ドロップアウトで過学習を防ぐ

AIの初心者
先生、「ドロップアウト」ってよく聞くんですけど、どんなものなんですか?

AI専門家
簡単に言うと、人工知能の学習中に、一部の神経細胞をわざと休ませる仕組みだよ。人間も、色々なことを勉強する時に、一度に全部覚えようとすると混乱してしまうよね?ドロップアウトは、一部を休ませることで、全体としてバランス良く学習させる効果があるんだ。
AIの初心者
なるほど。でも、休ませちゃったら、その分学習が遅くなるんじゃないですか?
AI専門家
一見そう思うよね。でも、全部を一度に学習させようとすると、偏りが出てきて、うまく学習できないことがあるんだ。一部を休ませることで、かえって全体としてバランス良く学習が進み、最終的にはより良い結果につながることが多いんだよ。
ドロップアウトとは。
人工知能の学習方法の一つに、『間引き』という用語があります。これは、人工知能の脳みそにあたる神経回路網を学習させる際に、その中の神経細胞の一部をわざと休ませる手法のことです。どの神経細胞を休ませるかは、学習の都度、ランダムに選びます。人工知能はたくさんの調整つまみを備えているため、学習用のデータに過剰に適応してしまい、新しいデータではうまく働かなくなるという問題が起こりがりがちです。この『間引き』という手法を使うことで、この問題をある程度抑えることができます。
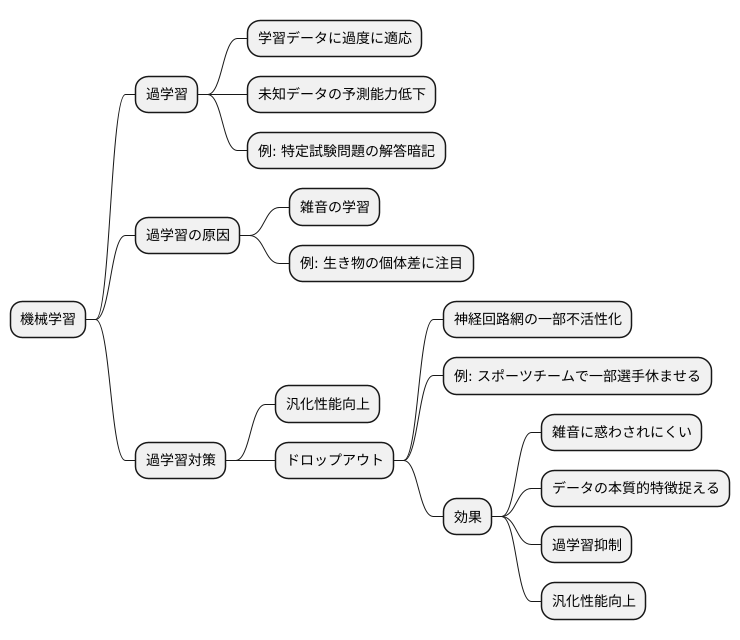
過学習への対策

機械学習の分野では、学習に使ったデータへの適合具合を非常に重視します。学習データに過度に適応してしまうと、未知のデータに対する予測能力が低下する「過学習」という問題が生じます。これは、まるで特定の試験問題の解答だけを暗記した生徒が、似たような問題が出題されると良い点数が取れるものの、全く異なる形式の問題には対応できないのと同じです。
過学習は、モデルが学習データの細かい特徴や例外的な部分、いわゆる「雑音」までをも学習してしまうことで起こります。本来ならば、データ全体に共通する本質的な規則やパターンを学習すべきなのですが、雑音に惑わされてしまうのです。例えるなら、ある生き物の特徴を学ぶ際に、本来は耳や鼻、口といった主要な器官に着目すべきなのに、皮膚のちょっとした模様や傷跡といった個体差にばかり注目してしまうようなものです。このような学習では、その生き物全体の特徴を正しく捉えることはできません。
この過学習を防ぎ、未知のデータに対しても高い予測性能を発揮できるよう、モデルの汎化性能を高める様々な対策がとられています。その有効な手段の一つが「ドロップアウト」です。ドロップアウトは、学習の過程で、神経回路網の一部を意図的に働かなくする技術です。これは、スポーツチームで一部の選手を練習試合に参加させないようにして、残りの選手だけで試合をさせるようなものです。休ませた選手は試合には出られませんが、他の選手は普段よりも多くの役割を担うことになり、個々の能力が向上します。そして、試合に出るメンバーを毎回変えることで、チーム全体の層も厚くなり、様々な状況に対応できるようになります。
ドロップアウトもこれと同様に、特定の神経回路を不活性化することで、他の回路がより活発に働くようになり、学習データの雑音に惑わされにくくなります。結果として、モデルはデータの本質的な特徴を捉える能力を高め、過学習を抑制し、汎化性能を向上させることができるのです。
ドロップアウトの仕組み

