
標準化とは?正規化との違いと機械学習での使い方を解説

AIの初心者
「標準化」って、何のことですか?データを整える処理だと聞いたのですが、まだよく分かりません。

AI専門家
標準化は、単位や大きさが違うデータを比べやすくするための前処理だよ。例えば100点満点の国語と50点満点の算数を、そのまま点数だけで比べると判断しにくいよね。
AIの初心者
たしかに、同じ40点でも満点が違えば意味が変わりますね。
AI専門家
その通り。標準化では平均を0、ばらつきの尺度を1にそろえることで、データが平均からどれくらい離れているかを同じ基準で見られるようにするんだ。
標準化とは。
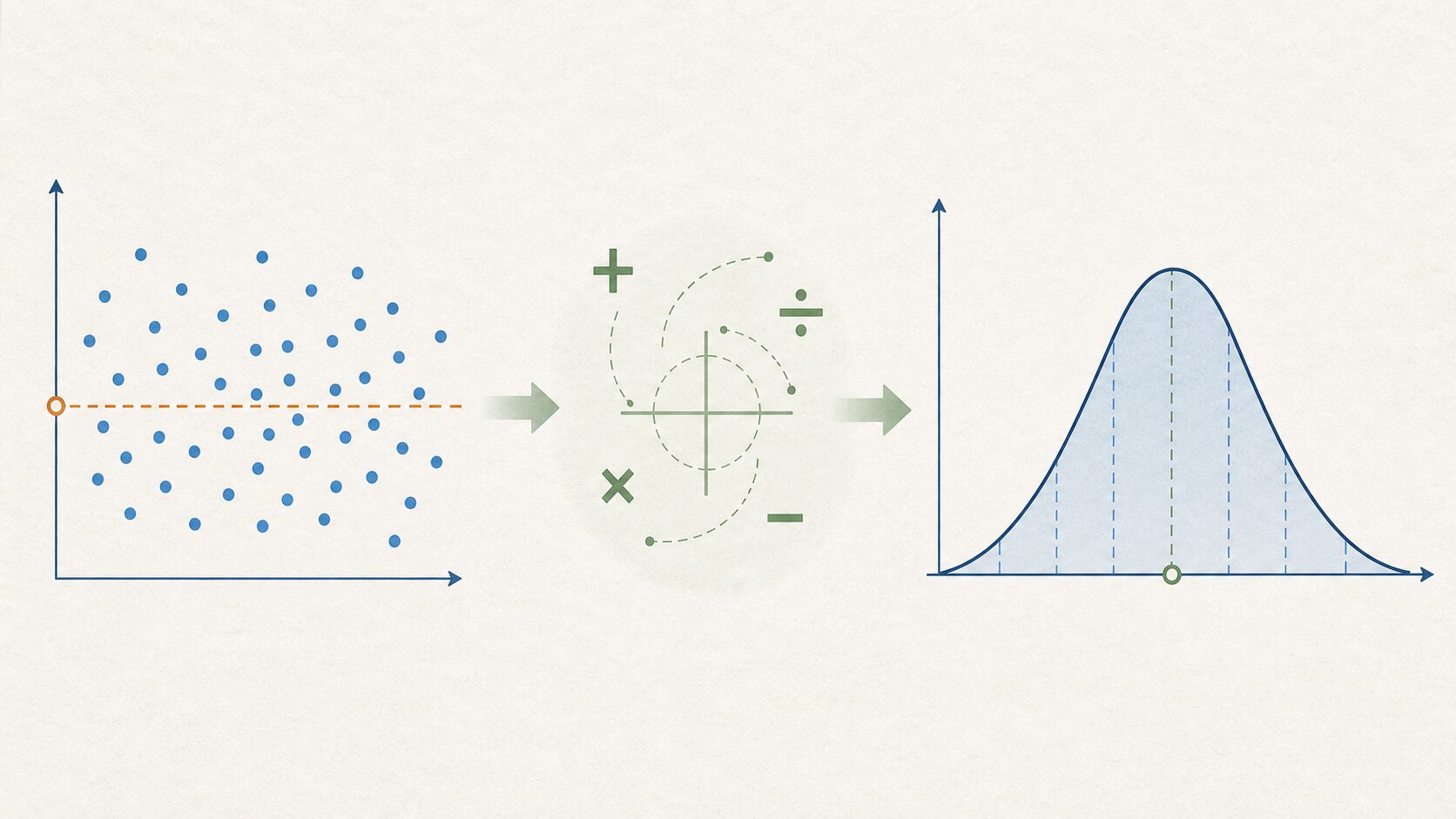
標準化は、AIや統計、データ分析でよく使われる前処理の一つです。値の単位や桁が異なるデータを同じ基準に変換し、比較や機械学習に使いやすい状態へ整えます。特に、複数の特徴量を同時に扱う場面では、標準化を理解しておくとモデルの挙動や分析結果を読み取りやすくなります。

標準化とは何か
標準化とは、データの平均を0、標準偏差を1にそろえる変換です。平均より大きい値は正の値、平均より小さい値は負の値になり、値が平均からどれくらい離れているかを同じ尺度で表せます。標準偏差を1にするため、結果として分散も1になります。
例えば、身長はセンチメートル、体重はキログラム、テスト点は点数というように、現実のデータは単位も範囲もばらばらです。そのまま機械学習に入れると、数値の大きい特徴量が強く見えすぎることがあります。そこで、標準化によって各特徴量を平均からの相対的な位置で表すと、単位の違いに引っ張られにくくなります。
標準化は、データが平均の周りに分布しているときに特に使いやすい方法です。正規分布のような左右対称の分布では解釈しやすく、統計学で使われる標準得点やZスコアの考え方ともつながっています。
標準化の計算式と手順

標準化では、各データから平均を引き、その結果を標準偏差で割ります。式で書くと、次のようになります。
