事前学習:巨大言語モデルの土台

AIの初心者
先生、「事前学習」って一体何ですか?難しそうでよくわからないです。

AI専門家
そうだね、難しく感じるかもしれないね。簡単に言うと、AIに言葉を教えるための最初のステップだよ。たくさんの文章を読ませて、言葉の意味や使い方を覚えさせるんだ。人間でいうと、たくさんの本を読んで言葉を覚えるようなものだね。
AIの初心者
なるほど、たくさんの本を読ませるんですね。でも、ただ読ませるだけでAIは言葉を理解できるようになるんですか?
AI専門家
いい質問だね!ただ読ませるだけではないんだ。例えば、「私の好きな果物は□です」という文章を読ませたとしよう。AIはたくさんの文章から「□」には「りんご」や「みかん」などの果物の名前が入ることを学ぶんだ。そうやって、言葉の使い方や関係性をAIが自分で見つけていくんだよ。
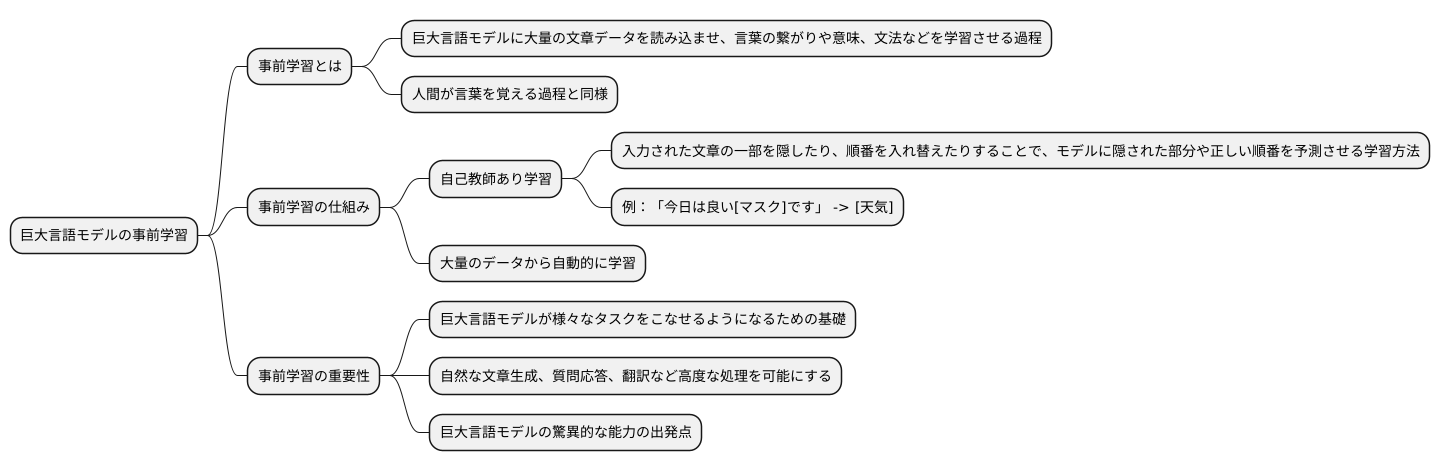
事前学習とは。
「人工知能」に関する言葉である「事前学習」について説明します。「事前学習」とは、機械学習モデルに言葉の基本的な使い方やたくさんの言葉、色々な知識を覚えさせるための最初の段階のことです。まるで人間が言葉を覚える前の段階で、色々な知識を詰め込むようなものです。この学習では、人間が言葉を覚えるときと同じように、膨大な量の文章データを使って行います。具体的には、まずデータをたくさん集め、次にそのデータを機械が理解できるように整理し、最後に文章中の言葉を予測する練習を繰り返すことで、モデルに言葉を覚えさせます。
はじめに

