Huber損失:機械学習で頑健な回帰を実現

AIの初心者
「フーバー損失」って、一体どんなものなんですか?普通の損失関数と何が違うんですか?

AI専門家
良い質問だね。フーバー損失は、外れ値の影響を受けにくくするための損失関数なんだ。普通の二乗誤差は、大きく外れた値があると損失が急に大きくなり、モデルがその値に引っ張られやすい。フーバー損失は、誤差が小さいうちは二乗誤差のように扱い、誤差が大きくなると絶対値誤差のように扱うから、外れ値に振り回されにくいんだよ。
AIの初心者
なるほど。誤差が小さい範囲と大きい範囲で計算方法を変えるんですね。どのくらいの誤差で切り替わるんですか?
AI専門家
切り替える位置は、事前に決める閾値で調整するんだ。この閾値を変えることで、外れ値の影響をどの程度抑えるかをコントロールできる。だから、データの性質に合わせて適切な値を探すことが大切なんだよ。
Huber損失とは。
Huber損失とは、統計学や機械学習で使われる損失関数の一つです。予測値と正解値の差である誤差をもとに損失を計算し、外れ値の影響を抑えながら回帰モデルを学習しやすくします。誤差は「予測値から正解値を引いた値」でも「正解値から予測値を引いた値」でも、絶対的なずれとして考えれば同じ意味で扱えます。
はじめに
機械学習では、数値を予測するモデルを作る場面が多くあります。住宅価格、需要予測、センサー値、株価の変動など、連続した数値を予測するタスクは回帰と呼ばれます。
回帰モデルを学習するときは、予測値と実際の値のずれを小さくするようにモデルを調整します。このずれを数値化するものが損失関数です。損失関数は、モデルがどれくらい予測を外しているかを測るものさしだと考えると分かりやすいでしょう。
ただし、データには外れ値が含まれることがあります。外れ値とは、ほかのデータから大きく離れた値のことです。たとえば、一般的な住宅価格のデータに極端に高額な物件が少数だけ混ざっている場合、その値にモデルが引っ張られる可能性があります。
Huber損失は、このような問題に対応するために使われます。小さい誤差は二乗誤差のように扱い、大きい誤差は絶対値誤差のように扱うことで、学習のしやすさと外れ値への強さを両立します。
| 損失関数 | 説明 | 特徴 |
|---|---|---|
| Huber損失 | 小さいずれには二乗誤差、大きいずれには絶対値誤差に近い計算を使う損失関数 | 外れ値に強く、閾値で挙動を調整できる |
損失関数とは
損失関数とは、機械学習モデルの予測が正解からどれくらい離れているかを数値で表す関数です。損失が小さいほど、モデルの予測は正解に近いと判断できます。
たとえば、正解値が3で予測値が5だった場合、誤差は2です。この誤差をどのように損失へ変換するかによって、モデルの学習の進み方が変わります。
代表的な損失関数には、二乗誤差と絶対値誤差があります。二乗誤差は誤差を二乗するため、大きな誤差を特に強く評価します。そのため、外れ値があると損失が非常に大きくなり、モデルが外れ値に合わせすぎることがあります。
