汎化誤差とは?訓練誤差との違いと機械学習で重要な理由

AIの初心者
「汎化誤差」って、機械学習の説明でよく出てきますが、何を表している言葉なんですか?

AI専門家
汎化誤差は、学習済みのAIがまだ見たことのないデータに対して、どれくらい予測を間違えるかを表す指標です。たとえば猫画像で学習したAIが、初めて見る猫の写真を正しく判定できるかを見る考え方です。
AIの初心者
学習に使ったデータでの間違いとは別に考える必要があるんですね。
AI専門家
その通りです。学習データへの誤差は訓練誤差と呼びます。訓練誤差が小さくても、未知データへの汎化誤差が大きければ、実際の予測では役に立ちにくくなります。この状態は過学習と深く関係します。
汎化誤差とは。
汎化誤差とは、機械学習モデルが学習に使っていないデータに対してどの程度間違えるかを示す尺度です。訓練データに対する成績だけでは、未知の入力に対応できるかは判断できません。モデルを現実の予測や分類に使うには、訓練誤差だけでなく汎化誤差を意識して評価する必要があります。
汎化誤差とは
汎化誤差は、学習済みモデルが未知のデータに対してどれくらい予測を外すかを表す指標です。機械学習では、手元にあるデータを使ってモデルを学習させます。しかし、モデルの目的は学習データを暗記することではなく、これから入力される新しいデータにも対応することです。
たとえば、猫の画像を大量に使って画像分類モデルを作るとします。学習に使った猫画像を正しく分類できても、別の日に撮られた猫、背景が違う猫、角度が違う猫を正しく分類できなければ実用的とはいえません。この未知データに対する誤りが大きいほど、汎化誤差は大きいと考えます。
初心者向けに言えば、訓練データは練習問題、未知データは本番試験に近いものです。練習問題の答えを覚えるだけでは、本番で少し形を変えた問題に対応できません。機械学習でも同じように、モデルが本質的なパターンを学んでいるかを確認する視点が汎化誤差です。
| 用語 | 意味 | 見る対象 |
|---|---|---|
| 汎化誤差 | 未知データに対する予測の誤り | 学習に使っていないデータ |
| 汎化性能 | 未知データにどれだけ対応できるか | 実運用に近いデータ |
| 訓練データ | モデルの学習に使うデータ | 既知の入力と正解 |
| 過学習 | 訓練データに合わせすぎて未知データに弱くなる状態 | 訓練データと検証データの差 |
汎化誤差はどのように考えるか