近ごろ、急速に発展している人工知能の分野で、巨大言語モデル(言語を扱うとても大きな人工知能)が大きな関心を集めています。まるで人間が書いたかのような自然な文章を作ったり、難しい質問に答えたりする能力は、私たちの暮らしや社会を大きく変える可能性を秘めていると言えるでしょう。この巨大言語モデルの驚くべき能力の土台となっているのが「事前学習」と呼ばれる過程です。この文章では、事前学習とは一体どのようなものなのか、その仕組みや大切さについて詳しく説明していきます。
事前学習とは、巨大言語モデルに大量の文章データを読み込ませ、言葉の繋がりや意味、文法などを学習させる過程のことです。人間が言葉を覚えるのと同じように、巨大言語モデルも膨大な量の文章データに触れることで、言葉の規則性やパターンを学習していきます。この学習を通して、単語の意味や文脈を理解し、自然で意味の通る文章を生成する能力を身につけるのです。まるで、赤ちゃんが周囲の言葉を聞いて言葉を覚えていく過程と似ています。
事前学習の方法はいくつかありますが、代表的なものに「自己教師あり学習」というものがあります。これは、入力された文章の一部を隠したり、順番を入れ替えたりすることで、モデルに隠された部分や正しい順番を予測させるという学習方法です。例えば、「今日は良い[マスク]です」という文章から[マスク]の部分を予測させることで、モデルは文脈から「天気」という言葉が当てはまることを学習します。このようにして、大量のデータから自動的に学習していくのです。事前学習は、巨大言語モデルが様々なタスクをこなせるようになるための基礎となる重要な段階と言えます。この事前学習をしっかりと行うことで、人間のように自然な文章を生成したり、質問に答えたり、翻訳したりといった高度な処理をこなせるようになるのです。まさに、巨大言語モデルの驚異的な能力の出発点と言えるでしょう。
事前学習の仕組み

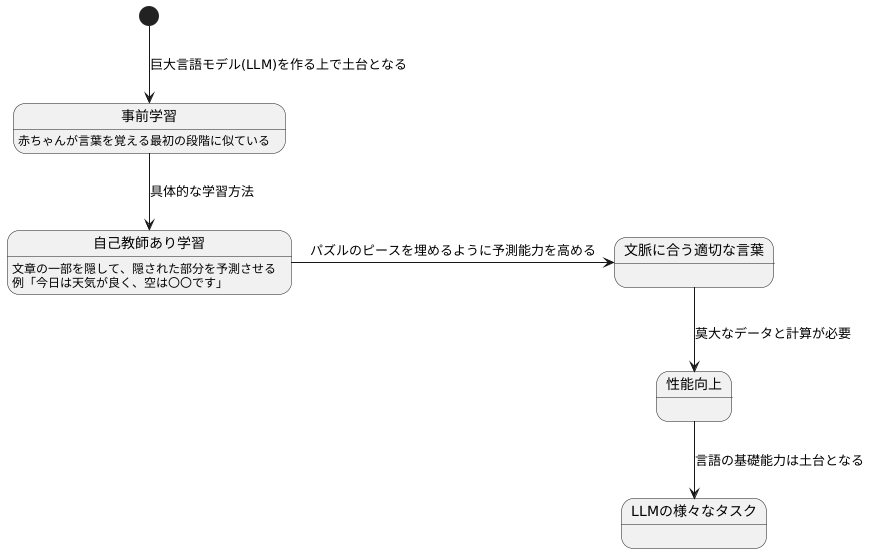
巨大言語モデル(LLM)を作る上で、事前学習は土台となる大切な工程です。これは、生まれたばかりの赤ちゃんに言葉を教える最初の段階に似ています。赤ちゃんは、絵本を読んでもらったり、周りの人の言葉を聞いたりする中で、言葉の響きやリズムに慣れていきます。この段階では、言葉を話す、文章を作るといった高度なことは求めません。同様に、事前学習の段階では、特定の作業をこなすことは目的としていません。膨大な量の文章データを読み込ませることで、言葉の意味や文の繋がり、世の中の知識などをLLMに吸収させることが重要となります。
具体的には、自己教師あり学習と呼ばれる方法で学習を進めます。これは、文章の一部を隠して、隠された部分が何であるかを予測させるという訓練です。例えば、「今日は天気が良く、空は〇〇です」という文章の「〇〇」の部分を予測させることで、前後の文脈に合った適切な言葉を選ぶ能力を育てます。「青い」や「澄んでいる」といった言葉が適切でしょう。「赤い」や「曇っている」といった言葉は文脈に合わないため、選ばれないように学習していきます。このようにして、膨大なデータから言葉の関連性や使われ方を学習していきます。まるで、パズルのピースを埋めるように、文脈に合う適切な言葉を予測する能力を高めていくのです。この学習には、莫大な量のデータと計算が必要となるため、多くの費用と時間がかかります。しかし、この事前学習が、その後のLLMの性能向上に大きく貢献するのです。事前学習によって培われた言語の基礎能力は、LLMが様々なタスクをこなすための土台となります。
事前学習のステップ

