
ADAMとは?機械学習で使われる最適化手法をわかりやすく解説

AIの初心者
『ADAM』って難しそうですが、簡単に言うとどんなものですか?

AI専門家
ADAMは、機械学習モデルの重みなどのパラメータを、より良い値へ少しずつ調整するための最適化手法です。予測の誤差を小さくする方向を見ながら、効率よく学習を進めるために使われます。
AIの初心者
効率よく調整する、というのは具体的に何をしているのでしょうか?
AI専門家
ADAMは、過去の勾配の流れを表すモーメンタムと、勾配の大きさの平均を使って、次にどれくらい動かすかを決めます。でこぼこした損失の地形でも、比較的安定して良い方向へ進めるのが特徴です。
ADAMは「Adaptive Moment Estimation」の略で、深層学習や機械学習で広く使われるパラメータ更新のための最適化アルゴリズムです。ニューラルネットワークは、入力と正解のずれを表す損失を小さくするように、重みやバイアスなどのパラメータを何度も更新します。この更新の進め方を決めるのが、SGDやMomentum、RMSprop、ADAMといった最適化手法です。

ADAMの特徴は、単に現在の勾配だけを見るのではなく、過去の勾配の平均と、過去の勾配の二乗平均を同時に利用する点にあります。これにより、学習の向きを滑らかに保ちながら、パラメータごとに更新幅を調整できます。初期設定でも比較的うまく動くことが多いため、実装では「まずAdamを試す」という選択がよく行われます。
ADAMの仕組み
機械学習では、損失関数を小さくするために勾配を使います。勾配とは、パラメータを少し変えたときに損失がどちらへ、どれくらい変わるかを示す情報です。勾配が示す方向へ少しずつ動けば、モデルは正解に近い予測を出せるようになります。
ただし、現在の勾配だけを頼りにすると、学習が不安定になることがあります。勾配がノイズを含んでいると進む方向が揺れますし、パラメータによって勾配の大きさが大きく違うと、一部だけ更新が進みすぎたり、逆にほとんど進まなかったりします。
ADAMはこの問題に対して、次の2つの情報を持ちながら更新します。
| 要素 | 意味 | 役割 |
|---|---|---|
| 1次モーメント | 過去の勾配の移動平均 | 学習が進む方向を滑らかにする |
| 2次モーメント | 過去の勾配の二乗の移動平均 | パラメータごとの更新幅を調整する |

1次モーメントは、Momentumで使われる「過去の進行方向を少し残す」考え方に近いものです。坂道を転がるボールのように、毎回の勾配に振り回されず、これまでの流れを反映して進みます。これにより、ジグザグした動きが抑えられ、損失の谷に沿って進みやすくなります。
2次モーメントは、RMSpropで使われる「勾配が大きい方向は慎重に、勾配が小さい方向は相対的に大きく進む」という考え方に近いものです。パラメータごとに勾配の大きさが違っても、同じ学習率をそのまま適用するのではなく、更新幅を自動的に調整します。
ADAMの更新式を初心者向けに見る
\(ADAMの数式は一見複雑ですが、考えていることは「勾配の平均」と「勾配の二乗平均」を使って、次の更新量を決めることです。代表的な更新式は次のように表されます。
