データドリフト:予測モデルの精度低下の要因

AIの初心者
先生、「データドリフト」ってどういう意味ですか?なんだか難しそうです。

AI専門家
そうだね、少し難しいかもしれないね。簡単に言うと、AIの学習に使ったデータと、実際にAIを使う時のデータに違いが出てきて、AIの性能が下がってしまう現象のことだよ。たとえば、ある店で人気の商品を予測するAIを作ったとしよう。学習データは夏の暑い時期のものだったのに、実際に使うのは冬の寒い時期だと、売れる商品は変わってしまうよね?これがデータドリフトだよ。
AIの初心者
なるほど、学習時と予測時でデータの傾向が変わってしまうんですね。ということは、AIの精度を保つためには、常に最新のデータで学習し直す必要があるということですか?
AI専門家
その通り!定期的に学習データを見直して、最新のデータで学習し直すことが大切だよ。そうすることで、データドリフトによるAIの性能低下を防ぐことができるんだ。
データドリフトとは。
人工知能に関わる言葉である「データドリフト」について説明します。データドリフトとは、機械学習や予測分析といった技術で使われるデータの性質が時間の経過とともに変化してしまうことを指します。データドリフトには様々な原因があり、原因別に色々な呼び方があります。主なものとしては、データの性質そのものが変わってしまう「概念ドリフト」と、データの分布や統計的な特徴が変化する「データドリフト」があります。
データドリフトとは

「データドリフト」とは、機械学習のモデルを作るために使ったデータと、実際に運用するときに使うデータの特徴がずれてしまう現象のことです。まるで川の流れの中を進むボートのように、時間の流れとともにデータの特性も変化していくため、こうしたずれが生じます。
たとえば、ある商品の売れ行きを予想するモデルを作るとします。モデルを作る時は夏のデータを中心に使いました。しかし、実際にこのモデルを使い始めるのが冬だったとしましょう。夏は暑いため、冷たい飲み物がよく売れます。一方で、冬は温かい飲み物の需要が高まります。このように季節によって商品の売れ行きは大きく変わるため、夏のデータで作ったモデルは冬の売れ行きを正確に予想できません。これがデータドリフトの一例です。
データドリフトは、社会の変化や周りの環境の変化、利用者の行動の変化など、様々な要因で起こります。例えば、新しい技術が登場したり、流行が変わったり、法律が変わったりすることで、データの特性が変化することがあります。また、サービスの利用者が増えたり、利用者の年齢層が変わったりするなど、利用者の行動が変化することもデータドリフトの原因となります。
データドリフトが発生すると、せっかく作ったモデルの予想精度が下がり、役に立たなくなってしまうことがあります。これはまるで、地図が古くなってしまって目的地にたどり着けなくなるようなものです。そのため、データドリフトを早期に発見し、適切な対策を講じることが重要です。対策としては、モデルを定期的に新しいデータで学習し直したり、ドリフトを検知する仕組みを導入したりするなどの方法があります。常に変化するデータの流れに適応していくことで、精度の高い予測を維持することができます。
| 項目 | 説明 | 例 |
|---|---|---|
| データドリフトの定義 | 機械学習モデルの学習データと運用データの特徴のずれ | 夏のデータで学習したモデルを冬に運用 |
| データドリフト発生要因 | 社会の変化、環境の変化、利用者の行動の変化など | 新技術の登場、流行の変化、法律の変更、利用者数の増加、利用者年齢層の変化 |
| データドリフトの影響 | モデルの予測精度低下 | 古い地図で目的地にたどり着けない |
| データドリフト対策 | モデルの定期的な再学習、ドリフト検知仕組みの導入 | – |
概念ドリフトとの違い