理想的には、現実世界で今後発生するすべてのデータに対して平均的な誤差を測れれば、モデルの真の汎化誤差を把握できます。ただし、未来のデータや全体の分布を完全に観測することはできません。そのため実務では、手元のデータを訓練用、検証用、テスト用に分け、未知データに近い条件で誤差を推定します。
考え方を式で表すと、モデル \(f\) が入力 \(x\) から予測し、正解 \(y\) との損失を \(L(f(x), y)\) としたとき、汎化誤差はデータ分布 \(P\) に対する平均的な損失として捉えられます。
\(G = E_{(x,y)\sim P}[L(f(x), y)]\)この式そのものを暗記する必要はありません。重要なのは、汎化誤差が「手元の訓練データだけの点数」ではなく、「モデルが本来出会うデータ全体でどれくらい外すか」を表す概念だという点です。実際には、独立したテストデータでの誤差をその近似として使います。
訓練誤差との違い
訓練誤差は学習に使ったデータでの誤差、汎化誤差は学習に使っていないデータでの誤差です。この違いを分けて考えないと、モデルの性能を高く見積もってしまいます。
訓練誤差は、モデルが学習データにどれだけうまく当てはまっているかを示します。学習が進むほど訓練誤差は小さくなる傾向がありますが、それだけで良いモデルとは判断できません。学習データには偶然の偏り、ノイズ、重複、特定の条件が含まれるため、それらに強く合わせすぎると未知データへの対応力が落ちるからです。
一方で、汎化誤差は実運用に近い評価です。天気予測なら過去データへの当てはまりではなく、明日以降の天気をどれだけ予測できるかが重要です。診断支援なら、訓練に使った患者データではなく、新しい患者データで誤診を減らせるかが重要になります。
| 指標 | 評価するもの | 小さいときの意味 | 注意点 |
|---|---|---|---|
| 訓練誤差 | 学習データへの予測誤差 | 学習データによく合っている | 小さすぎても過学習の可能性がある |
| 検証誤差 | モデル調整用データへの予測誤差 | 候補モデルの比較に使える | 何度も見すぎると調整に使い込んでしまう |
| テスト誤差 | 最終確認用データへの予測誤差 | 未知データでの性能を近似できる | モデル選択後に一度だけ確認するのが望ましい |
過学習と汎化誤差の関係
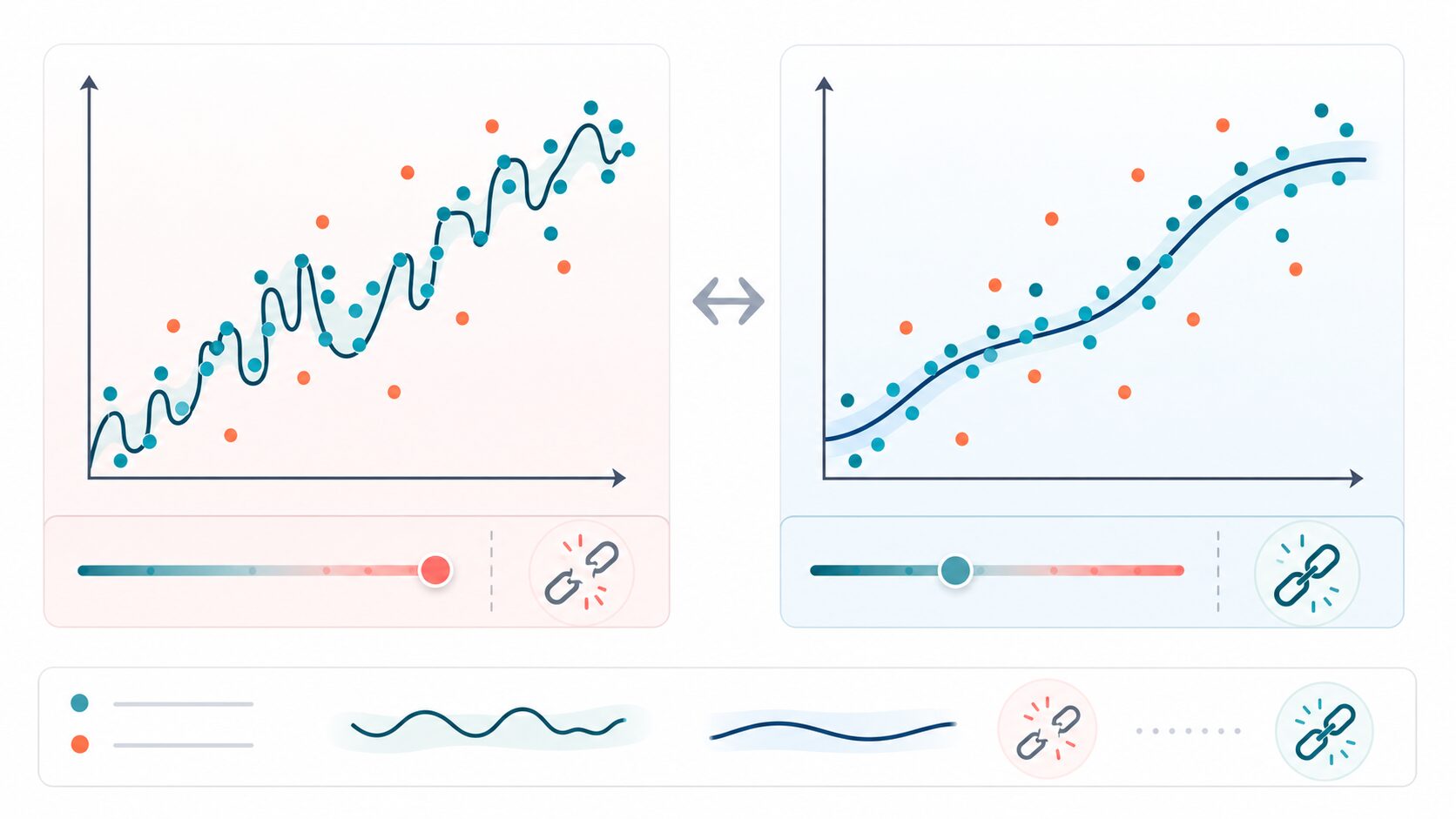
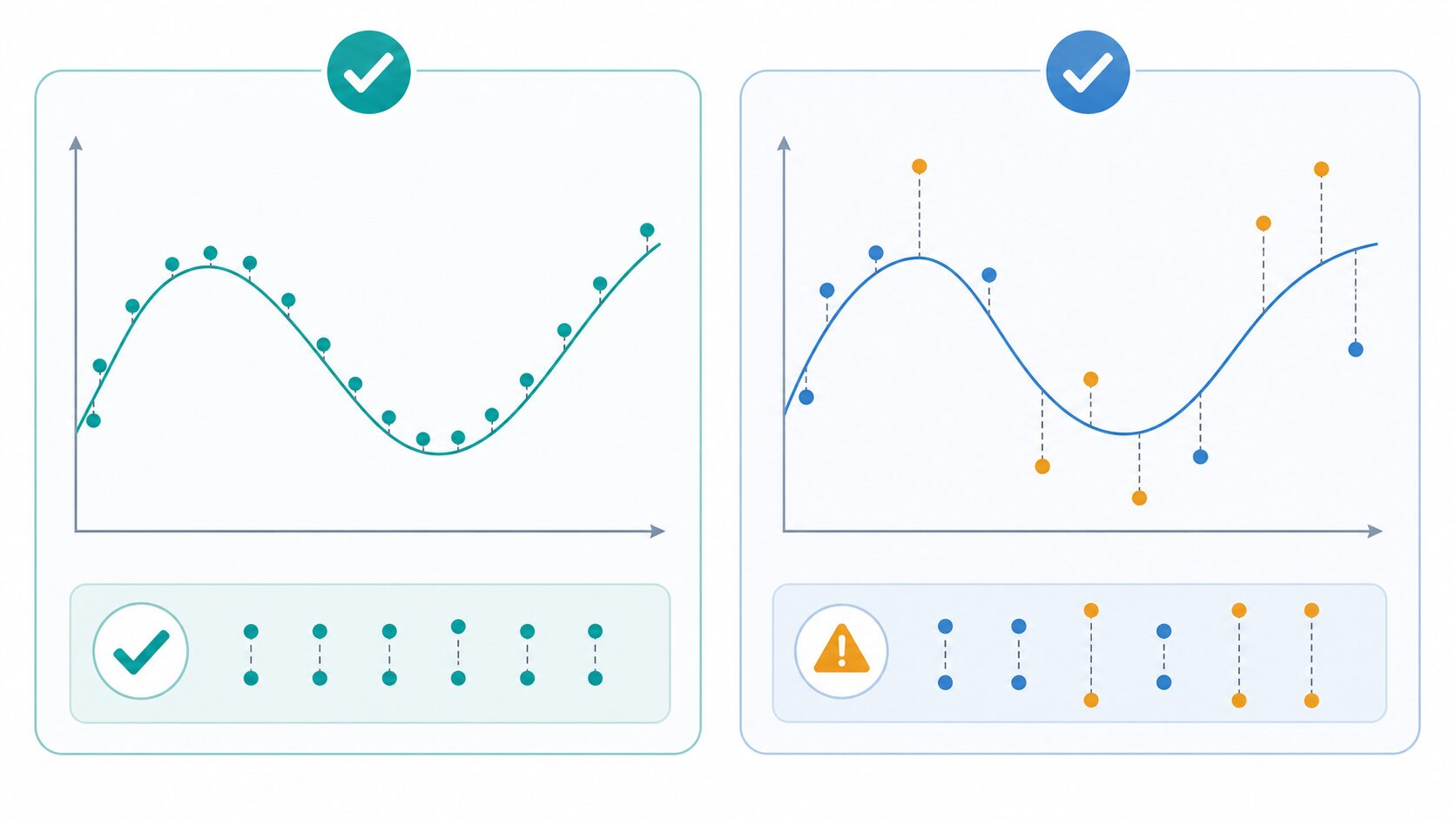
過学習とは、モデルが訓練データに過度に適応し、未知データにうまく対応できなくなる状態です。訓練誤差はとても小さいのに、検証データやテストデータで誤差が大きい場合、過学習が疑われます。
