MLOpsとは?機械学習モデルを継続運用する仕組みと導入手順

AIの初心者
MLOpsとは何ですか?機械学習の勉強をしていると出てきますが、モデルを作る話なのか、システム運用の話なのか分かりません。

AI専門家
MLOpsは、機械学習モデルを作って終わりにせず、業務の中で安全に配備し、監視し、必要に応じて改善し続けるための考え方と仕組みです。
AIの初心者
モデルの精度が高ければ、それで十分ではないのですか?
AI専門家
精度は重要ですが、本番環境ではデータの変化、障害、説明責任、再学習、セキュリティ、担当者間の連携も必要です。この記事では、MLOpsの基本から導入の考え方まで順番に整理します。
MLOpsとは。
MLOpsとは、Machine Learning Operationsの略で、機械学習モデルの開発、検証、配備、監視、再学習、改善を継続的に回すための実務上の仕組みです。モデルを一度作るだけでなく、データや業務環境が変化しても使い続けられるように、開発プロセスと運用プロセスをつなぐ考え方を指します。
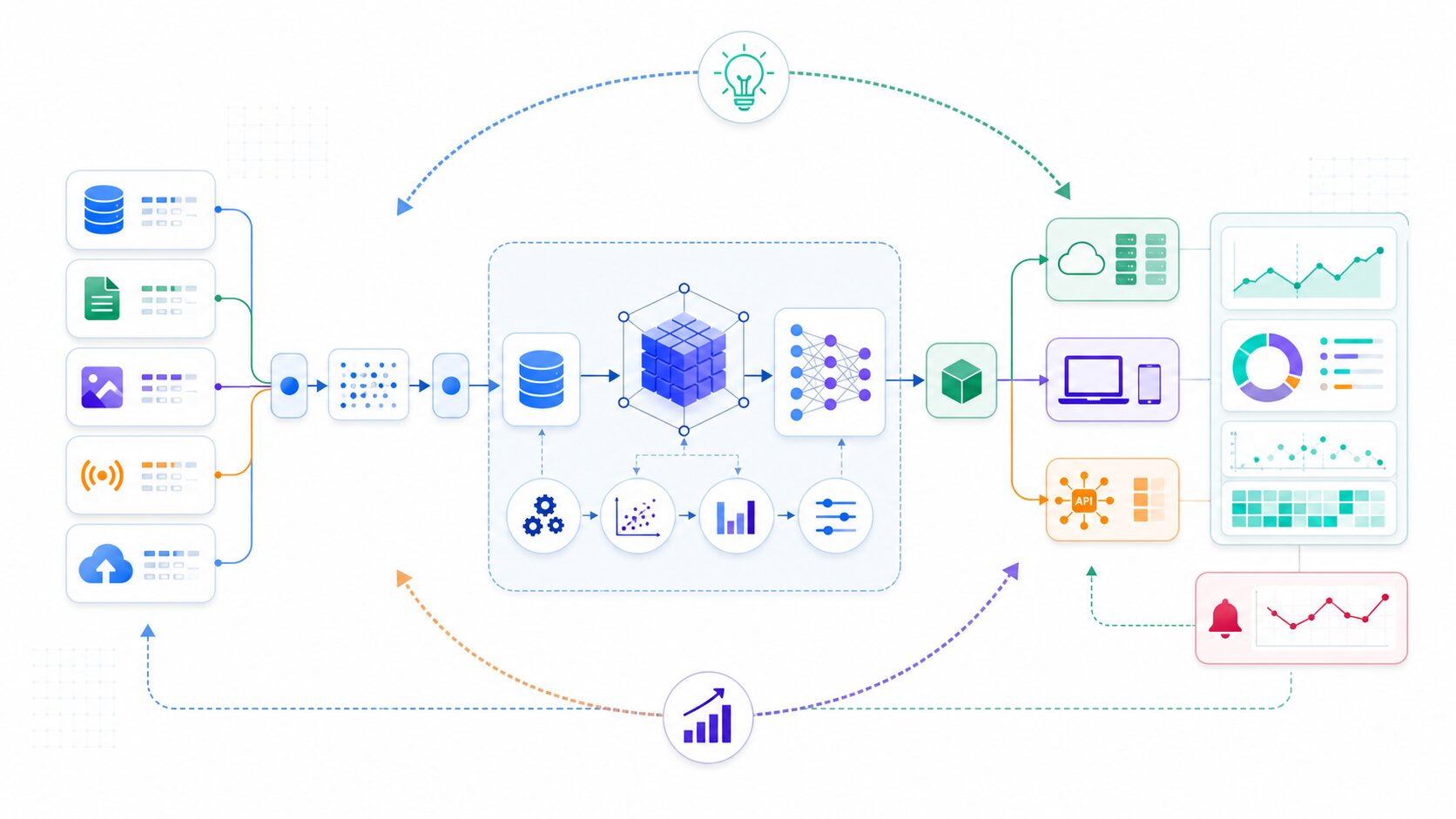
MLOpsを理解するときに大切なのは、AIを「学習済みモデル」という単体の成果物だけで見ないことです。実際の業務では、モデルの前にデータ収集や前処理があり、モデルの後にはアプリケーションへの組み込み、利用状況の監視、予測結果の評価、問題が起きたときの切り戻しがあります。つまりMLOpsは、機械学習のアルゴリズムそのものというより、機械学習を業務で使い続けるための運用設計です。
たとえば、需要予測モデルを作ったとします。学習時点では高い精度が出ていても、季節、流行、価格、在庫、販売チャネルが変われば、予測の外れ方も変わります。入力データの形式が少し変わるだけで、モデルが期待どおりに動かなくなることもあります。このような変化に気づき、原因を調べ、必要なら再学習し、問題のあるモデルを本番から戻せるようにするのがMLOpsの役割です。
近年は、予測モデルだけでなく、画像認識、異常検知、レコメンド、生成AIを使った社内検索や問い合わせ分類でも同じ課題が起こります。PoCでは便利に見えたAIが、本番では精度、速度、費用、権限管理、監査、利用者からのフィードバックに対応できず止まることがあります。MLOpsは、そのギャップを埋めるための共通言語でもあります。
MLOpsが必要になる背景
機械学習プロジェクトは、通常のソフトウェア開発と似ている部分もありますが、決定的に違う点があります。通常のプログラムは、主に人が書いたコードによって動きます。一方、機械学習モデルはコードだけでなく、学習に使ったデータ、特徴量の作り方、学習条件、評価指標、利用時の入力分布に強く影響されます。コードが変わらなくても、データが変われば結果が変わるのです。
この性質があるため、機械学習の運用では「一度リリースしたら終わり」という考え方が合いません。新しい顧客層が増えた、商品の構成が変わった、外部環境が変化した、センサーの仕様が変わった、データ入力のルールが変わったといった出来事が、モデルの性能低下につながります。MLOpsでは、このような変化を前提にして、モデルの状態を継続的に観察します。
