
マイクロF1値とは?計算方法とマクロF1との違いをわかりやすく解説

AIの初心者
「マイクロF1値」って何を表す指標ですか?F1値という名前は聞いたことがありますが、正解率とは違うのでしょうか。

AI専門家
マイクロF1値は、分類モデルの予測結果を全体で集計して評価する指標です。適合率と再現率のバランスを見るため、単純な正解率だけでは分かりにくい性能を確認できます。
AIの初心者
全体で集計するということは、クラスごとに別々に見る指標とは考え方が違うのですね。
AI専門家
その通りです。マイクロF1値は全体の判定数を重視します。一方で、少数クラスの性能が見えにくくなる場合もあるため、マクロF1値などと一緒に確認することが大切です。
micro-F1とは。
マイクロF1値は、機械学習の分類モデルを評価するときに使う指標です。真陽性、偽陽性、偽陰性を全体で集計し、適合率と再現率のバランスを0から1の数値で表します。
マイクロF1値とは

マイクロF1値とは、分類モデルの予測結果を評価するためのF1値の一種です。特に、複数のクラスを分類するタスクで、全クラスの予測結果をまとめて集計し、全体としてどれくらい正しく分類できたかを見るときに使われます。
分類モデルとは、入力されたデータをあらかじめ決められた種類に振り分けるモデルです。たとえば、メールを「迷惑メール」と「通常メール」に分ける、画像を「犬」「猫」「鳥」に分ける、レビュー文を「良い」「普通」「悪い」に分ける、といった処理が分類にあたります。
マイクロF1値は0から1の範囲で表され、1に近いほど性能が高いと判断されます。ただし、単に「正解した割合」だけを見る指標ではありません。モデルが陽性と予測したものがどれだけ正しかったかを表す適合率と、実際の陽性をどれだけ見つけられたかを表す再現率を組み合わせて評価します。
ここでいう「マイクロ」は、少数クラスだけを見るという意味ではありません。個々の予測結果を細かく数え、真陽性、偽陽性、偽陰性を全体で合算してから計算する、という意味合いで理解すると混乱しにくくなります。
マイクロF1値の計算方法
マイクロF1値を計算するには、まず分類結果から真陽性、偽陽性、偽陰性を数えます。真陽性は、実際に陽性でモデルも陽性と正しく予測した数です。偽陽性は、本当は陽性ではないのに陽性と予測した数です。偽陰性は、本当は陽性なのに見逃して陰性と予測した数です。
多クラス分類では、各クラスを順番に「注目している陽性クラス」として扱い、それぞれの判定で発生した真陽性、偽陽性、偽陰性を集計します。マイクロF1値では、クラスごとにF1値を出してから平均するのではなく、全クラス分の真陽性、偽陽性、偽陰性を先に合計する点が重要です。
計算式は次のように表せます。