\(z = \frac{x – \mu}{\sigma}\)ここで、x は元の値、μ は平均、σ は標準偏差、z は標準化後の値です。平均を引くことで中心を0へ移動し、標準偏差で割ることでばらつきの尺度を1にそろえます。
手順は大きく3つです。まず対象データの平均を計算します。次に標準偏差を計算します。最後に、それぞれの値から平均を引いて標準偏差で割ります。例えば平均点が60点、標準偏差が10点のテストで80点を取った場合、標準化後の値は2です。これは「平均より標準偏差2個分高い位置にある」と読めます。
このように標準化後の値は、元の単位ではなく平均との差を表す値です。点数、身長、売上額のように単位が違っても、標準化後は「平均からどれくらい離れているか」という共通した見方ができます。
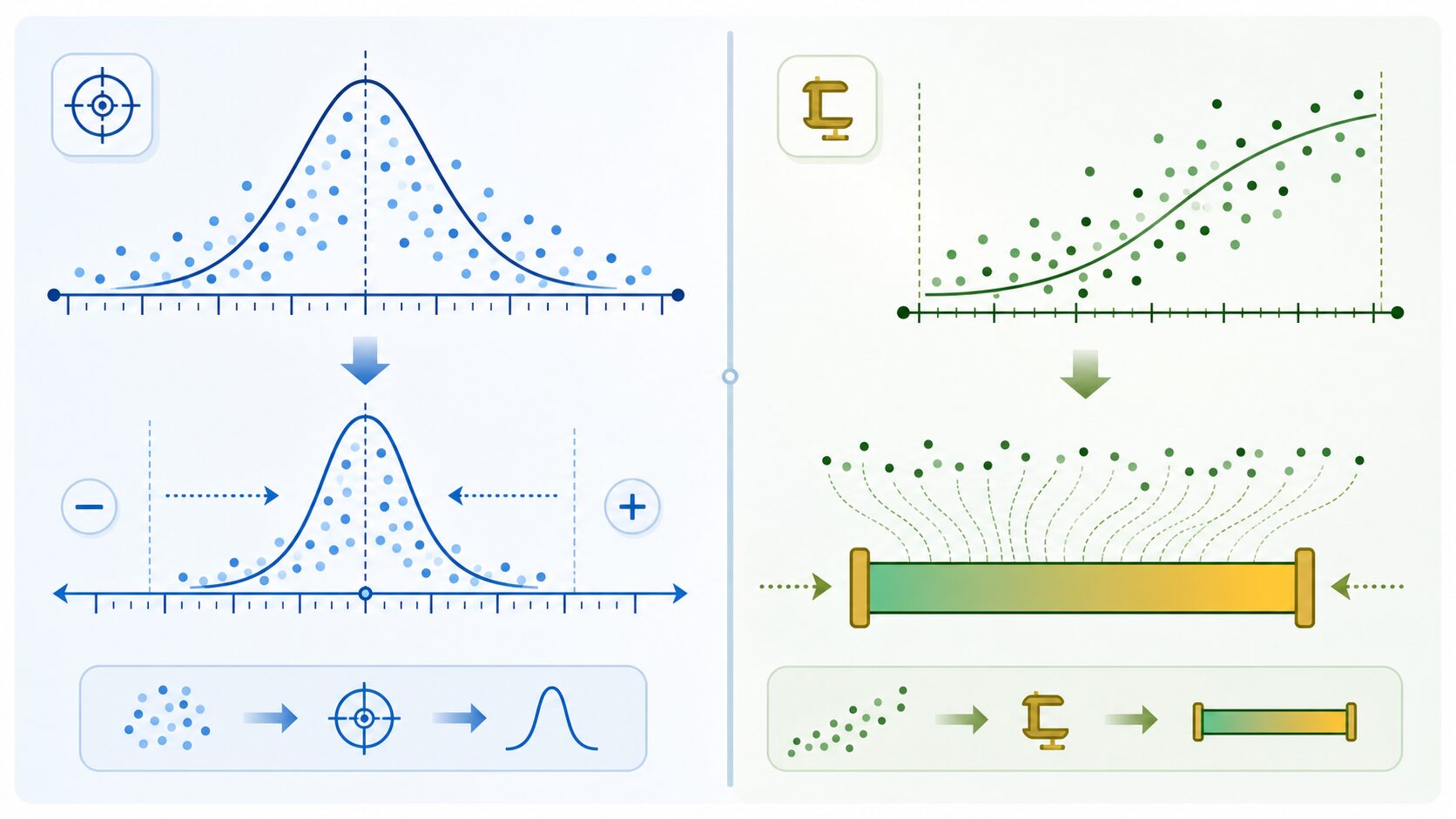
標準化と正規化の違い
標準化とよく混同される言葉に正規化があります。どちらもデータの尺度を調整する前処理ですが、そろえる基準が異なります。標準化は平均と標準偏差を使い、データが分布の中でどの位置にあるかを表します。一方、正規化は最小値と最大値を使い、値を0から1などの範囲に収める処理です。
| 手法 | 主な目的 | 変換後の目安 | 外れ値の影響 |
|---|---|---|---|
| 標準化 | 平均からの離れ具合を同じ尺度で見る | 平均0、標準偏差1 | 正規化よりは受けにくいが、極端な値には注意が必要 |
| 正規化 | 値の範囲を一定に収める | 0から1など | 最大値・最小値が外れ値だと大きく影響を受ける |
例えば、画像の画素値のように取りうる範囲が決まっているデータでは正規化が使いやすい場合があります。一方、身長、体重、売上、検査値など、平均からのずれを見たいデータでは標準化が向いています。範囲をそろえたいのか、分布上の位置をそろえたいのかで使い分けると判断しやすくなります。
標準化が機械学習で重要な理由
機械学習では、特徴量ごとの尺度が大きく違うと、モデルが一部の特徴量を過大に扱ってしまうことがあります。例えば、年齢が0から100程度、年収が数百万円単位で表されている場合、数値の大きさだけを見ると年収の影響が強く見えます。しかし、モデルにとって重要なのは単位の大きさではなく、予測に役立つ変化です。