特に問題になりやすいのが、PoCと本番運用の差です。PoCでは、限られたデータを使い、分析者が手元の環境でモデルを試します。ここでは精度検証が中心になり、運用監視や障害対応は後回しになりがちです。しかし本番では、決まった時刻にデータが届くか、欠損値が増えていないか、モデルの出力が利用者の意思決定にどう影響しているか、異常時に誰が対応するかまで決める必要があります。
MLOpsが必要になる理由は、AIの価値が「モデルを作った瞬間」ではなく「利用者が継続的に信頼して使える状態」で生まれるからです。高精度のモデルでも、再現できない、説明できない、戻せない、監視できない状態では、業務上のリスクになります。反対に、最初のモデルが完璧でなくても、改善の仕組みが整っていれば、実データを見ながら段階的に価値を高められます。

初心者が最初に押さえるべきポイントは、MLOpsを単なる自動化ツールの名前だと思わないことです。ツールは重要ですが、MLOpsの本体は、データ、モデル、システム、担当者、意思決定をつなぐ運用の考え方です。ツールだけを導入しても、どの指標を監視するのか、誰が承認するのか、精度低下時にどう対応するのかが決まっていなければ、MLOpsは機能しません。
MLOpsの基本構造
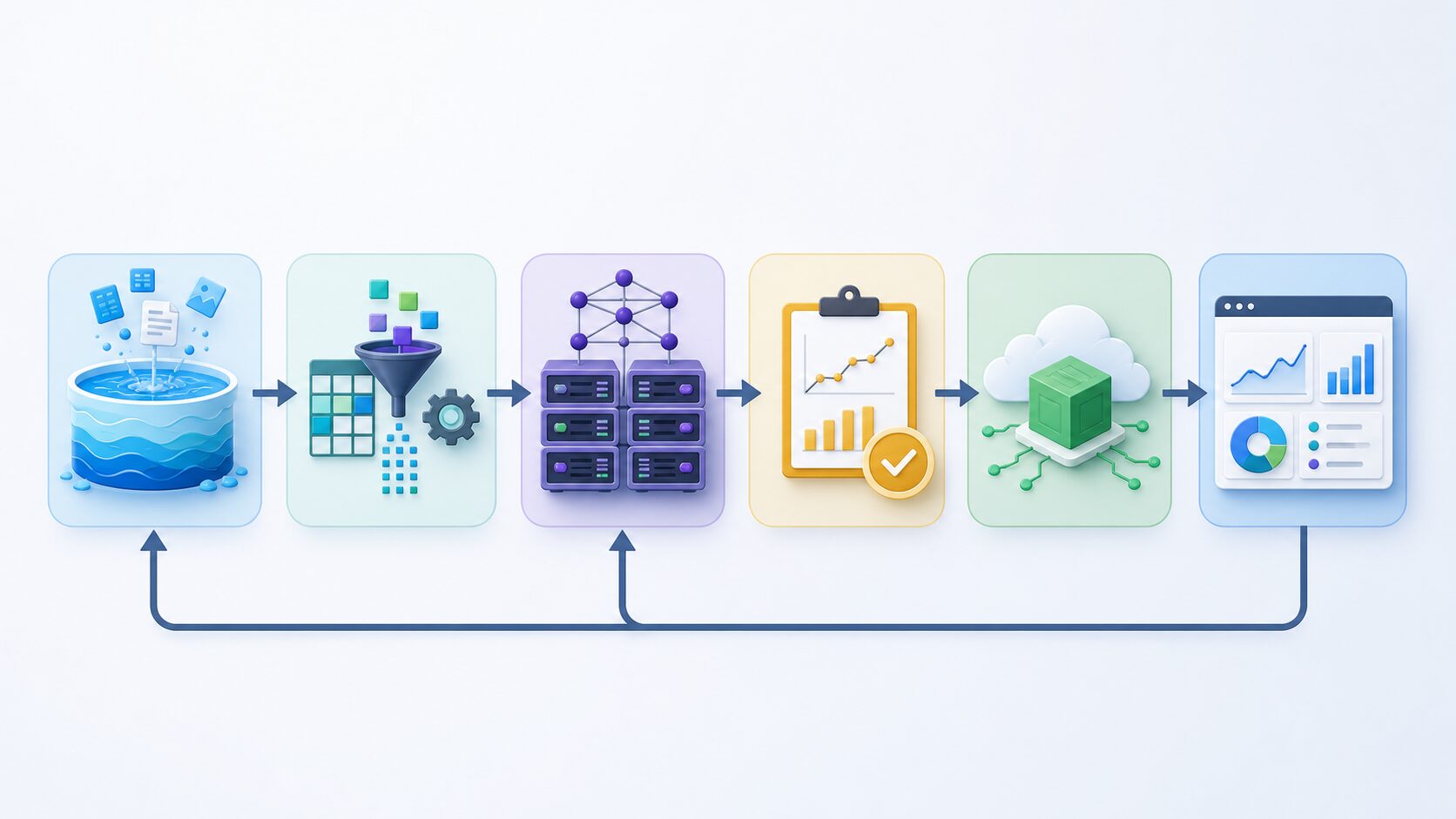
MLOpsの基本構造は、大きく分けると「データを整える」「モデルを作る」「モデルを評価する」「本番へ配備する」「状態を監視する」「必要に応じて改善する」という流れです。これらは一方向の作業ではなく、何度も回るループとして考えます。モデルの性能が落ちたら、監視結果をもとにデータや特徴量を見直し、再学習や再評価につなげます。
最初の要素はデータ管理です。どのデータを、いつ、どの条件で取得し、どのように前処理したのかを記録します。機械学習では、同じコードでも学習データが違えば別のモデルになります。そのため、データのバージョンや加工手順を管理できないと、後から「なぜこの結果になったのか」を追えません。MLOpsでは、データの品質チェック、欠損や外れ値の検出、権限管理も重要な対象になります。
次に、実験管理があります。モデル開発では、アルゴリズム、ハイパーパラメータ、特徴量、学習期間、評価指標を変えながら試行錯誤します。どの実験がどの条件で行われ、どのモデルが採用されたのかを記録することで、再現性が生まれます。再現性がないモデルは、トラブル時に原因を調べにくく、チームで改善することも難しくなります。
評価と承認も欠かせません。精度が高いかどうかだけでなく、推論速度、費用、説明可能性、公平性、業務ルールとの整合性、異常入力への強さを確認します。たとえば不正検知では、見逃しを減らすことが重要ですが、誤検知が多すぎると現場の確認コストが増えます。MLOpsでは、モデルの良し悪しを単一の数値だけで決めず、業務目的に沿った複数の観点で評価します。
配備では、学習済みモデルをアプリケーションやバッチ処理、API、エッジ端末などに組み込みます。このとき、いきなり全利用者に新モデルを出すのではなく、一部の環境で試す、旧モデルと並行して比較する、問題があれば戻すといった方法が使われます。MLOpsでは、モデルのリリースもソフトウェアのリリースと同じように管理することが重要です。
最後に、監視と改善があります。モデルが本番に出た後は、入力データの分布、出力結果の傾向、応答時間、エラー率、業務指標への影響を見ます。正解データが後から得られる場合は、実際の精度も追跡します。正解がすぐ得られない場合でも、入力の変化や出力の偏りを手がかりに異常を検知します。こうした監視結果を次の学習や運用改善に戻すことで、MLOpsのループが成立します。