たとえば、散布図の点をすべて通るように複雑な曲線を引くと、訓練データ上では正確に見えるかもしれません。しかし、その曲線がノイズまで拾っていれば、新しい点を予測したときに大きく外れます。これは、練習問題の解答手順を丸暗記して、本番の応用問題に対応できない状態に似ています。
反対に、モデルが単純すぎる場合は学習不足が起こります。この場合は訓練誤差も汎化誤差も大きくなりがちです。つまり、良いモデルを作るには、複雑すぎても単純すぎてもいけません。データの構造を十分に捉えつつ、細かなノイズには引きずられないバランスが必要です。
汎化誤差を小さくする主な方法
汎化誤差を小さくするには、単に学習回数を増やすだけでは不十分です。データ、モデル、評価方法を組み合わせて見直す必要があります。
まず重要なのは、学習データの量と質です。データが少ないと、モデルは限られた例から無理にパターンを見つけようとします。画像認識では、回転、明るさの変更、切り出しなどでデータ拡張を行い、さまざまな見え方に対応しやすくすることがあります。ただし、現実には起こらない変換を加えると逆効果になるため、対象領域に合った拡張が必要です。
次に、モデルの複雑さを調整します。パラメータが多すぎるモデルは高い表現力を持つ一方で、訓練データの細部まで覚えやすくなります。正則化は、モデルが過度に複雑な解を選ぶことを抑える代表的な方法です。決定木なら木の深さを制限する、ニューラルネットワークならドロップアウトや重み減衰を使う、といった対策があります。
交差検証もよく使われます。データを複数のグループに分け、あるグループを検証用、残りを学習用として評価を繰り返す方法です。限られたデータでモデルの安定性を確認しやすく、ハイパーパラメータの比較にも役立ちます。ただし、最終的な性能確認に使うテストデータまで何度も見て調整すると、評価結果が楽観的になるため注意が必要です。
| 方法 | 狙い | 例 |
|---|---|---|
| データを増やす | 多様な条件を学習させる | 追加収集、データ拡張 |
| 正則化する | 複雑すぎるモデルを抑える | 重み減衰、ドロップアウト |
| 交差検証する | 限られたデータで安定性を確認する | k分割交差検証 |
| 特徴量を見直す | ノイズや漏洩を減らす | 不要な列の除外、前処理の改善 |
実務で汎化誤差を見るときの注意点
汎化誤差を評価するときは、データ分割の仕方がとても重要です。たとえば同じユーザー、同じ患者、同じ製品ロットのデータが訓練側とテスト側に混ざっていると、モデルは本当に未知のケースに対応したのではなく、似た情報を見ているだけかもしれません。このようなデータ漏洩があると、汎化誤差を実際より小さく見積もってしまいます。