言葉の学習を機械に行わせる事前学習は、大きく三つの段階に分けて行われます。まず第一段階として、インターネット上にある様々な種類の文章、例えばニュース記事やブログ、電子書籍などから、膨大な量の言葉のデータを集めます。集めるデータが多ければ多いほど、後の学習の効果が高まります。まるで人間が多くの本を読むことで知識を深めるように、機械も多くのデータに触れることで言葉を深く理解できるようになるのです。
第二段階では、集めたデータを機械が学習しやすい形に整えます。これは、料理で例えるなら、食材を洗ったり切ったり下ごしらえをするようなものです。不要な記号や記号の重複を取り除き、文章を単語ごとに区切ります。また、同じ意味を持つ言葉は一つにまとめたり、あまりに珍しい言葉は除外したりします。このようにデータを整理することで、機械が効率的に学習できるように準備を整えます。
最後の第三段階では、前段階で整えられたデータを使って、実際に機械に言葉を学習させます。具体的には、ある単語の前後の単語から、その単語を予測する訓練を行います。例えば、「空が青い」という文章であれば、「空が」という部分から「青い」という単語を予測させます。この訓練を何度も繰り返すことで、機械は単語同士の関係性や、どの単語がどのくらいの頻度で使われるのかを学習します。大量のデータで訓練することで、機械は言葉の繋がりや意味を理解し、より自然で正確な文章を作れるようになります。これは、人間が多くの文章を読むことで語彙や表現力を豊かにするのと似ています。このように、三つの段階を経て事前学習は完了し、人間のように言葉を操る機械の土台が築かれます。
| 段階 | 内容 | 例え |
|---|---|---|
| 第一段階 | インターネット上の様々な種類の文章から膨大な量の言葉のデータを集める。データが多ければ多いほど、後の学習の効果が高まる。 | 人間が多くの本を読むことで知識を深める |
| 第二段階 | 集めたデータを機械が学習しやすい形に整える。不要な記号や記号の重複を取り除き、文章を単語ごとに区切り、同じ意味を持つ言葉は一つにまとめ、珍しい言葉は除外する。 | 料理で食材を洗ったり切ったり下ごしらえをする |
| 第三段階 | 整えられたデータを使って、機械に言葉を学習させる。ある単語の前後の単語から、その単語を予測する訓練を何度も繰り返すことで、単語同士の関係性や単語の出現頻度を学習する。 | 人間が多くの文章を読むことで語彙や表現力を豊かにする |
データ収集の重要性

近年の言葉に関する人工知能の進歩は目覚ましく、その背景には質の高い情報の集め方の向上が大きく関わっています。まるで人間の子供のように、人工知能もたくさんの言葉に触れることで言葉を理解し、使いこなせるようになっていきます。この学習の成否を左右するのが、集めた言葉の質と量です。
質の高い言葉のデータとは、まず文法的に正しいことが重要です。でたらめな言葉では、人工知能は正しい言葉の使い方を学ぶことができません。また、多様な表現が含まれていることも大切です。決まりきった言葉だけでなく、様々な言い回しや表現に触れることで、人工知能はより柔軟に言葉を扱えるようになります。もし、偏った言葉や間違った情報ばかりを集めて学習させてしまうと、人工知能は間違ったことを覚えてしまい、その能力を十分に発揮できなくなってしまいます。
言葉のデータは量も重要です。人間と同じように、人工知能もたくさんの言葉に触れるほど、多くのことを学ぶことができます。例えば、数千億、数兆といった膨大な量の言葉を学習させることで、人工知能は人間のように複雑な言葉のやり取りを理解し、自然な文章を作り出せるようになります。まるで、図書館にある数え切れないほどの書物を読破することで、豊富な知識を身につける学者のように、人工知能も大量のデータを学習することで高度な言語能力を身につけます。このように、大規模な言葉のデータこそが、高性能な人工知能を支える重要な要素と言えるでしょう。

事前学習とファインチューニング

巨大言語モデル(大規模言語モデル)を作る上で、事前学習とファインチューニングはどちらも欠かせない工程です。これらは、高性能な車を作る工程に例えることができます。まず、事前学習は車体を作ることに相当します。膨大なテキストデータを学習させることで、言語の基礎的な構造や意味、文法などをモデルに理解させます。この段階では、まだ特定の用途は決まっていません。いわば、どんな車にもなりうる基本的な車台が完成する段階です。しかし、車体だけでは車は走りません。翻訳や要約、質問応答といった特定の作業をさせるためには、目的に合わせたエンジンや内装が必要です。これがファインチューニングに相当します。
ファインチューニングでは、特定の作業に特化したデータを使って、モデルをさらに学習させます。例えば、翻訳モデルを作りたい場合は、大量の対訳データを使ってモデルを調整します。要約モデルを作りたい場合は、元となる文章と要約文のペアデータを使って学習させます。このように、ファインチューニングは、事前学習で作った土台となるモデルを、特定の目的に合わせてカスタマイズする作業と言えるでしょう。具体的な作業内容に合わせて、モデル内部のパラメータを細かく調整することで、その作業に最適化されたモデルを作り上げます。
事前学習によって言語の基礎を理解したモデルは、ファインチューニングによって特定の作業に特化することで、高い性能を発揮できるようになります。これは、しっかりと作られた車体に、高性能なエンジンを搭載することで、初めて車が本来の性能を発揮できるようになるのと似ています。事前学習とファインチューニング、この二つの工程を組み合わせることで、高性能な巨大言語モデルが完成するのです。そして、様々な作業に特化したモデルが開発され、私たちの生活をより便利で豊かにしてくれることが期待されています。
まとめ