標準化が特に効きやすいのは、距離や勾配を使う手法です。k近傍法、サポートベクターマシン、ロジスティック回帰、ニューラルネットワーク、主成分分析などでは、特徴量の尺度が結果や学習速度に影響します。勾配降下法では、尺度がそろっているほうが最適な値へ進みやすく、学習が安定しやすくなります。
一方で、決定木、ランダムフォレスト、勾配ブースティング木のような木構造ベースの手法では、標準化の効果が小さいこともあります。すべての場面で機械的に標準化すればよいわけではなく、使うモデルとデータの性質に合わせて判断することが大切です。
標準化の適用例
標準化は、AIのためだけの処理ではありません。医療、金融、製造など、異なる条件で測定された値を比較したい場面で広く使われます。
| 分野 | 標準化する対象 | 役立つ理由 |
|---|---|---|
| 医療 | 血液検査値、身体測定値など | 年齢や性別による差を考慮し、基準からのずれを評価しやすくする |
| 金融 | 株価、為替、収益率、リスク指標など | 異なる銘柄や期間の値動きを比較しやすくする |
| 製造 | 寸法、重量、性能、検査値など | 品質のばらつきを把握し、異常や改善点を見つけやすくする |
| 機械学習 | 複数の特徴量 | 単位や桁の違いによる偏りを抑え、学習を安定させる |
例えば医療検査では、同じ検査値でも年齢や性別によって解釈が変わることがあります。金融では価格そのものより、通常の変動幅からどれくらい離れているかを見たい場面があります。製造では、寸法や重さのばらつきを同じ基準で見れば、品質管理の判断がしやすくなります。
標準化するときの注意点
標準化では、平均と標準偏差を使うため、外れ値が多いデータでは結果がゆがむことがあります。正規化ほど最大値・最小値に直接引っ張られるわけではありませんが、極端に大きい値や小さい値がある場合は、外れ値の確認やロバストなスケーリングを検討します。