[latex]m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t\) \(v_t = \beta_2 v_{t-1} + (1-\beta_2)g_t^2\) \(\theta_t = \theta_{t-1} – \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon}\)
ここで、\(g_t\) は現在の勾配、\(m_t\) は勾配の移動平均、\(v_t\) は勾配の二乗の移動平均です。\(\alpha\) は学習率、\(\epsilon\) はゼロ除算を避けるための小さな値です。実装上は \(\beta_1\) と \(\beta_2\) によって、過去の情報をどれくらい残すかを調整します。
初心者が押さえるべき点は、数式の各記号を暗記することではありません。重要なのは、ADAMが過去の方向と過去の大きさを別々に記録し、それらを組み合わせて更新量を決めるという構造です。この構造があるため、単純な勾配降下法よりも、ノイズのある学習やパラメータごとのスケール差に対応しやすくなります。
また、ADAMでは学習の初期に移動平均がゼロに偏りやすいため、バイアス補正と呼ばれる処理が行われます。これは、学習を始めたばかりの段階で平均値が小さく見積もられすぎないようにする補正です。多くの機械学習ライブラリでは、この処理はOptimizerの内部で自動的に行われます。
ADAMのメリット
ADAMの大きなメリットは、学習が比較的安定しやすく、扱いやすいことです。SGDでは学習率の調整が難しく、問題によっては収束までに時間がかかることがあります。ADAMはパラメータごとに更新幅を調整するため、勾配の大きさがばらつく問題でも学習を進めやすくなります。
特に、画像認識、自然言語処理、推薦モデル、生成モデルなど、パラメータ数が多く損失の地形が複雑な課題では、ADAMが有力な選択肢になります。初期値としてよく使われる設定がライブラリに用意されているため、初心者でも試しやすい点も実務上の利点です。
| メリット | 説明 |
|---|---|
| 収束が速いことが多い | 過去の勾配情報を利用するため、初期学習が進みやすい |
| 更新が安定しやすい | 勾配の移動平均により、ノイズによる揺れを抑えやすい |
| パラメータごとに調整できる | 勾配の二乗平均を使い、更新幅を自動的に変えられる |
| 最初に試しやすい | 多くの課題で標準的な候補として使える |
ただし、「Adamなら必ず最良」という意味ではありません。学習が速いことと、最終的な汎化性能が最も高いことは別です。検証データでの性能や過学習の有無を見ながら、他の最適化手法とも比較することが大切です。
ADAMの注意点とデメリット
ADAMは便利ですが、万能ではありません。まず、1次モーメントと2次モーメントをパラメータごとに保存するため、単純なSGDよりも多くのメモリを使います。小さなモデルでは大きな問題になりにくいものの、大規模モデルではOptimizerの状態が無視できないサイズになります。
次に、問題によってはSGDやMomentumのほうが良い汎化性能を示すことがあります。ADAMは学習を速く進める一方で、最終的な解の性質が問題に合わない場合もあります。そのため、論文再現や本番モデルの調整では、AdamだけでなくSGD系やAdamWなども比較対象に入れるとよいでしょう。
