半教師あり学習:データの活用を進化させる

AIの初心者
先生、「半教師あり学習」って、どういう意味ですか?ラベル付きデータとラベルなしデータって、よくわからないです。

AI専門家
そうだね、少し難しいよね。たとえば、猫の画像をAIに学習させるとしよう。ラベル付きデータとは、「これは猫です」と説明書きがついた画像のこと。ラベルなしデータは、ただ猫の画像があるだけで、説明がないものだよ。
AIの初心者
なるほど。じゃあ「半教師あり学習」は、少しの説明付きの画像と、たくさんの説明なしの画像を使って学習する方法ってことですか?
AI専門家
その通り!少ない説明付き画像からAIが特徴を学び、それをたくさんの説明なし画像で確認しながら、より効率的に学習していくんだ。ラベル付きデータを作るのは大変だから、この方法は便利なんだよ。
半教師あり学習とは。
少量の答え付きのデータを使って、大量の答えなしのデータを効率よく学習する方法である『半教師あり学習』について説明します。
はじめに

機械学習という技術は、膨大な量の資料から規則性や繋がりを自ら学び、未来の出来事を予測したり、物事を分類したりする作業を行います。この技術をうまく活用するためには、資料の一つ一つに正しい答えとなる札を付ける作業が欠かせません。しかし、この札付け作業は大変な手間と時間がかかり、多くの資料を扱う場合には大きな壁となります。
例えば、画像認識の分野を考えてみましょう。猫の画像を機械に学習させるためには、多くの画像に「猫」という札を付ける必要があります。一枚一枚手作業で行うのは大変な作業です。数枚や数十枚ならまだしも、数千枚、数万枚となると気の遠くなるような作業量です。
そこで登場するのが、「半教師あり学習」と呼ばれる方法です。この方法は、札の付いた少量の資料と、札のない大量の資料を組み合わせて学習を行います。札付きの資料から得た知識を足掛かりに、札のない大量の資料からも隠れた規則性や繋がりを学び取ろうとするのです。
半教師あり学習は、札付き資料の不足を解消し、学習の効果を高める上で非常に役立ちます。前述の猫の画像の例で言えば、札付きの猫の画像が少なくても、札のない大量の猫の画像と組み合わせることで、猫の特徴をより深く学習できます。結果として、少ない労力でより精度の高い猫の画像認識が可能になるのです。
この手法は、画像認識だけでなく、音声認識や自然言語処理など、様々な分野で応用されています。限られた資源を有効活用し、より効率的に機械学習を進める上で、半教師あり学習は今後ますます重要な役割を担っていくと考えられます。
半教師あり学習とは

半教師あり学習とは、機械学習の一つの手法であり、ラベル付きデータとラベルなしデータを共に活用することで、学習モデルの性能を高めることを目指します。
教師あり学習では、すべての学習データにラベル(正解)が付与されている必要があります。しかし、現実世界ではラベル付け作業には多大なコストがかかることが多く、十分な量のラベル付きデータを集めるのが難しい場合も少なくありません。そこで、ラベル付きデータに加えて、ラベルのない大量のデータを活用しようとするのが半教師あり学習です。
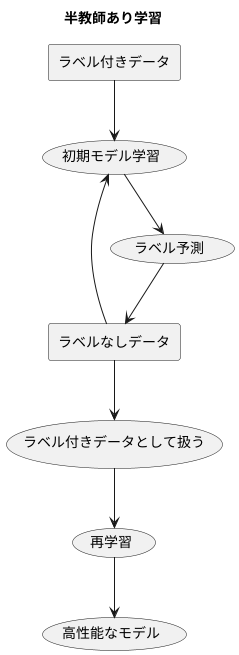
半教師あり学習の基本的な考え方は、少量のラベル付きデータから学習した初期モデルを用いて、ラベルなしデータにラベルを予測することにあります。そして、その予測結果をラベル付きデータとみなして、改めて学習データに加えることで、より多くのデータで学習した高性能なモデルを構築します。
例えば、猫と犬の画像分類を考えましょう。数百枚のラベル付き画像(猫と犬それぞれにラベルがついた画像)と、数千枚のラベルなし画像(猫か犬かは不明な画像)があるとします。まず、ラベル付き画像のみを用いて、猫と犬を見分ける初期モデルを学習させます。次に、このモデルを用いて、ラベルなし画像に猫か犬かのラベルを予測します。そして、これらの予測結果をラベルとして用い、ラベル付き画像と合わせて改めてモデルを学習させます。このようにすることで、ラベルなし画像の情報も活用した、より正確な猫と犬の分類モデルが得られる可能性があります。
従来の教師あり学習では、大量のラベル付きデータが必要でしたが、半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせることで、この問題を克服し、より少ないコストで高性能なモデルを構築できる可能性を秘めています。そのため、様々な分野への応用が期待されています。
半教師あり学習の利点