ドロップアウトとは、人工知能の学習方法の一つで、過学習を防ぐための効果的な技術です。過学習とは、訓練データにあまりにも適応しすぎてしまい、新しいデータに対する予測能力が低下してしまう現象です。ドロップアウトは、この過学習を抑え、未知のデータに対しても高い性能を発揮できるようにするために用いられます。
ドロップアウトの仕組みは、神経細胞の一部をランダムに休ませることにあります。人間の脳にはたくさんの神経細胞がありますが、すべての細胞が常に活動しているわけではありません。ある時は一部の細胞が休み、別の時は別の細胞が休むというように、状況に応じて活動する細胞が変化しています。ドロップアウトはこの仕組みにヒントを得ています。
具体的には、学習の各段階において、一定の確率でランダムに神経細胞を選び、その活動を一時的に停止させます。停止した神経細胞は、その段階の計算には一切関与しません。まるでネットワークから切り離されたかのように扱われます。そして、次の学習段階では、また別の神経細胞がランダムに選ばれ、停止します。つまり、どの神経細胞が停止するかは、毎回変化するということです。
このように、神経細胞をランダムに休ませることで、特定の神経細胞への依存を避けることができます。特定の細胞に過度に頼ってしまうと、その細胞が学習データの癖やノイズを覚えてしまい、過学習につながる可能性があります。ドロップアウトは、特定の細胞への依存を避けることで、ネットワーク全体がバランスよく学習し、より汎用的な表現を獲得することを促します。これは、様々なデータに柔軟に対応できる、頑健なモデルの構築につながります。
ドロップアウトは、画像認識や自然言語処理など、様々な分野で広く利用されています。その効果は高く評価されており、過学習を防ぐための重要な技術として、人工知能の分野で欠かせないものとなっています。
| ドロップアウト | 人工知能の学習方法の一つで、過学習を防ぐための技術 |
|---|---|
| 過学習 | 訓練データに過剰適応し、新しいデータへの予測能力が低下する現象 |
| ドロップアウトの仕組み | 神経細胞の一部をランダムに休ませる |
| 学習の各段階 | 一定確率でランダムに神経細胞を選び、活動を一時的に停止 |
| 効果 | 特定の神経細胞への依存を避け、ネットワーク全体がバランスよく学習し、汎用的な表現を獲得。頑健なモデル構築につながる |
| 利用分野 | 画像認識、自然言語処理など |
ドロップアウトの効果