DevOps・DataOps・ModelOpsとの違い
MLOpsとよく比較される言葉にDevOpsがあります。DevOpsは、開発チームと運用チームが連携し、ソフトウェアを素早く安全にリリースするための文化や仕組みです。CI/CD、テスト自動化、インフラのコード化、監視などが代表的な要素です。MLOpsはDevOpsの考え方を機械学習に応用しつつ、データやモデル特有の管理を加えたものと考えると理解しやすいです。
ただし、MLOpsはDevOpsと完全に同じではありません。DevOpsではコードの変更が主な管理対象ですが、MLOpsではデータ、特徴量、学習済みモデル、評価結果も管理対象になります。さらに、本番でモデルの性能が時間とともに変わるという問題があります。プログラムのコードが同じでも、世の中のデータが変わることで予測精度が落ちるため、MLOpsではモデルドリフトやデータドリフトへの対応が重要になります。
DataOpsは、データパイプラインの信頼性や効率を高める考え方です。データ収集、加工、品質管理、配信、データ利用者との連携に焦点があります。MLOpsはDataOpsと重なる部分が多く、良いMLOpsには良いデータ運用が必要です。学習データが不安定であれば、どれだけ優れたモデル運用基盤を作っても信頼できる結果は得られません。
ModelOpsは、より広い意味でモデル全般の管理やガバナンスを指すことがあります。機械学習モデルだけでなく、統計モデル、ルールベースのスコアリング、リスクモデルなどを対象にする文脈もあります。MLOpsは機械学習モデルの開発から運用までに焦点を当てることが多く、ModelOpsは組織全体でモデルを統制する意味合いが強くなる場合があります。ただし、用語の使われ方は企業や製品によって違うため、実務では「何を対象にしているか」を確認することが大切です。
AIOpsという言葉もありますが、これはIT運用にAIを使う考え方を指すことが一般的です。ログやメトリクスから障害を検知したり、原因分析を支援したりする領域です。名前は似ていますが、MLOpsはAIモデルを運用するための仕組み、AIOpsはIT運用をAIで支援する仕組みという違いがあります。
| 用語 | 主な対象 | 重視すること |
|---|---|---|
| MLOps | 機械学習モデルと周辺のデータ・システム | モデルの配備、監視、再学習、継続改善 |
| DevOps | ソフトウェアとインフラ | 開発と運用の連携、リリースの高速化と安定化 |
| DataOps | データパイプラインとデータ品質 | データの信頼性、加工、配信、利用効率 |
| ModelOps | 組織で使うモデル全般 | モデル管理、承認、統制、リスク管理 |
| AIOps | IT運用のログや監視データ | AIによる障害検知、原因分析、運用支援 |
MLOpsで扱う代表的なパイプライン
MLOpsの実装では、複数のパイプラインを組み合わせます。代表的なのは、データパイプライン、学習パイプライン、評価パイプライン、デプロイパイプライン、監視パイプラインです。これらを一つの巨大な仕組みとして最初から作る必要はありませんが、どの処理がどこで行われ、どの結果が次に渡るのかを明確にする必要があります。