時系列データでは、未来の情報を使って過去を予測するような分割を避ける必要があります。売上予測や天気予測では、過去データで学習し、未来に近い期間で評価するほうが実運用に近くなります。ランダム分割がいつも正しいとは限りません。
また、評価指標も目的に合わせて選びます。分類問題なら正解率だけでなく、適合率、再現率、F値、AUCなどを確認する場合があります。回帰問題なら平均絶対誤差や二乗平均平方根誤差などを使います。汎化誤差の考え方は共通していますが、何を「誤差」と見なすかは問題設定によって変わります。
汎化誤差が重要な理由
機械学習モデルは、現実世界の意思決定や自動化に使われます。そのため、訓練データで良い点数を出すだけでは不十分です。実際に入力されるデータは、収集時期、環境、ユーザー、機器、地域などによって少しずつ変わります。汎化誤差が大きいモデルは、この変化に弱くなります。
診断支援システムなら、訓練データに含まれない撮影条件や患者属性でも安定して判断できる必要があります。製造検査なら、新しいロットや照明条件でも不良品を見逃さないことが重要です。推薦システムなら、過去の一部ユーザーだけに過度に合わせるのではなく、新しいユーザーや季節変化にも対応する必要があります。
汎化誤差を意識することは、モデルを研究用の成績表から実務で使える道具へ近づけるための基本です。訓練誤差、検証誤差、テスト誤差を分けて観察し、過学習やデータ漏洩を避けながら改善を続けることで、信頼しやすい機械学習モデルに近づきます。
まとめ
汎化誤差とは、機械学習モデルが学習に使っていない未知データに対してどれくらい間違えるかを表す指標です。訓練誤差が小さいことは重要ですが、それだけでは実用的なモデルとはいえません。未知データへの対応力である汎化性能を確認する必要があります。
汎化誤差が大きくなる代表的な原因は過学習です。モデルが訓練データの細部やノイズまで覚えると、検証データやテストデータで性能が落ちます。対策としては、データ量と品質の改善、正則化、モデルの複雑さの調整、交差検証、データ拡張、適切な評価設計が有効です。
機械学習を学ぶときは、まず「訓練データでの成績」と「未知データでの成績」を分けて考えることが大切です。この区別ができると、過学習、検証データ、テストデータ、モデル選択といった関連概念も理解しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年6月7日 | 評価方法と過学習対策を補い、実務で見る観点を追記 |