ドロップアウトは、複数の異なるモデルを組み合わせる学習方法であるアンサンブル学習とよく似た働きをします。アンサンブル学習では、複数の学習済みモデルの予測結果を統合することで、より精度の高い予測を実現します。ドロップアウトも同様に、多数の仮想的なモデルを生成し、それらをまとめて扱うことで高い効果を発揮します。ドロップアウトは、学習の過程で、神経回路網の一部をランダムに選び、一時的に働かなくします。これはまるで、神経回路網の構成要素を抜き差しすることで、毎回少しずつ異なる形の回路網を作り出しているようなものです。
回路網の一部を働かなくすることで、学習のたびに異なる回路網が用いられることになります。一つのまとまったデータのかたまりを処理するたびに、構成要素の組み合わせが変わるため、事実上、様々な回路網で学習が行われていることになります。最終的に得られる学習済みモデルは、これらの多様な回路網の集合体と見なすことができます。まるで、複数の専門家の意見を総合して、より確かな判断を下すように、ドロップアウトも複数の仮想的な回路網を活用することで、一つの回路網だけでは学習できない、様々な特徴を捉えることができます。
このように、複数の異なる視点から学習を行うことで、モデルは特定の特徴に過度に依存することを防ぎ、より頑健で、偏りの少ない予測を生成できるようになります。特定の要素が欠けても、他の要素で補うことができるため、未知のデータに対しても安定した性能を発揮することが期待できます。ドロップアウトは、まるで様々な経験を積んだ熟練者のように、様々な状況に対応できる柔軟性をモデルに与えるのです。これにより、データに含まれるノイズや偏りの影響を受けにくくなり、より汎用性の高いモデルが構築できます。
| ドロップアウトの仕組み | 効果 |
|---|---|
| 学習中に神経回路網の一部をランダムに無効化し、毎回異なる仮想的な回路網を生成 | 様々な特徴を捉え、一つの回路網だけでは学習できない情報を学習 |
| 複数の仮想的な回路網で学習 | 特定の特徴への過度な依存を防ぎ、頑健で偏りの少ない予測を生成 |
| 要素の一部が欠けても他の要素で補完可能 | 未知のデータに対しても安定した性能、様々な状況に対応できる柔軟性 |
ドロップアウトの適用範囲

多くの層が積み重なった複雑な学習模型や、情報量のとても多い資料を扱う場合、模型が学習資料の特徴を捉えすぎる「過学習」という問題がよく起こります。この過学習を防ぐための有効な手段の一つとして、「ドロップアウト」という手法があります。ドロップアウトは、学習の過程で、神経細胞の一部を意図的に働かなくすることで、模型の汎化性能を高める技術です。
ドロップアウトは、画像を内容で分類する画像認識や、文章の意味を理解する自然言語処理、音声を文字に変換する音声認識など、様々な分野の学習模型に広く使われています。特に、層の数が多い巨大な模型や、扱う資料が複雑な場合に効果を発揮します。ドロップアウトを適用することで、過学習を抑え、模型の精度を高め、より確かな結果を得られることが期待できます。また、学習の過程を安定させ、結果のばらつきを抑える効果もあります。
ドロップアウトを適用する際に重要なのは、どの程度の割合で神経細胞を働かなくするかを決めることです。これは「ドロップアウト率」と呼ばれ、一般的には0.1から0.5の間の値が用いられます。しかし、最適なドロップアウト率は扱う資料や模型の構造によって異なるため、実際に様々な値を試して、最も良い結果が得られる値を探す必要があります。適切なドロップアウト率を設定することで、模型の性能を最大限に引き出すことができます。
ドロップアウトは強力な手法ですが、万能ではありません。常に効果があるとは限らず、場合によっては効果がないこともあります。そのため、他の手法と組み合わせたり、様々な設定を試したりしながら、最適な学習方法を探ることが重要です。
| 項目 | 内容 |
|---|---|
| ドロップアウトとは | 学習中に神経細胞の一部を無効化し、過学習を防ぎ汎化性能を高める手法 |
| 用途 | 画像認識、自然言語処理、音声認識など様々な分野。特に層が多い巨大なモデルや複雑なデータに有効。 |
| 効果 | 過学習抑制、モデル精度向上、結果のばらつき抑制 |
| ドロップアウト率 | 無効化する神経細胞の割合。一般的に0.1〜0.5。データやモデル構造により最適値は異なるため、様々な値を試す必要がある。 |
| 注意点 | 万能ではなく、効果がない場合もある。他の手法との組み合わせや様々な設定を試すことが重要。 |
ドロップアウト率

