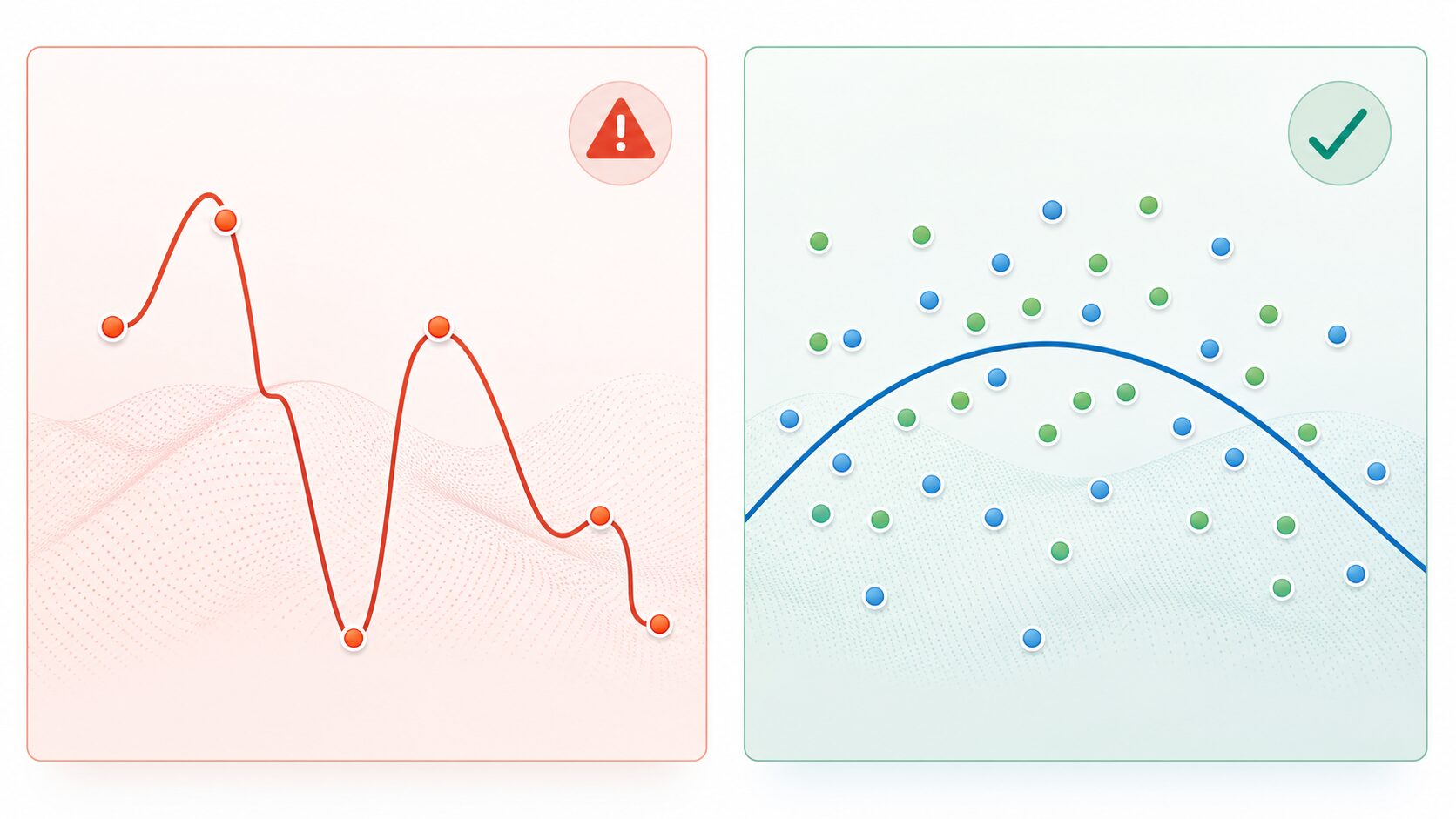
データ量が不足すると起こりやすい代表的な問題が過学習です。過学習とは、モデルが学習データにはよく合うものの、初めて見るデータでは性能が下がってしまう状態を指します。試験勉強で過去問だけを丸暗記し、少し形の違う問題に対応できない状態に近いと考えると分かりやすいでしょう。
例えば、特定の背景で撮影された犬の画像だけを学習したモデルは、「犬そのもの」ではなく「背景の色」や「撮影場所の特徴」を犬の手がかりとして覚えてしまうかもしれません。その場合、別の場所で撮影された犬の画像をうまく判定できなくなります。
過学習を防ぐには、データ数を増やすだけでなく、学習データと評価データを分けて性能を確認することが重要です。また、データ拡張、正則化、早期終了、モデルの単純化などの方法も使われます。深層学習では、学習データへの正解率だけでなく、未知のデータに対して安定して正しく予測できるかを見る必要があります。
ビッグデータが深層学習を発展させた理由

深層学習が大きく発展した背景には、インターネットの普及とビッグデータの登場があります。文章、画像、音声、動画、購買履歴、センサーデータなど、さまざまな形式のデータを大量に集め、保存し、処理できるようになったことで、複雑なモデルを実用的に学習できる環境が整いました。
画像認識では、大量の画像とラベルを使って、物体、人物、風景、異常箇所などを識別するモデルが発展しました。自然言語処理では、大規模な文章データを使って、文章生成、翻訳、要約、検索支援などが進歩しました。音声認識でも、多様な話者、発音、環境音を含む音声データが性能向上に役立っています。
ビッグデータは、深層学習にとって単なる量の増加ではありません。多様な状況を含むデータが増えることで、モデルは現実世界のばらつきを学びやすくなります。これにより、医療、農業、製造業、教育、金融など、多くの分野でAIの応用が広がりました。
データ量だけでなくデータの質も重要

深層学習では大量のデータが役立ちますが、データが多ければ必ず高精度になるわけではありません。誤ったラベル、重複、ノイズ、偏りを多く含むデータで学習すると、モデルは間違った判断基準を身につける可能性があります。
例えば、商品の評価を予測するAIを作るとき、購入済みの人のレビューだけを学習データにすると、購入しなかった人の不満や迷いを反映できません。このような偏りがあると、モデルは現実の利用者全体を正しく捉えられなくなります。医療や採用、金融のような分野では、偏ったデータが不公平な判断につながるリスクもあります。