機械学習を行う上で、学習データに答えとなるラベルを付ける作業は欠かせません。しかし、このラベル付け作業は多くの時間と手間がかかる大変な仕事です。専門家の知識が必要な場合もあり、大量のデータ全てにラベルを付けるのは現実的に難しいことも少なくありません。そこで注目されているのが、半教師あり学習という手法です。
半教師あり学習の最大の利点は、ラベル付け作業の負担を軽減できることです。少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習することで、全てのデータにラベルを付ける必要がなくなります。ラベル付きデータから学習したパターンをラベルなしデータにも適用することで、ラベルなしデータから有用な情報を引き出し、モデルの精度向上に役立てます。
ラベル付きデータが少ない状況でも、大量のラベルなしデータから知識を補うことで、高精度なモデルを構築することが可能になります。これは、ラベル付けに費用や時間がかかる医療画像診断や自然言語処理といった分野で特に有効です。例えば、数万枚のレントゲン写真全てに専門家が診断結果をラベル付けするのは大変ですが、半教師あり学習を用いれば、数百枚程度のラベル付きデータと、ラベルなしの残りのデータを使うことで、効率的に学習を進めることができます。
さらに、データの偏りを減らす効果も期待できます。ラベル付きデータは限られた条件で収集されることが多いため、データに偏りが生じやすい傾向があります。ラベルなしデータは多様な状況を反映していることが多く、これらを学習に取り入れることで、より現実に近いモデルを構築し、予測精度を向上させることが期待できます。このように、半教師あり学習は限られた資源を活用して、効果的に機械学習モデルを構築するための、大変有力な手法と言えるでしょう。
| 半教師あり学習のメリット | 詳細 | 具体例 |
|---|---|---|
| ラベル付け作業の負担軽減 | 少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習することにより、全てのデータにラベルを付ける必要がなくなる。 | – |
| ラベル付きデータが少ない状況でも高精度なモデル構築が可能 | ラベルなしデータから知識を補うことで、高精度なモデルを構築できる。 | 医療画像診断、自然言語処理 |
| データの偏りを減らす効果 | ラベルなしデータは多様な状況を反映していることが多く、これらを学習に取り入れることで、より現実に近いモデルを構築できる。 | – |
半教師あり学習の応用例

少量のラベル付きデータと大量のラベルなしデータの両方を使って学習を行う半教師あり学習は、様々な分野で応用され、成果を上げています。ラベル付きデータを作るには費用と時間がかかるため、大量に用意することが難しい場合が多いです。しかし、ラベルなしデータは比較的容易に大量に集めることが可能なため、この二種類のデータを組み合わせる半教師あり学習は、限られた資源を有効活用できる学習方法として注目を集めています。
例えば、画像認識の分野では、少しのラベル付き画像と多くのラベルなし画像を使うことで、画像の分類精度を向上させることができます。ラベル付き画像から抽出された特徴をラベルなし画像にも適用することで、より多くの画像データで学習できるようになり、結果として分類の精度が向上します。数万枚もの画像にラベルを付けるのは大変な作業ですが、半教師あり学習では、その作業量を大幅に減らすことができます。
また、言葉を取り扱う自然言語処理の分野でも、半教師あり学習は有効です。少しのラベル付き文章と多くのラベルなし文章を使って、文章の分類や感情分析などを効率的に行うことができます。例えば、ニュース記事のを「政治」「経済」「スポーツ」などに分類するタスクを考えます。ラベル付きのデータが少量しかない場合でも、大量のラベルなしニュース記事を利用することで、分類器の精度を向上させることが可能です。
さらに、音声認識の分野でも、少しの音声データと多くのラベルなし音声データを使うことで、音声認識の精度向上に役立っています。音声データへのラベル付けは、専門的な知識が必要な場合もあり、多くの時間と費用がかかります。半教師あり学習を用いることで、ラベル付けされた音声データが少なくても、大量のラベルなし音声データから学習し、認識精度を向上させることができます。
このように、半教師あり学習は、ラベル付きデータの不足をラベルなしデータで補うことで、様々な分野で性能向上を実現する強力な手法となっています。
| 分野 | 効果 | 詳細 |
|---|---|---|
| 画像認識 | 画像分類精度の向上 | 少量のラベル付き画像と大量のラベルなし画像を使い、ラベル付き画像から抽出された特徴をラベルなし画像にも適用することで、多くの画像データで学習を行い、分類精度を向上させる。 |
| 自然言語処理 | 文章分類や感情分析の効率化 | 少量のラベル付き文章と大量のラベルなし文章を使い、例えばニュース記事の分類タスクにおいて、少量のラベル付きデータでも大量のラベルなしデータを利用することで分類器の精度を向上させる。 |
| 音声認識 | 音声認識精度の向上 | 少量の音声データと大量のラベルなし音声データを使い、ラベル付けのコストを削減しつつ、大量のラベルなしデータから学習し、認識精度を向上させる。 |
半教師あり学習の課題

