偽陽性と偽陰性:機械学習の落とし穴

AIの初心者
先生、「偽陽性」と「偽陰性」って、どう違うんですか?よく分からなくて…

AI専門家
そうだね、少し分かりにくいよね。病気の検査で考えてみようか。例えば、インフルエンザの検査で、「実際はインフルエンザにかかっていないのに、陽性と判定される」のが偽陽性だよ。逆に、「実際はインフルエンザにかかっているのに、陰性と判定される」のが偽陰性だよ。
AIの初心者
なるほど。陽性だけど実際は病気じゃないのが偽陽性で、陰性だけど実際は病気なのが偽陰性ですね。でも、どっちの方がより問題なんですか?
AI専門家
状況によるね。偽陽性の場合、必要のない治療や隔離を受ける可能性がある。偽陰性の場合、適切な治療を受けられず、病気を広げてしまう可能性がある。だから、どちらが悪いとも言えないんだ。病気の性質や検査の目的によって、どちらの誤りを減らすことを重視するかが変わってくるんだよ。
偽陽性-偽陰性とは。
人工知能の分野でよく使われる「偽陽性」と「偽陰性」について説明します。二つの値で分類する問題を扱うとき、予測した結果と実際の結果の関係を表すのに、二行二列の表が使われます。この表は、予測と実際の結果の組み合わせによって、「真陽性」「偽陽性」「偽陰性」「真陰性」の四つの要素に分けられます。これらの要素を使って、「正解率」「適合率」「再現率」「F値」といった指標が計算されます。目的に合わせてこれらの指標を選び、モデルの評価を適切に行うことが重要です。
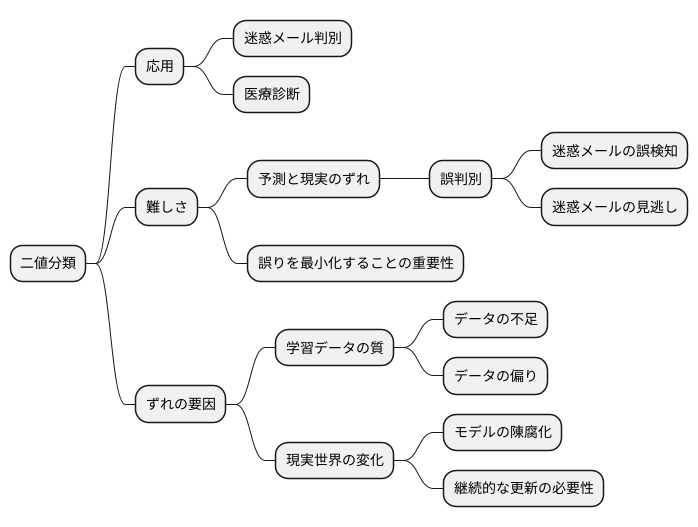
二値分類の難しさ

機械学習の様々な手法の中でも、二つの選択肢から一つを選ぶ二値分類は、幅広い分野で活用されています。身近な例では、受信した電子メールを迷惑メールかそうでないかを見分ける、医療の現場では、画像から病気を診断する、といった応用が考えられます。このように、二値分類は一見簡単なように思われますが、実際には複雑な問題を孕んでおり、深い理解が必要です。
二値分類の難しさは、予測と現実の間にずれが生じることに起因します。例えば、迷惑メールの判別システムを構築する場合を考えてみましょう。システムは、過去のデータに基づいて、特定の特徴を持つメールを迷惑メールと判断します。しかし、この判断基準は完全ではなく、実際には迷惑メールではないのに迷惑メールと誤って判断される場合や、逆に迷惑メールを見逃してしまう場合があります。このような予測の誤りは避けられない問題であり、この誤りをいかに小さくするかが、正確な二値分類モデルを構築する上で鍵となります。
予測と現実のずれは、様々な要因によって引き起こされます。一つは、学習データの質です。限られたデータで学習した場合、現実世界で見られるデータのパターンを全て網羅できないため、予測精度が低下する可能性があります。また、データに偏りがある場合、特定の傾向を持ったデータに対してのみ高い精度を示し、それ以外のデータにはうまく対応できないといった問題が生じる可能性があります。さらに、現実世界は常に変化しており、過去のデータで学習したモデルが将来も有効とは限りません。そのため、常に新しいデータを取り込み、モデルを更新していく必要があります。これらの難しさを理解し、適切な対策を講じることで、より精度の高い二値分類モデルを構築することが可能となります。
混同行列による理解