機械学習では、訓練データで計算した平均と標準偏差を、検証データやテストデータにも使うことが重要です。データ全体を先に標準化してから訓練と評価に分けると、評価用データの情報が訓練側に漏れる可能性があります。これはデータリークと呼ばれ、モデルの性能を実際より高く見せてしまいます。
また、標準化後の値は元の単位を失います。解釈するときは「何センチ」「何円」ではなく、「平均から標準偏差何個分離れているか」と読む必要があります。分析結果を人に説明する場合は、必要に応じて元の単位での意味も補足すると伝わりやすくなります。
標準化の学び方
標準化を学ぶときは、まず平均、分散、標準偏差の意味を押さえると理解が早くなります。式を暗記するよりも、「平均を引くと中心が0になる」「標準偏差で割るとばらつきの尺度がそろう」という流れで考えると、処理の目的が見えやすくなります。
次に、小さな表データを使って手計算してみるのがおすすめです。3人から5人分の点数や身長を用意し、平均、標準偏差、標準化後の値を順に計算すると、正の値と負の値の意味がつかめます。そのうえでPythonのライブラリを使えば、大量のデータを同じ考え方で処理できることが分かります。
Pythonでは、機械学習ライブラリの前処理機能を使って標準化を実行できます。ただし、使い方だけを覚えるのではなく、訓練データで基準を計算し、検証データには同じ基準を適用するという考え方までセットで理解しておくと、実務や学習でのミスを減らせます。
まとめ
標準化は、データの平均を0、標準偏差を1にそろえ、異なる単位や大きさのデータを比較しやすくする前処理です。機械学習では、距離計算や勾配を使うモデルの学習を安定させるために役立ちます。
正規化との違いは、標準化が平均からの離れ具合をそろえるのに対し、正規化は値の範囲をそろえる点です。どちらを使うかは、データの性質、外れ値の有無、使うモデル、分析の目的によって変わります。まずは式の意味と具体例を理解し、小さなデータで手を動かして確認すると、標準化の役割を実感しやすくなります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2025年1月31日 | 初回公開 |
| 2026年5月16日 | 計算式、正規化との差、機械学習での扱いを追記 |