半教師あり学習は、限られた量のラベル付きデータと大量のラベルなしデータを利用して、学習モデルを構築する手法です。多くの分野で有効性が示されていますが、いくつかの課題も抱えています。
まず、ラベルなしデータの質が学習結果に大きく影響します。ラベルなしデータにノイズが多く含まれている場合、あるいはラベル付きデータの分布と大きく異なる場合、モデルは誤ったパターンを学習し、精度が低下する可能性があります。例えば、猫の画像認識モデルを学習させる際に、ラベルなしデータに犬や鳥の画像が大量に含まれていると、モデルは猫の特徴をうまく捉えられなくなるかもしれません。
次に、モデルの仮定とデータの特性の不一致も問題となります。半教師あり学習では、データの分布について何らかの仮定を置くことが一般的です。例えば、似た特徴を持つデータは同じラベルを持つ可能性が高いといった仮定です。しかし、この仮定が実際のデータの特性と合致しない場合、モデルは適切な学習を行うことができません。現実のデータは複雑な構造を持つことが多く、単純な仮定ではうまく表現できない場合も少なくありません。
さらに、適切な学習手法の選択も重要です。半教師あり学習には様々なアルゴリズムが存在し、それぞれ異なる特性を持っています。また、各アルゴリズムには調整が必要なパラメータも複数存在します。これらのアルゴリズムやパラメータの選択が適切でない場合、期待する性能が得られないばかりか、学習に時間がかかったり、過学習といった問題が発生する可能性もあります。最適な手法はデータの特性に依存するため、試行錯誤が必要となる場合もあります。
これらの課題を克服するために、ラベルなしデータの質を評価する手法や、より柔軟なモデルの開発、効率的なアルゴリズムの研究など、様々な取り組みが進められています。今後の更なる発展により、半教師あり学習はより多くの分野で活用され、より高度なタスクを解決できるようになると期待されています。
| 課題 | 説明 | 例 |
|---|---|---|
| ラベルなしデータの質 | ノイズの多いラベルなしデータや、ラベル付きデータと分布の異なるラベルなしデータは、モデルの精度を低下させる可能性がある。 | 猫の画像認識モデルで、ラベルなしデータに犬や鳥の画像が多い場合、猫の特徴を捉えにくくなる。 |
| モデルの仮定とデータの特性の不一致 | 半教師あり学習のモデルはデータ分布について仮定を置くが、この仮定が実際のデータと合致しないと、適切な学習ができない。 | 現実のデータは複雑な構造を持つことが多く、単純な仮定ではうまく表現できない場合がある。 |
| 適切な学習手法の選択 | 様々なアルゴリズムやパラメータが存在し、適切な選択が重要。不適切な選択は、性能低下、学習時間の増加、過学習などの問題を引き起こす。 | 最適な手法はデータの特性に依存し、試行錯誤が必要となる場合もある。 |
まとめ

近年、機械学習の分野で注目を集めている手法の一つに、半教師あり学習があります。この学習方法は、大量のデータの中から一部だけにラベル(正解)が付与された状況で、ラベルのないデータも活用してモデルを学習させるというものです。従来の教師あり学習では、全てのデータにラベルが必要でしたが、現実世界ではラベル付け作業に膨大な費用と時間がかかる場合が多く、大量のラベル付きデータを得ることが難しいケースが少なくありません。半教師あり学習を用いることで、限られたラベル付きデータと大量のラベルなしデータを組み合わせ、モデルの精度を高めることが可能になります。
例えば、猫の画像認識を行う場合を考えてみましょう。教師あり学習では、大量の猫の画像に「猫」というラベルを付けて学習させますが、半教師あり学習では、ラベル付きの猫の画像に加えて、ラベルのない画像も学習に利用します。ラベルなしの画像には、猫以外の動物や物体の画像も含まれている可能性がありますが、これらの画像もモデル学習に役立ちます。具体的には、ラベル付きデータから猫の特徴を学習し、その特徴に基づいてラベルなしデータに含まれる猫の画像を推定することで、より多くの「猫」の情報をモデルに与えることができるのです。
半教師あり学習は、ラベル付け作業の負担を軽減するだけでなく、ラベル付きデータだけでは得られない情報をモデルに与えることで、より高精度なモデルの構築を可能にします。画像認識以外にも、音声認識や自然言語処理など様々な分野で応用されており、今後ますます発展していくことが期待されます。ただし、ラベルなしデータの質やモデルへの仮定、学習アルゴリズムの選択など、いくつかの課題も存在します。これらの課題を克服することで、半教師あり学習は、限られた情報からより多くの知識を引き出す、機械学習の新たな可能性を切り開いていくと期待されます。
| 学習方法 | データ | メリット | 例(猫の画像認識) | 応用分野 | 課題 | 将来性 |
|---|---|---|---|---|---|---|
| 教師あり学習 | 全てラベル付き | – | 全ての猫画像に「猫」ラベル | – | ラベル付けのコスト | – |
| 半教師あり学習 | 一部ラベル付き + ラベルなし | ラベル付け作業軽減、ラベル付きデータだけでは得られない情報の活用、モデル精度向上 | ラベル付き猫画像 + ラベルなし画像(猫含む) ラベル付きデータから猫特徴学習、ラベルなしデータから猫画像推定 |
画像認識、音声認識、自然言語処理など | ラベルなしデータの質、モデルへの仮定、学習アルゴリズムの選択 | 限られた情報から知識獲得、機械学習の新たな可能性 |