「情報のずれ」と「概念のずれ」は似て非なるものですが、混同しやすいものです。どちらも機械学習の予測精度を落とす原因となり、適切な対処が必要です。そこで、この二つの違いについて詳しく説明します。
まず、「情報のずれ」とは、学習に使ったデータの特徴と、実際に予測に使うデータの特徴が異なることを指します。たとえば、ある店で人気の商品を予測する機械学習モデルを作ったとします。モデルを作る際に夏場のデータばかりを使った場合、冬場の商品の予測精度が下がる可能性があります。これは、夏に人気がある商品と冬に人気がある商品が違うためです。このように、データそのものの特徴が変化することで予測精度が下がる現象が「情報のずれ」です。
一方、「概念のずれ」とは、予測したい事柄そのものの関係性が変化することを指します。同じく商品の予測モデルを例に挙げると、ある商品が急に売れなくなったとしましょう。これは「概念のずれ」にあたります。この場合、売れ行きが悪くなった原因は様々考えられます。例えば、似たような商品が他のお店で安く売られるようになった、消費者の好みが変わった、などです。このように、データそのものの特徴は変わっていなくても、予測したい事柄の周りの状況が変化することで、予測精度が下がる現象が「概念のずれ」です。
このように、「情報のずれ」は入力データの変化に着目するのに対し、「概念のずれ」は予測対象そのものの変化に着目します。どちらも機械学習モデルの精度を低下させる要因となりますが、その発生原因と対策は異なります。両者を正しく見分けることで、適切な対処が可能になり、より精度の高い予測結果を得ることができるようになります。
| 項目 | 情報のずれ | 概念のずれ |
|---|---|---|
| 定義 | 学習データと予測データの特徴の差異 | 予測対象事柄の関係性の変化 |
| 例 | 夏場のデータで学習したモデルで冬場の商品を予測 | 急に売れ行きが悪くなった商品を予測 |
| 原因 | データそのものの特徴の変化 | データの特徴は変わらず、予測対象の周りの状況が変化 |
| 着目点 | 入力データの変化 | 予測対象そのものの変化 |
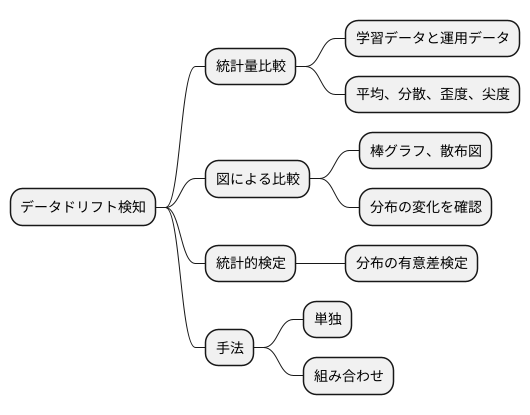
データドリフトの検知方法

機械学習のモデルは、過去のデータに基づいて学習されます。しかし、時間の経過とともにデータの性質が変化することがあります。これをデータドリフトと呼びます。データドリフトが発生すると、モデルの精度が低下する可能性があります。ですから、データドリフトを素早く見つけることは、モデルの性能を維持するために非常に大切です。
データドリフトを見つけるには、いくつかの方法があります。まず、学習に使ったデータと、実際に運用しているシステムで集めたデータの統計的な特徴を比べる方法です。具体的には、平均や分散、データの歪み具合や尖り具合といった数値を計算し、それらの変化を調べます。もしこれらの数値に大きな違いがあれば、データドリフトが発生している可能性があります。
また、図を使ってデータの分布を視覚的に比べることも有効です。例えば、棒グラフや散布図を使うことで、データ全体の傾向や変化を捉えやすくなります。これらの図から、データの分布に変化がないか、例えば山が横にずれていたり、形が変わっていないかを確認します。
さらに、統計的な検定を行うという方法もあります。これは、学習データと運用データの分布に本当に意味のある差があるのかを、統計的な手法を用いて厳密に確かめる方法です。
これらの方法は、それぞれ単独で使うこともできますし、組み合わせて使うこともできます。複数の方法を組み合わせることで、より確実にデータドリフトを検知することができます。データドリフトを早期に発見し、適切な対策を講じることで、機械学習モデルの性能を維持し、より良い結果を得ることが可能になります。
データドリフトへの対策