データパイプラインでは、業務システム、ログ、センサー、外部データなどから必要なデータを集め、分析や学習に使える形へ整えます。ここでは、データの欠損、重複、型の不一致、異常値、個人情報の扱いが問題になります。データが毎日更新される場合は、処理が成功したか、件数が急に減っていないか、過去と比べて分布が大きく変わっていないかを確認します。
特徴量管理も重要です。特徴量とは、モデルが予測に使う入力項目です。顧客の購入回数、直近のアクセス数、商品の価格帯、問い合わせ文の埋め込み表現などが例です。学習時と推論時で特徴量の作り方がずれると、モデルは期待どおりに動きません。そのため、MLOpsでは特徴量の定義を共通化し、再利用できるようにする考え方が使われます。
学習パイプラインでは、データを読み込み、前処理し、モデルを学習し、評価結果を保存します。人が手作業でノートブックを実行するだけでは、再現性や定期実行に限界があります。MLOpsでは、学習条件や成果物を記録し、必要に応じて自動実行できるようにします。ただし、自動で再学習する場合でも、人の承認を挟むべき場面があります。特に金融、医療、人事、重要な業務判断に関わるモデルでは、精度だけで自動更新するのは危険です。
モデルレジストリは、学習済みモデルを管理する場所です。どのモデルが開発中で、どのモデルが検証済みで、どのモデルが本番で使われているのかを管理します。モデルファイルだけでなく、学習データのバージョン、評価指標、作成者、承認者、リリース日時も関連づけることで、後から追跡しやすくなります。
デプロイパイプラインでは、検証済みのモデルを本番環境へ安全に出します。APIとして提供する場合もあれば、夜間バッチに組み込む場合、スマートフォンや工場設備の端末に配布する場合もあります。モデルの配備先によって、監視すべき指標や更新方法は変わります。リアルタイムAPIでは応答時間やエラー率が重要になり、バッチ処理では処理時間や失敗時の再実行が重要になります。
監視パイプラインでは、本番で使われているモデルの状態を観察します。システム監視としては、CPU、メモリ、応答時間、エラー率を見ます。モデル監視としては、入力データの分布、予測結果の分布、信頼度、正解データが得られた後の精度を見ます。業務監視としては、売上、在庫、問い合わせ削減率、作業時間、顧客満足度など、モデルが本来改善したかった指標を見ます。
データドリフトとモデルドリフト
MLOpsを学ぶうえで欠かせない言葉が、データドリフトとモデルドリフトです。データドリフトとは、本番で入力されるデータの分布が、学習時のデータと変わることです。たとえば、ECサイトの購買データで、学習時は既存顧客が中心だったのに、広告施策によって新規顧客が急に増えた場合、入力の傾向が変わります。モデルは過去の傾向を学んでいるため、新しい傾向に弱くなることがあります。
モデルドリフトは、モデルの予測性能が時間とともに低下する現象です。データドリフトが原因になることもありますが、業務ルールや利用者行動の変化、競合環境の変化、季節性の変化なども影響します。不正検知では、不正を行う側が検知ルールを避けるように行動を変えるため、以前は有効だったモデルが効きにくくなることがあります。