二つの状態を区別する予測作業の成果を詳しく調べる方法として、混同行列というものがあります。これは、実際の状態と予測した状態を組み合わせた四つの場合をまとめた表です。表は縦横に二つの項目があり、縦には実際の状態(例えば、病気である、病気でない)、横には予測した状態(例えば、病気と予測、病気でないと予測)が並びます。この組み合わせにより、四つのマス目ができます。
まず、実際の状態が「陽性」(例えば、実際に病気である)で、予測も「陽性」(病気と予測)だった場合、これを「真陽性」と言います。これは、正しく予測できたケースです。次に、実際の状態は「陰性」(例えば、実際は病気でない)なのに、予測は「陽性」(病気と予測)だった場合、これを「偽陽性」と言います。これは、健康な人を誤って病気と判断したケースです。逆に、実際の状態は「陽性」(実際に病気である)なのに、予測は「陰性」(病気でないと予測)だった場合、これを「偽陰性」と言います。これは、病気の人を見逃してしまったケースです。最後に、実際の状態は「陰性」(実際は病気でない)で、予測も「陰性」(病気でないと予測)だった場合、これを「真陰性」と言います。これも、正しく予測できたケースです。
この四つの値を把握することで、予測モデルの良し悪しを様々な視点から評価できます。例えば、真陽性の数が多いほど、実際に陽性であるものを正しく陽性と予測できていることを示します。偽陽性の数が多い場合は、本来陰性であるものを誤って陽性と判断していることを示し、注意が必要です。偽陰性が多い場合は、見落としが多いことを示し、これも改善が必要です。真陰性が多い場合は、実際に陰性であるものを正しく陰性と予測できていることを示します。これらの値を組み合わせて計算することで、精度や再現率、適合率など、様々な指標を算出し、モデルの性能をより深く理解することができます。このように、混同行列は、二値分類の予測結果を評価するための基本的なツールであり、その理解は非常に重要です。
| 予測:陽性 | 予測:陰性 | |
|---|---|---|
| 実際:陽性 | 真陽性 | 偽陰性 |
| 実際:陰性 | 偽陽性 | 真陰性 |
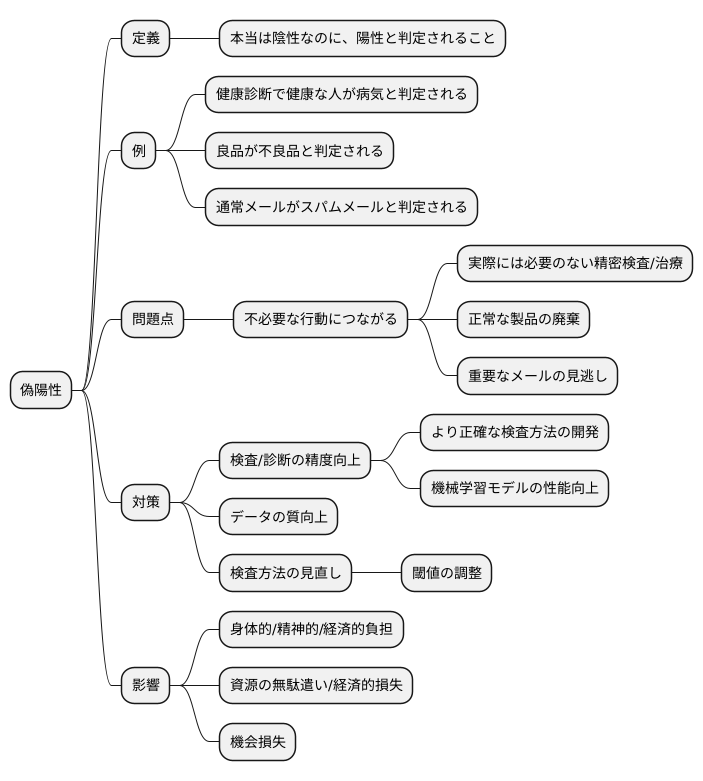
偽陽性とは何か