質の高いデータとは、誤りが少なく、対象となる状況を幅広く含み、ラベルや形式が整理されているデータです。実務では、収集したデータをそのまま使うのではなく、欠損値の確認、重複削除、ラベル修正、偏りの確認、前処理を行います。データ量とデータ品質はどちらか一方ではなく、深層学習を支える両輪です。
少ないデータで学習するときの工夫
現実のプロジェクトでは、常に大量のデータを用意できるとは限りません。専門領域のデータ、医療画像、製造現場の異常データ、希少な事例などは、集められる件数が限られることがあります。その場合は、少ないデータを効率よく使う工夫が必要です。
代表的な方法の一つがデータ拡張です。画像であれば、回転、反転、明るさの調整、切り抜きなどを使って、学習データのバリエーションを増やします。文章では表現の言い換え、音声では速度や雑音の変化を加える場合があります。ただし、現実には起こらない変化を加えると、かえって性能を下げることがあるため注意が必要です。
もう一つ重要なのが、事前学習済みモデルや転移学習の活用です。すでに大規模データで学習されたモデルを土台にして、手元のデータで目的に合わせて調整すれば、ゼロから学習するより少ないデータで高い性能を得られることがあります。今後は、少量データから効率よく学ぶ方法や、偏り・ノイズに強いモデルの重要性がさらに高まるでしょう。
まとめ
深層学習とデータ量には深い関係があります。モデルのパラメータ数が増え、表現できることが多くなるほど、適切に学習するためには多くのデータが必要になります。元記事で紹介されている10倍ルールは、この関係を理解するための分かりやすい目安です。
ただし、必要なデータ量は課題やデータの質によって変わります。データが少ないと過学習が起こりやすく、データが多くても誤りや偏りが多ければ性能は上がりません。深層学習を正しく活用するには、十分な量のデータを集めることに加えて、データの品質を確認し、評価データで未知の状況に対する性能を確かめることが大切です。
ビッグデータの登場によって深層学習は大きく発展しましたが、これからは「どれだけ集めるか」だけでなく「どのように整え、どのように使うか」がさらに重要になります。データ量、データ品質、モデル設計をバランスよく考えることが、AI開発の第一歩です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月2日 | 初回公開 |
| 2026年5月4日 | 深層学習に必要なデータ量、パラメータ数との関係、過学習、ビッグデータ、データ品質、少量データ学習の工夫を初心者向けに再構成 |