ドリフトへの対応では、まず「何が変わったのか」を見つける必要があります。入力の件数、カテゴリの比率、数値の平均や分散、欠損率、予測結果の偏りなどを継続的に見ることで、変化の兆候をつかめます。正解データが得られる領域では、実際の精度も確認します。正解が遅れて得られる場合は、暫定的な代理指標を使うこともあります。
注意したいのは、ドリフトが起きたからといって必ずすぐ再学習すればよいわけではないことです。データ収集の不具合、前処理のバグ、一時的なキャンペーン、外部イベントなど、一時的な変化である可能性もあります。MLOpsでは、アラートを出すだけでなく、原因を調査し、再学習、しきい値変更、特徴量修正、旧モデルへの切り戻しなどの対応を選べるようにします。
MLOpsを導入する手順
MLOpsを導入すると聞くと、大規模な基盤や高度なツールを最初からそろえる必要があるように感じるかもしれません。しかし実務では、いきなり全自動の機械学習基盤を作るより、現在の課題に合わせて小さく始めるほうが成功しやすいです。最初に行うべきことは、どのモデルを、どの業務目的で、どの程度の頻度で使い、どのリスクを避けたいのかを明確にすることです。
第一段階は、再現性の確保です。学習データ、前処理、学習コード、パラメータ、評価結果を残し、同じ条件で同じモデルを作れるようにします。ここが整っていないと、監視や自動化を追加しても根本的な改善にはなりません。まずは、実験ログを残す、モデルファイルにバージョンを付ける、採用モデルの評価結果を保存するところから始められます。
第二段階は、リリースと切り戻しの設計です。新しいモデルを本番へ出すとき、誰が承認するのか、どの環境で検証するのか、問題が起きたら何分以内に戻せるのかを決めます。モデルがAPIとして動いている場合は、旧モデルと新モデルを切り替えられる仕組みが役立ちます。バッチ処理の場合は、処理結果を検証してから業務システムへ反映する流れが必要になることもあります。
第三段階は、監視指標の設計です。システム指標、モデル指標、業務指標を分けて考えると整理しやすくなります。システム指標は、エラー率、処理時間、リソース使用量です。モデル指標は、入力分布、予測分布、精度、信頼度、ドリフトです。業務指標は、売上、在庫削減、問い合わせ対応時間、不正検知率などです。どれか一つだけを見るのではなく、目的に応じて組み合わせます。
第四段階は、チームの責任分担です。MLOpsには、データエンジニア、機械学習エンジニア、アプリケーション開発者、インフラ担当者、業務担当者、セキュリティ担当者が関わることがあります。誰がデータ品質を見るのか、誰がモデル評価を承認するのか、誰が障害対応をするのかが曖昧だと、問題発生時に止まります。MLOpsでは、技術だけでなく運用ルールを明文化することが重要です。
第五段階は、自動化する範囲の見極めです。毎回同じ手順で行うデータチェックやテスト、評価、デプロイは自動化に向いています。一方、業務影響が大きいモデルの本番反映、倫理的な判断、規制対応、顧客説明を伴う変更は、人の確認を残すべきです。MLOpsの目的は人を排除することではなく、人が判断すべき部分と機械に任せる部分を分けることです。

具体例で見るMLOpsの使いどころ