\(\text{Micro Precision}=\frac{\sum TP}{\sum TP+\sum FP}\) \(\text{Micro Recall}=\frac{\sum TP}{\sum TP+\sum FN}\) \(\text{Micro F1}=\frac{2\times \text{Micro Precision}\times \text{Micro Recall}}{\text{Micro Precision}+\text{Micro Recall}}\)\(TP\)は真陽性、\(FP\)は偽陽性、\(FN\)は偽陰性を表します。適合率と再現率のどちらか一方だけが高くても、F1値は大きく伸びません。F1値は調和平均を使うため、両方のバランスが取れているかを確認しやすい指標です。
たとえば、迷惑メール検知で、迷惑メールを正しく迷惑メールと判定した数が多くても、通常メールを大量に迷惑メール扱いしてしまうなら偽陽性が増えます。逆に、通常メールを守ることを優先しすぎて迷惑メールを見逃せば偽陰性が増えます。マイクロF1値は、このような誤検知と見逃しをまとめて評価するために使えます。
マイクロF1値とマクロF1値の違い
マイクロF1値とよく比較されるのがマクロF1値です。どちらも分類モデルの性能を見る指標ですが、集計の順番が違います。
マイクロF1値は、全クラスの真陽性、偽陽性、偽陰性をまとめてから適合率、再現率、F1値を計算します。そのため、データ数が多いクラスの影響を受けやすく、全体としての分類性能をつかみやすい指標です。
一方、マクロF1値はクラスごとにF1値を計算し、それらを同じ重みで平均します。データ数が多いクラスも少ないクラスも同じように扱うため、少数クラスの分類性能を確認しやすくなります。
| 指標 | 計算の考え方 | 特徴 | 向いている場面 |
|---|---|---|---|
| マイクロF1値 | 全クラスのTP、FP、FNを合算してから計算 | データ数が多いクラスの影響を受けやすい | 全体の予測性能を重視したい場合 |
| マクロF1値 | クラスごとにF1値を計算して平均 | 少数クラスの性能も同じ重みで反映しやすい | 各クラスを均等に重視したい場合 |
たとえば、犬の画像が900枚、猫の画像が90枚、鳥の画像が10枚あるデータセットを考えます。犬の分類が非常に正確なら、猫や鳥の分類が弱くてもマイクロF1値は高く見えることがあります。しかし、鳥の判定が業務上重要であれば、そのモデルを良いモデルとは言い切れません。この場合は、マクロF1値やクラス別F1値も確認する必要があります。
マイクロF1値が向いている場面

マイクロF1値は、分類タスク全体の予測結果をまとめて評価したい場面に向いています。大量のデータを扱い、全体としてどれくらい安定して分類できているかを比較したいときに役立ちます。