「偽陽性」とは、本当は違っているのに、ある状態だと誤って判断されることを意味します。具体的に言うと、実際には陰性、つまり何も問題がない状態なのに、検査や診断の結果が陽性、つまり問題ありと出てしまうことです。
例として、健康診断を考えてみましょう。健康診断では、様々な検査を通じて病気の有無を調べます。もし、実際には健康な人なのに、検査結果が病気ありと出てしまったら、これが偽陽性です。他の例としては、工場で不良品ではない製品を不良品と判定してしまうケースや、スパムメールではない普通のメールをスパムメールと判断してしまうケースなども偽陽性にあたります。
偽陽性が問題となるのは、その後に続く不必要な行動につながる可能性があるからです。健康診断の例では、偽陽性の結果を受けて、実際には必要のない精密検査や治療を受けてしまうかもしれません。これは、身体的な負担だけでなく、精神的な負担や経済的な負担にもつながります。工場の例では、偽陽性によって正常な製品が廃棄されてしまい、資源の無駄遣いや経済的な損失につながる可能性があります。スパムメールの例では、重要なメールがスパムフォルダに振り分けられてしまい、見逃してしまう可能性があります。
偽陽性を減らすためには、様々な対策が必要です。まず、検査や診断の精度を上げることが重要です。より正確な検査方法を開発したり、機械学習モデルの性能を向上させたりすることで、偽陽性の発生率を下げることができます。また、検査に用いるデータの質を高めることも重要です。ノイズの多いデータや偏りのあるデータを使っていると、偽陽性が増える可能性があります。さらに、検査方法そのものを見直すことも重要です。検査の閾値を調整することで、偽陽性と偽陰性のバランスを調整することができます。
このように、偽陽性は様々な場面で発生する可能性があり、私たちに様々な影響を与える可能性があります。偽陽性の問題を理解し、適切な対策を講じることで、より安全で安心な社会を実現することができるでしょう。
偽陰性とは何か

検査で本当の答えと違う結果が出てしまうことを「偽陰性」と言います。本当は病気なのに、検査では病気ではないと判断されてしまう場合がこれに当たります。例えば、ある病気に実際はかかっているのに、健康診断などで「異常なし」とされてしまうと、偽陰性ということになります。
偽陰性がなぜ問題となるかというと、病気の発見が遅れてしまうことにあります。検査で「病気ではない」と判断された場合、多くの人は安心し、治療を受けようとは考えません。しかし、実際には病気が進行しているため、治療の開始が遅れ、病状が悪化してしまう恐れがあります。早期発見が大切な病気であればあるほど、この遅れは深刻な事態を招きかねません。
例えば、ある感染症にかかっている人が、検査で陰性と判定されたとします。その人は自分が健康だと思い込み、普段通りの生活を送るでしょう。しかし、実際には感染症にかかっており、知らず知らずのうちに周囲の人に病気を広げてしまうかもしれません。また、本人も適切な治療を受けられないため、病状が重症化してしまう可能性もあります。
偽陰性を完全に無くすことは難しいですが、検査方法の精度を上げたり、複数の検査を組み合わせたりすることで、その発生率を下げる努力が続けられています。また、少しでも体の異変を感じたら、検査結果にかかわらず、医師に相談することも大切です。検査はあくまでも補助的な手段であり、最終的な判断は医師の診察によって行われるべきです。自分の体の状態に気を配り、少しでも不安があれば医療機関を受診することで、偽陰性によるリスクを減らすことができます。
| 項目 | 説明 |
|---|---|
| 偽陰性とは | 本当は病気なのに、検査では病気ではないと判断されてしまうこと。 |
| 問題点 | 病気の発見が遅れ、治療開始が遅れることで病状が悪化したり、感染症の場合、周囲に病気を広げてしまう可能性がある。 |
| 対策 | 検査精度の向上、複数検査の組み合わせ、体の異変を感じたら検査結果に関わらず医師に相談。 |
偽陽性と偽陰性のバランス