需要予測では、MLOpsの重要性が分かりやすく表れます。過去の売上、曜日、天候、イベント、価格、在庫などを使って需要を予測するモデルを作ったとしても、市場環境は常に変わります。新商品、キャンペーン、物流遅延、気候変動、SNSでの話題化などによって、過去のパターンが通用しにくくなることがあります。MLOpsでは、予測誤差を定期的に確認し、どの商品カテゴリで外れが大きいかを見て、再学習や特徴量の追加につなげます。
広告のクリック率予測でも、モデルの継続運用が必要です。ユーザーの興味、広告クリエイティブ、配信面、季節性は変化します。モデルが古くなると、広告費の配分が不適切になり、費用対効果が落ちます。MLOpsでは、クリック率やコンバージョン率だけでなく、データ取得の遅延、配信システムとの接続、異常な入力値も監視します。
不正検知では、モデルの精度低下が直接的な損失につながることがあります。不正行為は環境に適応して変化するため、過去のパターンだけでは検知できなくなる場合があります。一方で、誤検知が増えると正常な利用者に迷惑がかかります。このような領域では、モデルの更新履歴、判定理由、担当者によるレビュー、しきい値の変更履歴を残すことが大切です。
生成AIを使った社内検索や問い合わせ分類でもMLOpsの考え方は役立ちます。たとえば社内文書を検索して回答を生成する仕組みでは、文書の更新、検索品質、回答の正確性、利用者のフィードバック、コスト、アクセス権限を継続的に管理する必要があります。生成AIではモデルそのものを再学習しないケースもありますが、プロンプト、検索インデックス、評価データ、ガードレールを管理する点でMLOpsに近い運用が求められます。
MLOpsで失敗しやすい注意点
MLOpsでよくある失敗は、ツール導入が目的化することです。高機能な基盤を導入しても、対象モデルが少ない、運用ルールが決まっていない、監視指標が業務目的と合っていない場合、現場では使われません。最初は、困っている作業を具体的に洗い出すことが大切です。たとえば「モデルの再現ができない」「本番で精度低下に気づけない」「誰が承認したモデルか分からない」といった課題から逆算します。
二つ目の注意点は、精度だけを見てしまうことです。機械学習では評価指標が重要ですが、実務では精度以外の制約もあります。応答時間が遅すぎるモデルは使いにくく、説明できないモデルは規制や社内ルールに合わない場合があります。学習や推論にかかる費用が高すぎれば、業務上の効果を上回ってしまうかもしれません。MLOpsでは、技術指標と業務指標を一緒に見る必要があります。
三つ目は、データ品質を軽視することです。モデルの性能はデータに強く依存します。入力データの欠損、重複、単位の違い、集計タイミングのずれ、ラベルの誤りがあると、モデルの改善以前に結果が不安定になります。MLOpsを進めるなら、モデル管理だけでなく、データの発生源、加工ルール、品質チェックも対象に含めるべきです。
四つ目は、責任分担の曖昧さです。モデルが誤った予測を出したとき、データ担当者、機械学習担当者、アプリ担当者、業務担当者の誰がどこまで調べるのかが決まっていないと、対応が遅れます。特にAIは複数の専門領域をまたぐため、障害の原因がデータなのか、モデルなのか、アプリケーションなのか、業務ルールなのかを切り分ける体制が必要です。
五つ目は、セキュリティと権限管理の不足です。学習データには個人情報や機密情報が含まれることがあります。モデルや特徴量から情報が漏れる可能性もあります。生成AIを使う場合は、入力プロンプトや検索対象文書の権限管理も重要です。MLOpsでは、誰がどのデータにアクセスできるのか、どのモデルを本番へ出せるのか、操作ログをどう残すのかを設計します。