一方、絶対値誤差は誤差の絶対値をそのまま使います。大きな誤差があっても二乗しないため、外れ値の影響は抑えやすくなります。ただし、誤差がゼロ付近で関数が尖った形になり、勾配を使う最適化では扱いにくい場合があります。
| 損失関数 | 計算の考え方 | 特徴 |
|---|---|---|
| 二乗誤差 | (予測値 – 正解値)^2 | 小さい誤差では滑らかだが、外れ値の影響を受けやすい |
| 絶対値誤差 | |予測値 – 正解値| | 外れ値に強いが、ゼロ付近で最適化しにくい場合がある |
| Huber損失 | 誤差の大きさに応じて二乗誤差型と絶対値誤差型を切り替える | 滑らかさと外れ値への強さを両立しやすい |
Huber損失の仕組み
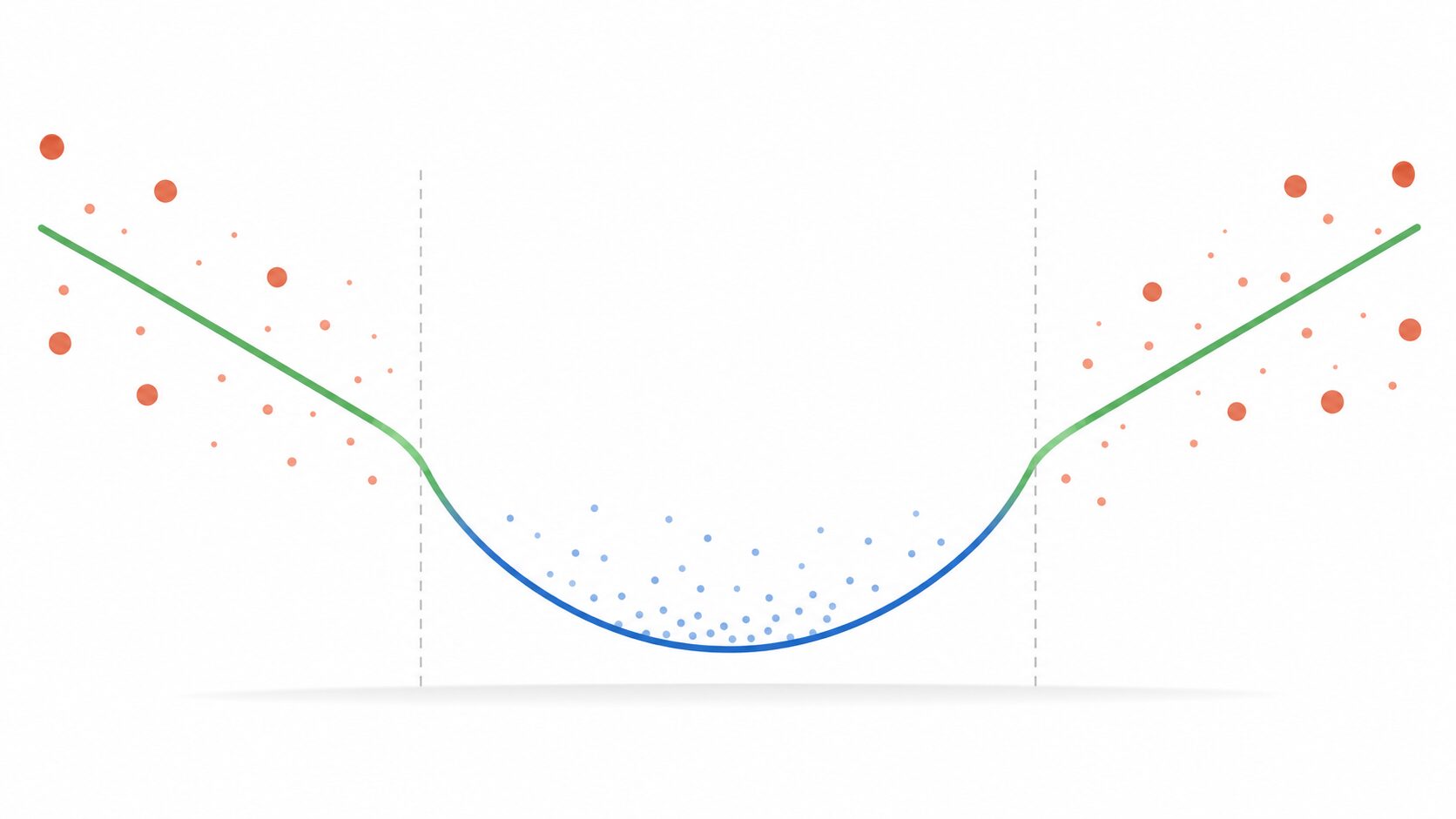
Huber損失の中心にある考え方は、誤差の大きさによって損失の計算方法を変えることです。誤差が小さい範囲では二乗誤差のように振る舞い、誤差が大きい範囲では絶対値誤差に近い形で振る舞います。
この切り替えの基準になる値を閾値と呼びます。数式ではデルタなどの記号で表されることが多く、閾値より小さい誤差は通常のデータとして丁寧に評価し、閾値を超える大きな誤差は外れ値として影響を抑えるイメージです。
二乗誤差は、誤差が小さい領域で滑らかに変化するため、モデルのパラメータを少しずつ改善しやすいという利点があります。しかし、誤差が大きくなるほど損失が急激に増えるため、外れ値に弱くなります。
絶対値誤差は、誤差が大きくなっても損失が直線的に増えるため、外れ値の影響を抑えやすいという利点があります。Huber損失は、この二つの性質を組み合わせたものです。
閾値の設定は重要です。閾値を小さくすると外れ値の影響を強く抑えられますが、本来の傾向まで弱く扱ってしまう可能性があります。閾値を大きくすると二乗誤差に近づき、外れ値の影響を受けやすくなります。
| 誤差の大きさ | Huber損失の扱い | 狙い |
|---|---|---|
| 閾値以内 | 二乗誤差に近い | 滑らかに学習する |
| 閾値を超える | 絶対値誤差に近い | 外れ値の影響を抑える |
Huber損失の利点

Huber損失の大きな利点は、外れ値を含むデータでも安定した学習を目指せることです。二乗誤差だけを使うと、極端に外れたデータが損失を大きく押し上げ、モデルがその少数の点に過剰に合わせようとすることがあります。
Huber損失では、誤差が大きい領域で損失の増え方を直線的にします。そのため、外れ値があっても損失への影響が限定され、全体の傾向を捉えやすくなります。
もう一つの利点は、学習のしやすさです。絶対値誤差は外れ値に強い一方で、誤差がゼロの点で微分しにくいという問題があります。Huber損失は小さい誤差の範囲で滑らかに変化するため、勾配を使った最適化と相性が良い損失関数です。