学習をより深く行うための技術の一つに、一部の神経細胞を意図的に休ませる手法があります。この手法は、まるで学校を時々休むことで、より良い学習効果が得られることと似ています。この休ませる割合のことを「落とす割合」と呼びます。この割合は、通常0.1から0.5の間で設定されます。
この「落とす割合」の設定が学習に大きな影響を与えます。例えば、この割合を高く設定すると、多くの神経細胞が休むことになります。これは、学習内容を単純化し、覚えすぎることを防ぐ効果があります。しかし、高すぎると、学習が足りなくなり、重要な情報も覚えられない可能性があります。逆に、この割合を低く設定すると、ほとんどの神経細胞が働き続けることになります。これは、詳細な情報まで覚えることができますが、特定の問題に特化しすぎて、新しい問題に対応できない、いわゆる「覚えすぎ」の状態になる可能性があります。
最適な「落とす割合」は、扱う問題やデータの性質によって変化します。そのため、試行錯誤を通じて最適な値を見つける必要があります。例えば、様々な割合を試してみて、最も良い結果が得られる割合を採用する方法があります。一般的には、0.5付近から始めて、学習の結果を見ながら少しずつ調整していくのが良いでしょう。ちょうど、学校の休み時間を調整するように、神経細胞の休み時間も調整することで、より効果的な学習を実現できます。
| 落とす割合 | 効果 | デメリット |
|---|---|---|
| 高(0.5に近い) | 学習内容の単純化、覚えすぎ防止 | 学習不足、重要な情報も覚えられない可能性 |
| 低(0.1に近い) | 詳細な情報まで記憶可能 | 特定の問題に特化しすぎ、新しい問題に対応できない可能性(覚えすぎ) |
実装上の注意点

学習の段階においてのみ、一部の結びつきを意図的に途切れさせる手法である「落とす学習」について、正しく利用するためにいくつか注意すべき点があります。まず、この手法は学習中にだけ使い、予測をするときには使いません。予測を行う際には、全ての結びつきを使って計算を行います。
次に、「落とす学習」を使うと、学習時の小さなデータのまとまりごとの出力の大きさが変わってきます。そのため、予測時には出力の大きさを調整する必要があります。具体的には、学習時に使った「落とす割合」をかけることで、出力の大きさを調整します。
さらに、この手法の効果を最大限に引き出すためには、どの結びつきを落とすかも重要です。一般的には、それぞれの結びつきを落とすかどうかを確率的に決めます。また、どの層に適用するか、どの程度の割合で落とすかなど、様々な設定が可能です。これらの設定は、扱う問題やデータの性質に合わせて適切に調整する必要があります。
調整の方法としては、一般的に「交差検証」と呼ばれる手法を用います。これは、データをいくつかのグループに分け、それぞれのグループで学習と評価を繰り返すことで、最適な設定を見つける方法です。
これらの点に気を付けて「落とす学習」を使えば、過学習を抑え、より良い予測モデルを作ることができるでしょう。過学習とは、学習データに過度に適応しすぎてしまい、未知のデータに対してうまく予測できない状態のことです。「落とす学習」は、結びつきをランダムに途切れさせることで、モデルが特定の学習データに過度に依存することを防ぎ、汎化性能を高めます。つまり、未知のデータに対しても高い予測精度を達成できるようになります。
| 項目 | 内容 |
|---|---|
| 手法名 | 落とす学習 |
| 適用段階 | 学習時のみ(予測時には使用しない) |
| 予測時の出力調整 | 学習時に使用した「落とす割合」をかける |
| 結びつきの選択 | 確率的に決定 |
| 設定 | どの層に適用するか、落とす割合 など |
| 調整方法 | 交差検証 |
| 効果 | 過学習の抑制、予測精度の向上 |
| 過学習抑制のメカニズム | 結びつきをランダムに途切れさせることで、特定の学習データへの過度な依存を防ぐ |