代表的な例は迷惑メール分類です。迷惑メールを正しく検出することも大切ですが、通常メールを誤って迷惑メールに入れてしまうことも避けなければなりません。マイクロF1値を見ることで、見逃しと誤検知のバランスを含めて、フィルター全体の性能を評価できます。
医療診断支援でも、画像から病変の有無を分類するようなタスクでF1値が使われます。ただし医療では、見逃しのコストが非常に大きい場合があります。そのため、マイクロF1値だけでなく、再現率、クラス別の感度、専門家による評価なども合わせて見る必要があります。
自然言語処理では、レビューの感情分類、ニュース記事のカテゴリ分類、問い合わせ文の自動振り分けなどに使われます。分類対象が多く、全体の処理品質を比較したいとき、マイクロF1値はモデル改善の目安になります。
マイクロF1値を見るときの注意点
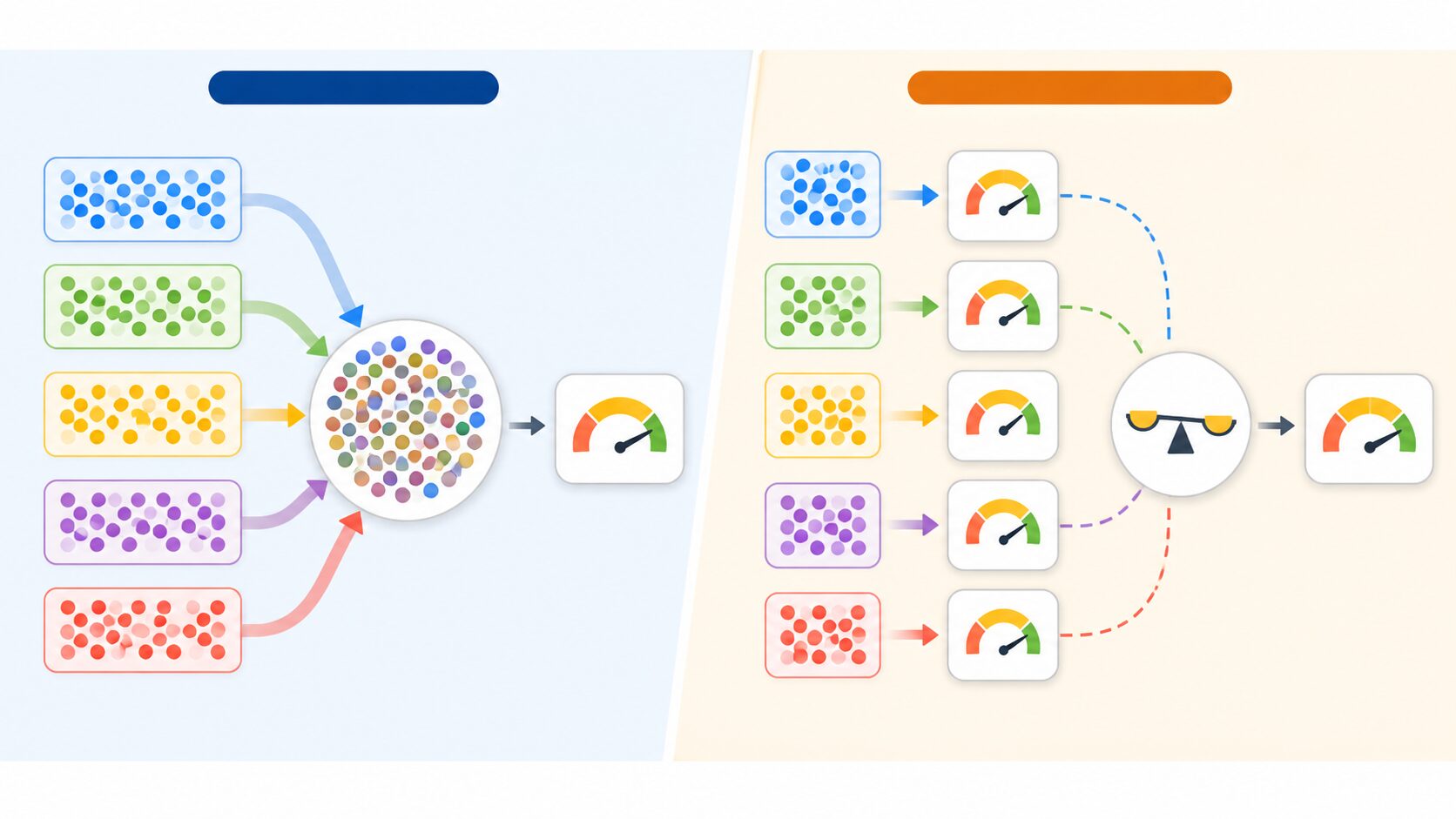
マイクロF1値は便利な指標ですが、万能ではありません。特に注意したいのは、データの偏りが大きい場合です。多数派クラスのデータが圧倒的に多いと、少数クラスをうまく分類できていなくても、全体の評価値は高く見えることがあります。
たとえば、通常メールが99%、迷惑メールが1%しかないデータで、通常メールの分類だけが得意なモデルを作ったとします。このモデルは全体では良い値を出すかもしれませんが、迷惑メールを見逃すなら実用上は問題があります。検索、医療、金融、不正検知のように少数ケースが重要な分野では、マイクロF1値だけで判断するのは危険です。
また、単一ラベルの多クラス分類では、マイクロF1値が正解率に近い意味を持つことがあります。そのため、正解率、マクロF1値、加重平均F1値、混同行列などを組み合わせて、どのクラスで失敗しているのかを確認することが重要です。
評価指標は、モデル選定のための道具です。数値が高いか低いかだけでなく、どの誤りが業務上どれほど問題になるのかまで考えると、マイクロF1値をより実践的に使えます。
まとめ
マイクロF1値は、分類モデルの真陽性、偽陽性、偽陰性を全体で集計し、適合率と再現率のバランスを評価する指標です。0から1で表され、1に近いほど全体として良い分類ができていると判断できます。
マクロF1値との大きな違いは、集計の順番です。マイクロF1値は全体の件数をまとめてから計算するため、データ数が多いクラスの影響を受けやすくなります。マクロF1値はクラスごとにF1値を計算して平均するため、少数クラスの状態を確認しやすい指標です。
迷惑メール分類、医療診断、文章分類など、マイクロF1値は多くの分類タスクで使われます。ただし、データの偏りがある場合や少数クラスが重要な場合は、マイクロF1値だけでなく、マクロF1値やクラス別の評価も合わせて確認しましょう。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年6月5日 | 式の読み方とマクロF1との差を補い、用途別の判断材料を追記 |