つまりHuber損失は、外れ値への頑健さと、モデルを効率よく学習させるための滑らかさを両立しやすい選択肢です。データにノイズや異常値が混ざる可能性がある回帰問題では、検討する価値があります。
| 観点 | 二乗誤差 | 絶対値誤差 | Huber損失 |
|---|---|---|---|
| 外れ値への強さ | 弱い | 強い | 強め |
| 最適化のしやすさ | しやすい | 難しい場合がある | しやすい |
| 調整要素 | 少ない | 少ない | 閾値の調整が必要 |
Huber損失の適用例

Huber損失は、外れ値やノイズが混ざる可能性のある回帰タスクでよく使われます。たとえば、センサー値、価格データ、需要予測、測定誤差を含む実験データなどでは、すべてのデータがきれいに分布しているとは限りません。
頑健な回帰分析では、外れ値の影響を抑えながら全体の傾向に合うモデルを作るためにHuber損失が役立ちます。異常検知では、通常のパターンから外れたデータを扱う場面があり、外れ値に過剰反応しすぎない損失設計が重要になります。
画像処理や信号処理でも、ノイズを含むデータを扱うことがあります。Huber損失を使うことで、細かな誤差には滑らかに対応しつつ、大きなノイズの影響を抑えやすくなります。
深層学習でも、回帰タスクやノイズに強い学習が求められる場面でHuber損失が使われます。外れ値を完全に無視するのではなく、影響を適度に抑えるという性質が、実データを扱う場面で有効です。
| 分野 | 使いどころ |
|---|---|
| 頑健な回帰分析 | 外れ値を含むデータで全体傾向を推定する |
| 異常検知 | 外れた値に過剰反応しないモデルを作る |
| 画像処理・信号処理 | ノイズの影響を抑えながら学習する |
| 深層学習 | ノイズを含む回帰タスクで安定した学習を狙う |
まとめ
Huber損失は、二乗誤差と絶対値誤差の特徴を組み合わせた損失関数です。小さい誤差では二乗誤差のように滑らかに学習し、大きい誤差では絶対値誤差のように外れ値の影響を抑えます。
外れ値が含まれる可能性のある回帰問題では、Huber損失は安定したモデルを作るための有力な選択肢です。ただし、閾値の設定によって挙動が変わるため、データの性質に合わせた調整が欠かせません。
損失関数は、モデルが何を重視して学習するかを決める重要な要素です。二乗誤差、絶対値誤差、Huber損失の違いを理解しておくと、扱うデータに合った学習方法を選びやすくなります。
| ポイント | 内容 |
|---|---|
| 小さい誤差 | 二乗誤差のように扱い、滑らかに学習する |
| 大きい誤差 | 絶対値誤差のように扱い、外れ値の影響を抑える |
| 注意点 | 閾値をデータに合わせて調整する必要がある |
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年2月1日 | 初回公開 |
| 2026年4月29日 | Huber損失の定義、損失関数の基礎、二乗誤差・絶対値誤差との違い、外れ値に強い仕組み、活用例を初心者向けに再構成 |