さらに、学習率の設定は依然として重要です。ADAMは更新幅を自動調整しますが、学習率が大きすぎれば損失が不安定になり、小さすぎれば学習が進みにくくなります。損失曲線や検証指標を確認しながら、必要に応じて学習率スケジューラを併用します。
SGD・Momentum・RMSpropとの違い
ADAMを理解するには、関連する最適化手法との違いを見るのが有効です。SGDは現在の勾配に基づいてシンプルに更新します。Momentumは過去の方向を加味して滑らかに進みます。RMSpropは勾配の大きさに応じて更新幅を調整します。ADAMは、MomentumとRMSpropの考え方を組み合わせた手法と捉えると理解しやすくなります。
| 手法 | 主な考え方 | 特徴 |
|---|---|---|
| SGD | 現在の勾配で更新する | シンプルでメモリ効率がよいが、学習率調整が重要 |
| Momentum | 過去の進行方向を残す | ジグザグを抑え、谷方向に進みやすい |
| RMSprop | 勾配の二乗平均で更新幅を調整する | パラメータごとのスケール差に対応しやすい |
| ADAM | MomentumとRMSpropの考え方を組み合わせる | 安定性と速さのバランスがよく、最初の候補にしやすい |
なお、実務ではAdamWもよく使われます。AdamWは、重み減衰をAdamの更新から分離して扱う手法です。特に深層学習では、AdamよりAdamWのほうが標準的に選ばれる場面も増えています。重量減衰を使って汎化性能を高めたい場合は、AdamWも候補に入れるとよいでしょう。
ADAMを使うときの実務上のポイント
ADAMを使うときは、まずライブラリの標準設定から始め、学習曲線を確認するのが現実的です。損失が下がらない場合は学習率が小さすぎる可能性があり、損失が大きく揺れる場合は学習率が大きすぎる可能性があります。訓練データの損失だけでなく、検証データの指標も必ず確認します。
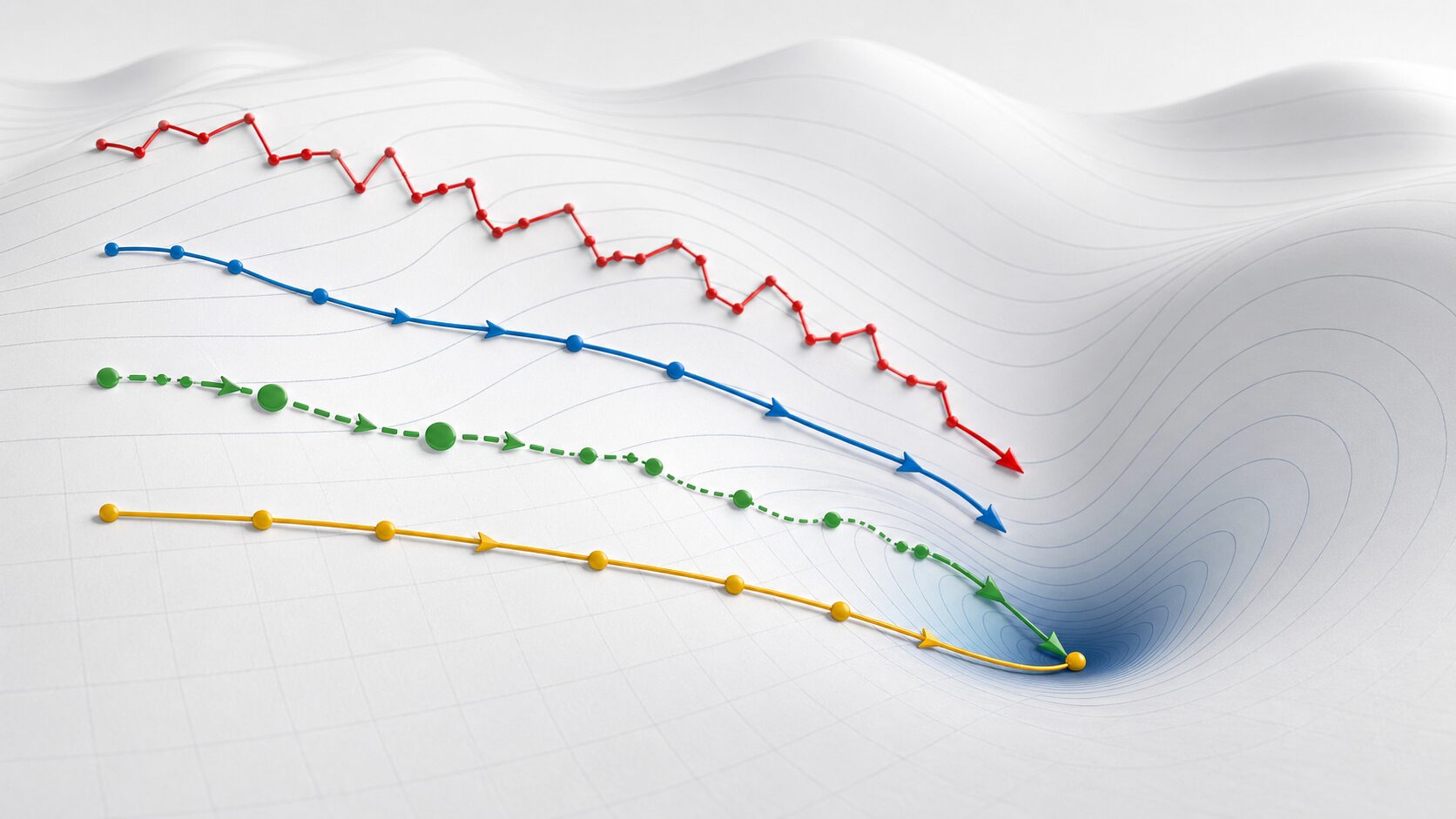
また、バッチサイズ、学習率スケジューラ、正則化、勾配クリッピングなども学習結果に影響します。特にTransformer系のモデルや大規模なニューラルネットワークでは、AdamW、warmup、weight decayを組み合わせる構成がよく使われます。Adamを選ぶだけでなく、周辺設定も含めて評価することが重要です。
初心者は、まず「Adamは勾配を使って学習を進めるOptimizerであり、過去の方向と大きさを使って更新を調整する」と理解すれば十分です。そのうえで、学習率、検証データでの性能、他のOptimizerとの比較を順に確認すると、実装で迷いにくくなります。
まとめ
ADAMは、機械学習モデルのパラメータを効率よく更新するための最適化手法です。過去の勾配の平均を使うことで進む方向を滑らかにし、勾配の二乗平均を使うことでパラメータごとの更新幅を調整します。
そのため、ADAMは学習が安定しやすく、初期設定でも扱いやすいOptimizerとして広く使われています。一方で、メモリ使用量、学習率、汎化性能、AdamWなど関連手法との比較も無視できません。実務では、まずAdamまたはAdamWを試し、検証データで性能を確認しながら調整するという進め方が有効です。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月1日 | ADAMの定義、仕組み、更新式、関連手法との違い、実務上の注意点を初心者向けに再構成 |