機械学習モデルは、時間の経過と共に予測精度が低下することがあります。これは、モデルの学習に使用したデータと運用中のデータの特性が変化してしまうことが原因で、この現象をデータドリフトと呼びます。データドリフトに対処するためには、いくつかの対策を講じることが重要です。
まず、定期的にモデルを再学習することが効果的です。現実世界で得られた新しいデータを用いてモデルを学習し直すことで、変化したデータの特性をモデルに取り込むことができます。再学習の頻度は、データの変化の速さやモデルの性能への影響度合いを考慮して決定する必要があります。たとえば、変化の激しいデータの場合は、短い間隔で再学習を行うことが望ましいでしょう。
また、データの前処理や特徴量の作り方を工夫することでも、データドリフトの影響を減らすことができます。例えば、ある時期に特有のデータの場合、その時期特有の変動を考慮した特徴量を作成することで、モデルの精度を維持することができます。これは、季節による売上の変動を予測するモデルなどで有効な手法です。
さらに、データの変化にリアルタイムで対応できるような仕組みを導入することも有効です。例えば、オンライン学習という手法を用いることで、常に最新のデータを取り込みながらモデルを更新していくことが可能になります。これにより、データドリフトによる予測精度の低下を最小限に抑えることができます。
これらの対策を組み合わせることで、データドリフトによる悪影響を軽減し、機械学習モデルの長期的な安定運用を実現できるでしょう。どの対策が最も効果的かは、データの特性やビジネスの要件によって異なるため、状況に応じて適切な方法を選択することが重要です。
| 対策 | 説明 | 備考 |
|---|---|---|
| 定期的なモデルの再学習 | 現実世界で得られた新しいデータを用いてモデルを学習し直すことで、変化したデータの特性をモデルに取り込む。 | 再学習の頻度は、データの変化の速さやモデルの性能への影響度合いを考慮して決定する。変化の激しいデータの場合は、短い間隔で再学習を行う。 |
| データの前処理や特徴量の作り方を工夫する | ある時期に特有のデータの場合、その時期特有の変動を考慮した特徴量を作成することで、モデルの精度を維持する。 | 季節による売上の変動を予測するモデルなどで有効。 |
| データの変化にリアルタイムで対応できる仕組みを導入する | オンライン学習という手法を用いることで、常に最新のデータを取り込みながらモデルを更新していく。 | データドリフトによる予測精度の低下を最小限に抑える。 |
監視の重要性

常に変化する情報の海を航海する現代社会において、見張りをすることは必要不可欠です。これは、まるで荒波の海を進む船が、羅針盤や灯台、そして見張りの目によって安全な航路を確保するのと同じです。データの波に乗る人工知能にとっても、監視はまさに羅針盤や灯台の役割を果たします。
データは常に変化し続ける生き物のようなものです。季節の移ろい、流行の変化、社会情勢の変動など、様々な要因によってデータの性質は刻一刻と変化します。この変化を「データドリフト」と呼びます。データドリフトは、まるで海流の変化のように、人工知能の精度を狂わせ、思わぬ座礁を招く可能性があります。
だからこそ、絶え間ない監視が重要になります。訓練された人工知能モデルの予測精度やデータの統計量を定期的に観察することで、データドリフトの兆候を早期に発見できます。これは、まるで船の見張りが遠くの嵐雲を見つけるように、危険を予知することに繋がります。そして、早期発見は迅速な対応を可能にします。
監視体制の構築も重要です。データドリフト発生時に自動的に警告を発する仕組みを導入することで、まるで船の警報装置のように、問題発生を即座に関係者に知らせ、迅速な対応を促すことができます。これは、嵐に遭遇した際に、迅速に帆を調整し、船の向きを変えることと同じくらい重要です。
絶え間ない監視と迅速な対応は、データドリフトによる人工知能の精度低下を最小限に抑えるための重要な鍵となります。変化の激しいデータの海を安全に航海するためには、常に周囲の状況を把握し、適切な行動をとることが必要不可欠です。これこそが、人工知能の価値を最大限に引き出し、社会に貢献するための礎となるのです。
| 概念 | 説明 | 航海における例え |
|---|---|---|
| 情報の海を航海する | 常に変化する情報に対応することの重要性 | 荒波の海を進む船 |
| AIにおける監視 | データの変化を捉え、AIの精度を維持するために不可欠 | 羅針盤や灯台、見張りの目 |
| データドリフト | データの性質が時間とともに変化する現象 | 海流の変化 |
| 絶え間ない監視 | データドリフトの兆候を早期発見するために重要 | 見張りが遠くの嵐雲を見つける |
| 監視体制の構築 | データドリフト発生時に自動的に警告を発する仕組み | 船の警報装置 |
| 迅速な対応 | データドリフトによるAIの精度低下を最小限に抑えるために重要 | 嵐に遭遇した際に、帆を調整し船の向きを変える |