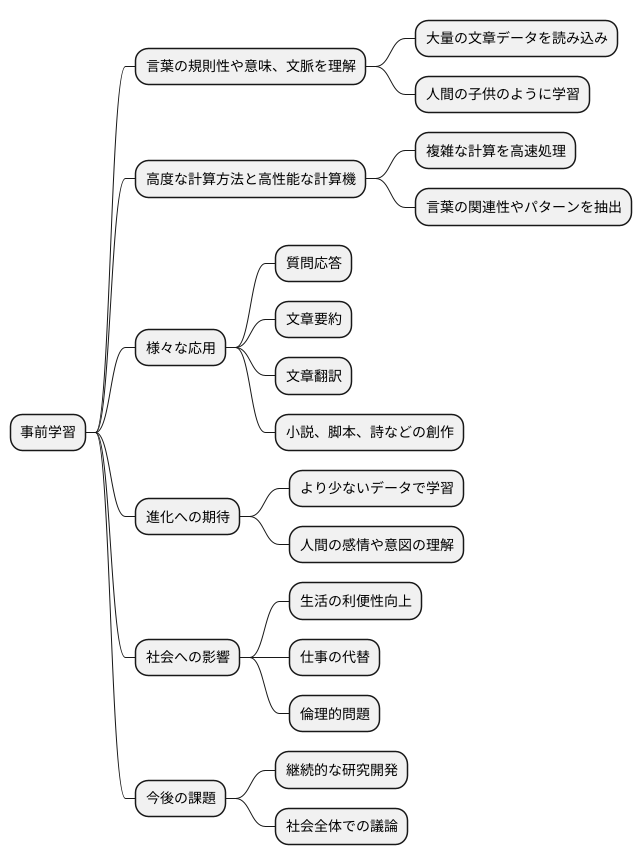
近年の言葉や文章を扱う人工知能技術の進歩は目覚ましく、中でも事前学習という手法は、その性能を大きく左右する重要な要素となっています。この手法は、まるで人間の子供のように、大量の文章データを読み込むことで言葉の規則性や意味、そして文脈を理解する能力を人工知能に与えるものです。膨大なデータを読み込ませることで、人工知能は言葉の繋がりや使われ方のパターンを学習し、あたかも人間が書いたかのような自然で滑らかな文章を作り出せるようになります。
この事前学習を支えているのが、高度な計算方法と、それを処理できる高性能な計算機です。複雑な計算を高速で行うことで、膨大なデータの中から言葉の関連性やパターンを効率的に抽出することが可能になります。そして、学習した知識を基に、様々な応用が可能になります。例えば、質問に答えたり、文章を要約したり、文章を翻訳したり、更には小説や脚本、詩などの創作活動も可能になります。
事前学習は、人工知能が言葉を扱う能力を飛躍的に向上させ、様々な分野での応用を可能にする画期的な手法です。今後、更に研究開発が進むことで、より高度な事前学習手法が確立され、人工知能は更なる進化を遂げることが期待されます。例えば、より少ないデータで効率的に学習できるようになったり、人間の感情や意図をより深く理解できるようになるかもしれません。
人工知能の発展は、私たちの社会に大きな変革をもたらす可能性を秘めています。様々な作業を自動化することで、私たちの生活はより便利で豊かになるでしょう。しかし、同時に、人工知能が人間の仕事を奪ったり、倫理的な問題を引き起こす可能性も懸念されています。だからこそ、私たちは人工知能の進化を注意深く見守り、その恩恵を最大限に活用しつつ、潜在的なリスクにも適切に対処していく必要があるでしょう。人工知能と人間が共存し、より良い社会を築いていくためには、継続的な研究開発と、社会全体での議論が不可欠です。