「偽陽性」と「偽陰性」は、まるでシーソーのようにバランスを取り合っています。片方を下げようとすると、もう片方が上がってしまう、そんな関係性です。そのため、どちらの誤りをより重要視するかは、場面によって慎重に判断しなければなりません。
例えば、健康診断を想像してみてください。特に命に関わる病気の検査では、病気を見逃すことは絶対に避けたいものです。このような場合には、「偽陰性」、つまり実際には病気であるにもかかわらず健康と判断される誤りを最小限に抑えることが最優先事項となります。病気の兆候を見つけるために、多少「偽陽性」、つまり健康なのに病気と判断される誤りが増えても、精密検査で詳しく調べることで最終的には正しい診断にたどり着けます。早期発見、早期治療のためには、多少の「偽陽性」は許容できる範囲と言えるでしょう。
一方で、迷惑メールの対策を考えてみましょう。重要なメールが迷惑メールフォルダに振り分けられてしまうと、大切な連絡を見逃してしまう可能性があります。この場合、優先すべきは「偽陽性」、つまり実際には迷惑メールではないのに迷惑メールと判断される誤りを減らすことです。多少の迷惑メールが届いてしまっても、重要なメールを確実に受信できる方が重要です。重要なメールが迷惑メールに分類されて見逃されることによる損失は、迷惑メールをいくつか受信することによる損失よりもはるかに大きいからです。
このように、「偽陽性」と「偽陰性」のどちらを重視するかは、その状況によって大きく異なります。がん検診のように、見逃しが許されない状況では「偽陰性」を減らすことを重視し、迷惑メール対策のように、誤った判断による損失を避けたい場合は「偽陽性」を減らすことを重視します。重要なのは、それぞれの目的に合わせて、最適なバランス点を見つけることです。目的に応じて適切なバランスを取ることで、検査やシステムの効果を最大限に発揮することができます。
| 状況 | 重視する誤り | 理由 |
|---|---|---|
| 健康診断(命に関わる病気) | 偽陰性(実際は病気なのに健康と判断) | 病気の見逃しは絶対に避けたい。偽陽性(健康なのに病気と判断)は精密検査で修正可能。早期発見・治療が重要。 |
| 迷惑メール対策 | 偽陽性(実際は迷惑メールではないのに迷惑メールと判断) | 重要なメールの見逃しを防ぎたい。偽陰性(実際は迷惑メールなのに正常と判断)による損失は比較的小さい。 |
様々な評価指標

機械学習モデルの性能を正しく測るには、様々な評価指標を使い分けることが重要です。一口に評価指標といっても、それぞれ何を測るのか、どのような状況で使うべきなのかが違います。よく使われる指標に、正解率、適合率、再現率、F値などがあります。
まず、正解率は、全体の中でどれだけの予測が当たっていたかを示す、最も基本的な指標です。しかし、データの偏りに弱いという欠点があります。例えば、病気の診断で、病気の人が全体の1%しかいない場合、常に「病気ではない」と予測すれば、正解率は99%になりますが、病気の人を見つけるという本来の目的は達成できていません。
データに偏りがある場合は、適合率と再現率に着目する必要があります。適合率は、陽性と予測したデータのうち、実際に陽性だった割合です。病気の診断の例でいえば、「病気である」と予測した人のうち、実際に病気だった人の割合です。一方、再現率は、実際に陽性であるデータのうち、どれだけの割合を陽性と予測できたかを表します。病気の例では、実際に病気の人の中で、どれだけの割合を「病気である」と正しく予測できたかを示します。
適合率と再現率はトレードオフの関係にあることが多く、どちらか一方を高くしようとすると、もう一方が低くなる傾向があります。例えば、病気の診断で、少しでも病気の疑いがあれば陽性と予測すれば、再現率は高くなりますが、健康な人も陽性と判定されるため、適合率は低くなります。逆に、非常に強い症状がある場合のみを陽性と予測すれば、適合率は高くなりますが、軽度の病気の人を見逃す可能性が高くなり、再現率は低くなります。
適合率と再現率のバランスを考えた指標がF値です。F値は、適合率と再現率の調和平均で計算されます。そのため、どちらか一方だけが極端に高い場合よりも、両方がバランスよく高い場合に、F値は高くなります。このように、それぞれの指標には得意不得意があり、データの特性や目的を考慮して適切な指標を選択することが重要です。
| 評価指標 | 意味 | 計算方法 | 長所 | 短所 | 適用場面 |
|---|---|---|---|---|---|
| 正解率 | 全体の中でどれだけの予測が当たっていたかの割合 | (正しく予測した数) / (全体のデータ数) | 理解しやすく、計算が簡単 | データの偏りに弱い | データの偏りがなく、クラスの割合が均等に近い場合 |
| 適合率 (Precision) | 陽性と予測したデータのうち、実際に陽性だった割合 | (真陽性) / (真陽性 + 偽陽性) | 偽陽性を抑えたい場合に有効 | 偽陰性を見逃す可能性がある | スパムメール検知など、偽陽性を避けたい場合 |
| 再現率 (Recall) | 実際に陽性であるデータのうち、どれだけの割合を陽性と予測できたか | (真陽性) / (真陽性 + 偽陰性) | 偽陰性を抑えたい場合に有効 | 偽陽性が増える可能性がある | がん検診など、偽陰性を避けたい場合 |
| F値 (F-measure) | 適合率と再現率の調和平均 | 2 * (適合率 * 再現率) / (適合率 + 再現率) | 適合率と再現率のバランスを考慮 | どちらの指標も同等に重要視する場合に最適 | 適合率と再現率の両方を考慮したい場合 |