六つ目は、過剰な自動化です。自動再学習や自動デプロイは便利ですが、業務影響が大きいモデルでは危険になることがあります。たとえば、ある期間だけ偏ったデータが入った場合、そのデータで自動再学習してしまうと、モデルが悪化する可能性があります。重要な判断に関わるモデルでは、評価結果を人が確認し、必要なら段階的にリリースする仕組みが必要です。
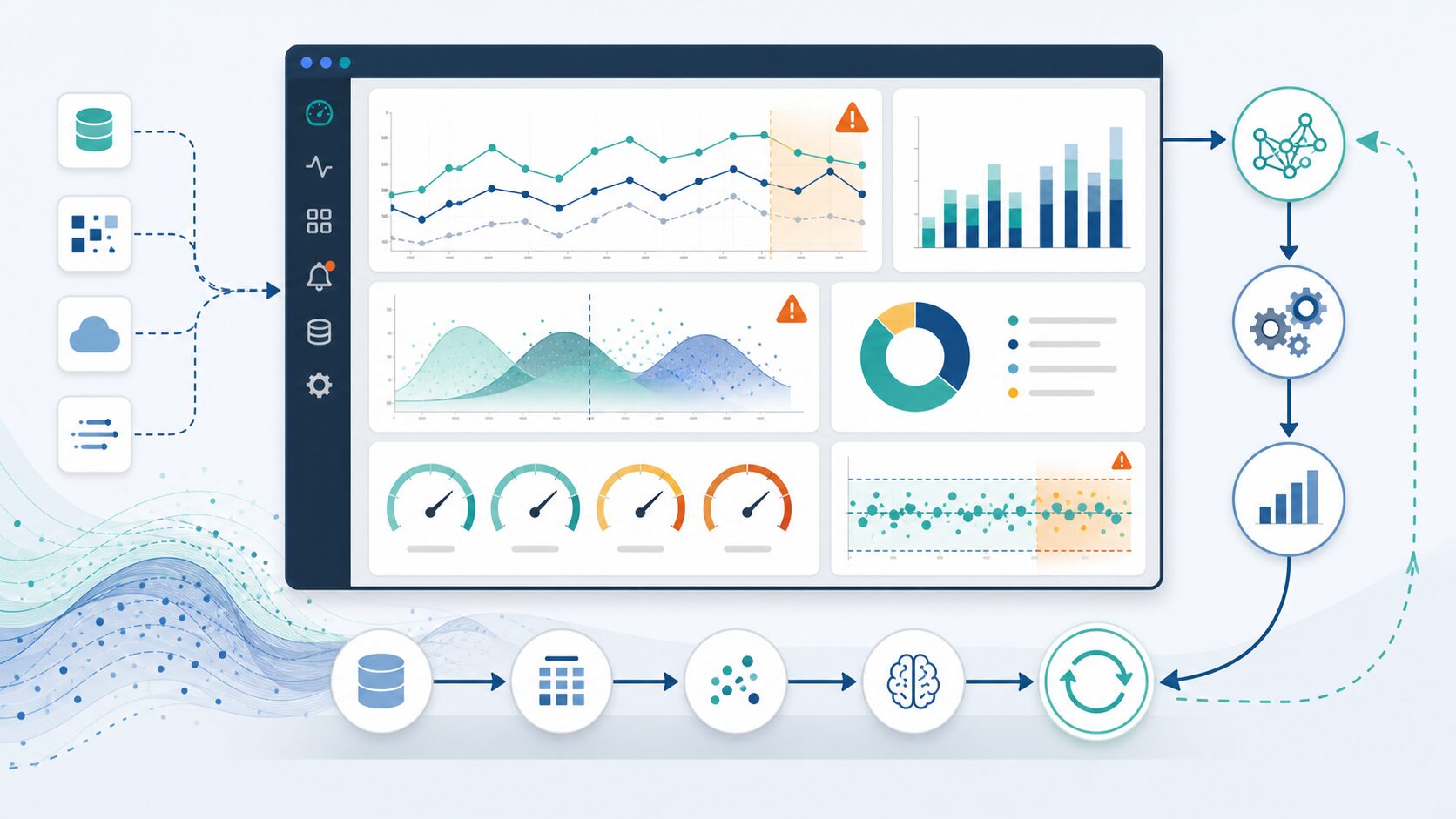
MLOpsでよく使われる構成要素
MLOpsの具体的な構成要素は組織やシステムによって異なりますが、基本的な部品は共通しています。まず、ソースコード管理があります。学習コード、前処理コード、推論コード、設定ファイルをバージョン管理することで、変更履歴を追えるようにします。次に、データや特徴量の管理があります。データの取得元、加工手順、利用条件を記録し、学習時と本番時のずれを減らします。
実験管理では、学習条件と評価結果を記録します。どの実験が採用されたか、なぜ採用されたかを残すことで、後から判断を説明できます。モデルレジストリでは、学習済みモデルを登録し、開発中、検証済み、本番利用中といった状態を管理します。CI/CDでは、コードや設定が変更されたときにテストや評価を実行し、問題がなければ次の環境へ進めます。
監視基盤では、システムの健康状態とモデルの健康状態を見ます。通常のアプリケーション監視に加えて、入力データや予測結果の変化を見る点がMLOpsらしい部分です。さらに、フィードバック収集も重要です。利用者からの修正、業務担当者のレビュー、正解ラベルの追加が、次のモデル改善につながります。
| 構成要素 | 役割 | 初心者が確認したい点 |
|---|---|---|
| コード管理 | 学習や推論の処理を履歴管理する | 誰が何を変えたか追えるか |
| データ管理 | 学習データや前処理を再現可能にする | 同じデータを再取得できるか |
| 実験管理 | 学習条件と評価結果を記録する | 採用モデルの根拠を説明できるか |
| モデルレジストリ | モデルの状態とバージョンを管理する | 本番で使うモデルが明確か |
| CI/CD | テスト、評価、配備を安定化する | 変更時の確認手順が決まっているか |
| 監視 | 性能低下や異常を検知する | 何を見れば問題に気づけるか |
初心者がMLOpsを学ぶ順番
初心者がMLOpsを学ぶなら、最初からすべての専門用語やツールを覚える必要はありません。まずは、機械学習モデルがどのように作られ、どのように使われるかを一連の流れとして理解します。データを集め、前処理し、学習し、評価し、アプリケーションへ組み込み、結果を監視するという流れを押さえるだけでも、MLOpsの全体像が見えやすくなります。
次に、再現性の考え方を学ぶとよいでしょう。学習データ、コード、パラメータ、評価結果が残っていれば、モデルの改善や原因調査がしやすくなります。逆に、手元のノートブックで偶然できたモデルをそのまま使っていると、後で同じ結果を作れず困ります。MLOpsの多くの仕組みは、この再現性を高めるためにあります。
その次に、監視とドリフトを学びます。モデルは本番に出してからも状態が変わります。入力データが変わる、利用者が変わる、外部環境が変わると、モデルの振る舞いも変わります。MLOpsでは、モデルを「完成品」ではなく「管理し続ける対象」として見ることが大切です。
最後に、組織や業務との接続を学びます。AIモデルは単独で価値を出すのではなく、業務プロセスや利用者の意思決定の中で価値を出します。どの指標を改善したいのか、誤った予測が出たときにどんな影響があるのか、誰が最終判断をするのかを考えることで、MLOpsは単なる技術基盤ではなく、AI活用の運用設計として理解できます。
MLOpsは小さく始めるのが現実的
MLOpsという言葉には大きな仕組みを連想しやすい響きがありますが、実際には小さな改善から始められます。たとえば、学習済みモデルのファイル名を日付だけで管理しているなら、モデルのバージョン、学習データ、評価結果を記録するだけでも前進です。手作業で本番へ反映しているなら、チェックリストを作り、承認者と切り戻し手順を決めるだけでもリスクは下がります。
監視も、最初から高度なダッシュボードを作る必要はありません。入力件数、欠損率、予測結果の分布、エラー率、処理時間など、基本的な指標を定期的に確認するところから始められます。正解データが後から得られるなら、週次や月次で精度を確認するだけでも、モデルの劣化に気づきやすくなります。
小さく始めるときのコツは、最も困っている一点を選ぶことです。再現性が課題なら実験管理から、リリース事故が課題ならデプロイ手順から、精度低下に気づけないなら監視から始めます。すべてを同時に整えようとすると、基盤づくりに時間がかかり、肝心の業務価値が見えにくくなります。
また、MLOpsは一度作って終わるものではありません。モデルの数、利用者、リスク、組織体制が変わるにつれて、必要な仕組みも変わります。最初は簡単な記録と手動承認で十分だったものが、モデル数の増加に伴って自動テストやモデルレジストリを必要とすることもあります。段階的に育てる前提で設計することが現実的です。
まとめ
MLOpsとは、機械学習モデルを業務で継続的に使うために、開発、評価、配備、監視、再学習、改善をつなぐ考え方です。単にモデルを作る技術ではなく、モデルが本番環境で信頼できる状態を保つための運用設計だと捉えると分かりやすくなります。
機械学習モデルは、コードだけでなくデータや環境の変化に影響されます。そのため、PoCで高い精度が出たとしても、本番で同じように価値を出し続けられるとは限りません。MLOpsでは、データ管理、実験管理、モデルレジストリ、CI/CD、監視、フィードバックを組み合わせ、変化に対応できる仕組みを作ります。
初心者は、MLOpsを難しいツール群として覚えるより、まず「AIを作って終わりにしないための考え方」として理解するとよいでしょう。再現できること、監視できること、問題が起きたら戻せること、改善の判断ができること。この四つを意識するだけでも、MLOpsの核心に近づけます。
実務でMLOpsを始めるなら、最初から大規模な自動化を目指す必要はありません。対象モデルの目的とリスクを整理し、学習条件と評価結果を記録し、リリース手順と監視指標を決めるところから始めます。MLOpsの価値は、AIモデルを一度動かすことではなく、変化する現場の中で継続的に信頼して使える状態を作ることにあります。
更新履歴
| 日付 | 内容 |
|---|---|
| 2026年5月27日 | 初回公開 |